


阿里云开发者社区






























综合
最新
有奖励
免费用
2025阿里云PolarDB开发者大会来了!
在数字化浪潮中,AI与数据库的融合正重塑行业格局。2025年2月26日(周三),诚邀您在北京朝阳区嘉瑞文化中心参会,探讨数据技术发展与AI时代的无限可能。线上直播同步进行,欢迎参与!

PAI Model Gallery 支持云上一键部署 DeepSeek-V3、DeepSeek-R1 系列模型
DeepSeek 系列模型以其卓越性能在全球范围内备受瞩目,多次评测中表现优异,性能接近甚至超越国际顶尖闭源模型(如OpenAI的GPT-4、Claude-3.5-Sonnet等)。企业用户和开发者可
别再熬夜调模型——从构想到落地,我们都管了!
本文将以 Qwen2.5 : 7B 为例进行演示,介绍如何通过人工智能平台 PAI实现AI 研发的全链路支持,覆盖了从数据标注、模型开发、训练、评估、部署和运维管控的整个AI研发生命周期。
摊牌了,代码不是我自己写的
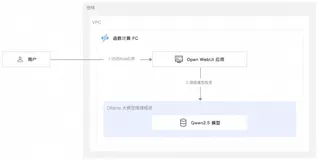
本文介绍了如何使用阿里云函数计算FC部署Qwen2.5开源大模型。Qwen2.5支持128K上下文长度和92种编程语言,通过Ollama托管和Open WebUI交互界面实现快速部署与高效调用。函数计
Lindorm作为AI搜索基础设施,助力Kimi智能助手升级搜索体验
月之暗面旗下的Kimi智能助手在PC网页、手机APP、小程序等全平台的月度活跃用户已超过3600万。Kimi发布一年多以来不断进化,在搜索场景推出的探索版引入了搜索意图增强、信源分析和链式思考等三大推

阿里云百炼xWaytoAGI共学课DAY3 - 更热门的多模态交互案例带练,实操掌握AI应用开发
本文章旨在帮助读者了解并掌握大模型多模态技术的实际应用,特别是如何构建基于多模态的实用场景。文档通过几个具体的多模态应用场景,如拍立淘、探一下和诗歌相机,展示了这些技术在日常生活中的应用潜力。
云原生应用网关进阶:阿里云网络ALB Ingress 全能增强
在过去半年,ALB Ingress Controller推出了多项高级特性,包括支持AScript自定义脚本、慢启动、连接优雅中断等功能,增强了产品的灵活性和用户体验。此外,还推出了ingress2A
云资源运维难?阿里云免费工具来帮忙
阿里云推出免费运维工具——云服务诊断,帮助用户提升对云资源的运维效率、降低门槛、减轻负担。其核心功能包括「健康状态」和「诊断」。通过「健康状态」可实时查看云资源是否正常;「诊断」功能则能快速排查网络、
从大数据到大模型:如何做到“心无桎梏,身无藩篱”
在大数据和大模型的加持下,现代数据技术释放了巨大的技术红利,通过多种数据范式解除了数据的桎梏,使得应用程序达到了“心无桎梏,身无藩篱”的自在境界,那么现代应用有哪些数据范式呢?这正是本文尝试回答的问题
基于阿里百炼的DeepSeek-R1满血版模型调用【零门槛保姆级2084小游戏开发实战】
本文介绍基于阿里百炼的DeepSeek-R1满血版模型调用,提供零门槛保姆级2048小游戏开发实战。文章分为三部分:定位与核心优势、实战部署操作指南、辅助实战开发。通过详细步骤和案例展示,帮助开发者高
DeepSeek个人站点一键部署流程演示

怎么让一张流程表单提交后,自动将这张表单的数据填入另一张流程表单并提交?
最开始是想要实现创建订单后自动生成生产工单的功能。想要创建一张带有好几个产品的订单后自动生成几个产品对应的几张不同的工单后面发现好像不好实现。现在把功能改为创建1个产品订单后能自动生成产品对应的工单
人人懂AI之从机器学习到大模型
本书面向广大IT从业者,作者将尽可能通俗易懂的把机器学习、深度学习、神经网络等基本原理讲解清楚,并分享大语言模型、知识库等当下很火爆的AIGC应用,探讨大语言模型“知识茧房”问题及解法。期望本书能成为


Flink CDC任务从savepoint/checkpoints状态中恢复作业错误问题
flink CDC任务监听mysql数据。只要不是从savepoint/checkpoint中恢复都是能成功运行并监听数据的但是只要从savepoint/checkpoint中恢复作业就会报如下错误
Serverless+AI 轻松玩转高频 AIGC 场景
本书旨在整理和介绍函数计算如何构建各类 AI 应用,以及如何基于函数计算结合其他云产品来部署各种 AI 大模型。主要内容包括:【构建个人专属AI助手】【AI生图】、【AI内容创作】、【打造多形态全天候


快速使用 DeepSeek-R1 满血版
DeepSeek是一款基于Transformer架构的先进大语言模型,以其强大的自然语言处理能力和高效的推理速度著称。近年来,DeepSeek不断迭代,从DeepSeek-V2到参数达6710亿的De

用DeepSeek,就在阿里云!四种方式助您快速使用 DeepSeek-R1 满血版!更有内部实战指导!
DeepSeek自发布以来,凭借卓越的技术性能和开源策略迅速吸引了全球关注。DeepSeek-R1作为系列中的佼佼者,在多个基准测试中超越现有顶尖模型,展现了强大的推理能力。然而,由于其爆火及受到黑客
《多语言+多文化,自然语言处理的全球通关秘籍》
在全球化背景下,信息快速流动,多语言交流频繁。自然语言处理(NLP)面临语法、词汇、语义差异及数据获取标注等挑战。为应对这些难题,多语言预训练模型(如XLM-RoBERTa)、迁移学习与零样本学习、融
快速调用 Deepseek API!【超详细教程】
Deepseek 强大的功能,在本教程中,将指导您如何获取 DeepSeek API 密钥,并演示如何使用该密钥调用 DeepSeek API 以进行调试。
本地部署DeepSeek模型技术指南
DeepSeek模型是一种先进的深度学习模型,广泛应用于自然语言处理等领域。本文详细指导如何在本地部署DeepSeek模型,涵盖环境准备(硬件和软件要求、依赖库安装)、模型下载与配置、部署(创建Fla
通义万相2.1视频/图像模型新升级!可在阿里云百炼直接体验
通义万相2.1模型推出新特征,包括复杂人物运动的稳定展现、现实物理规律的逼真还原及中英文视频特效的绚丽呈现。通过自研的高效VAE和DiT架构,增强时空上下文建模能力,支持无限长1080P视频的高效编解
通义万相Wan2.1视频模型开源!视频生成模型新标杆,支持中文字效+高质量视频生成
2025年1月,阿里通义万相Wan2.1模型登顶Vbench榜首第一,超越Sora、HunyuanVideo、Minimax、Luma、Gen3、Pika等国内外视频生成模型。而在今天,万相Wan2.
基于 DIFY 的自动化数据分析实战
本文介绍如何使用DIFY搭建数据分析自动化流程,实现从输入需求到查询数据库、LLM分析再到可视化输出的全流程。基于经典的employees数据集和DIFY云端环境,通过LLM-SQL解析、SQL执行、
👉「免费满血DeepSeek实战-联网搜索×Prompt秘籍|暨6平台横评」
满血 DeepSeek 免费用!支持联网搜索!创作声明:真人攥写-非AI生成,Written-By-Human-Not-By-AI

【保姆级教程]】5分钟用阿里云百炼满血版DeepSeek, 手把手做一个智能体
阿里云推出手把手学AI直播活动,带你体验DeepSeek玩法。通过阿里云百炼控制台,用户可免费开通满血版R1模型,享受100w token免费额度。活动还包括实验步骤、应用开发教程及作业打卡赢好礼环节
deepseek部署的详细步骤和方法,基于Ollama获取顶级推理能力!
DeepSeek基于Ollama部署教程,助你免费获取顶级推理能力。首先访问ollama.com下载并安装适用于macOS、Linux或Windows的Ollama版本。运行Ollama后,在官网搜索
从0到1彻底掌握Trae:手把手带你实战开发AI Chatbot,提升开发效率的必备指南!
Trae是字节跳动推出的一款免费的AI集成的开发环境,集成了Claude3.5与GPT-4o等主流AI模型,提供AI问答、智能代码生成、智能代码补全,多模态输入等功能。支持界面全中文化,为中文开发者提
阿里开源AI视频生成大模型 Wan2.1:14B性能超越Sora、Luma等模型,一键生成复杂运动视频
Wan2.1是阿里云开源的一款AI视频生成大模型,支持文生视频和图生视频任务,具备强大的视觉生成能力,性能超越Sora、Luma等国内外模型。

三分钟让Dify接入Ollama部署的本地大模型!
本文介绍了如何运行 Ollama 并在 Dify 中接入 Ollama 模型。通过命令 `ollama run qwen2:0.5b` 启动 Ollama 服务,访问 `http://localhos
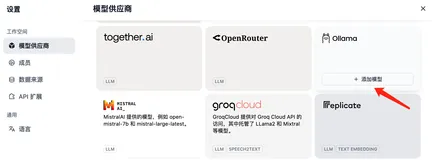
解锁 DeepSeek 安全接入、稳定运行新路径
聚焦于企业部署 DeepSeek 的应用需求,本文介绍了模型权重下载及多种部署方案,还阐述了大模型应用落地的常见需求,帮助用户逐步提升模型应用效果。
如何调用 DeepSeek-R1 API ?图文教程
首先登录 DeepSeek 开放平台,创建并保存 API Key。接着,在 Apifox 中设置环境变量,导入 DeepSeek 提供的 cURL 并配置 Authorization 为 `Beare
一文详解DeepSeek和Qwen2.5-Max混合专家模型(MoE)
自20世纪中叶以来,人工智能(AI)和机器学习(ML)经历了从基于逻辑推理的专家系统到深度学习的深刻转变。早期研究集中在规则系统,依赖明确编码的知识库和逻辑推理。随着计算能力提升和大数据时代的到来,机
轻松集成私有化部署Dify文本生成型应用
Dify 是一款开源的大语言模型应用开发平台,融合了后端即服务(Backend as Service)和 LLMOps 的理念,使开发者能快速搭建生产级生成式 AI 应用。通过阿里云计算巢,用户可以一
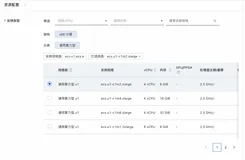
评测|全网最强🚀!5min部署满血版DeepSeek,零成本,无需编程!
本文介绍了阿里云提供的四种DeepSeek部署方案,包括基于百炼调用满血版API、基于函数计算部署、基于人工智能平台PAI部署和GPU云服务器部署。通过这些方案,用户可以摆脱“服务器繁忙”的困扰,实现


Qwen2.5-Max:阿里通义千问超大规模 MoE 模型,使用超过20万亿tokens的预训练数据
Qwen2.5-Max是阿里云推出的超大规模MoE模型,具备强大的语言处理能力、编程辅助和多模态处理功能,支持29种以上语言和高达128K的上下文长度。

20K star!让网页设计秒变手绘风,这个开源库太有创意了!
嗨,大家好,我是小华同学。Rough.js 是一个仅8KB的轻量级图形库,能为网页元素赋予自然的手绘质感,支持手绘风格渲染、全类型图形和跨平台兼容。它适合数据可视化、教育课件、原型设计等场景,具有设计
探究大气生态系统:1996年BOREAS项目中南北研究区SLICER数据详解
BOREAS SLICER(Scanning Lidar Imager of Canopies by Echo Recovery)三级数据旨在支持 boreal 生态系统-大气研究,涵盖1996年7月
04.里式替换原则介绍
里式替换原则(LSP)是面向对象设计的重要原则之一,确保子类可以无缝替换父类而不破坏程序功能。本文详细介绍了LSP的定义、背景、理解方法及应用场景,通过电商支付和鸟类飞行案例展示了如何遵循LSP,并分

阿里云CDN:全球加速网络的实践创新与价值解析
在数字化浪潮下,用户体验成为企业竞争力的核心。阿里云CDN凭借技术创新与全球化布局,提供高效稳定的加速解决方案。其三层优化体系(智能调度、缓存策略、安全防护)确保低延迟和高命中率,覆盖2800+全球节
CLIPer:开创性框架提升CLIP空间表征,实现开放词汇语义分割突破
对比语言-图像预训练(CLIP)在多种图像级任务上表现出强大的零样本分类能力,促使研究行人尝试将CLIP应用于像素级开放词汇语义分割,而无需额外训练。关键在于提升图像级CLIP的空间表征能力,例如,用
课时2:类与对象简介
既然提及了面向对象,那其中有两个极为重要的概念,我们必须率先明晰。要知道,面向对象是一个颇为庞大的话题,然而再庞大的话题也有其核心组成部分,而这核心部分便是类与对象。接下来,我们就针对类与对象展开分析
课时1:面向对象简介
Java的面向对象编程(OOP)是其核心特性之一,强调模块化设计与重用。OOP具有三大特征:封装性、继承性和多态性。封装确保内部操作对外不可见;继承允许在已有类基础上扩展功能;多态支持类型转换和灵活处
课时19:Java运算符(位运算符)
课时19介绍Java中的位运算符,涵盖进制转换、位与、位或及移位操作。重点讲解了二进制与其他进制的转换方法,通过具体范例演示了位与和位或运算的过程,并展示了八进制和十六进制的处理方式。此外,还解释了逻
阿里云安全体检功能评测报告 - 安全菜鸟角度
本文介绍了阿里云安全体检的使用体验及效果。作为一名测试开发工程师,日常工作繁重且加班频繁,曾因忽视环境漏洞造成损失。阿里云的安全体检服务提供了从登录官网、访问控制台到开启和查看体检结果的完整流程,帮助
课时18:Java运算符(逻辑运算符)
课时18介绍了Java中的逻辑运算符(与、或、非)。通过范例详细讲解了非操作的使用,展示了如何正确应用逻辑非(!)。接着分别探讨了与操作(& 和 &&)及或操作(| 和 ||),强调了短路运算符(&&
通义灵码使用过程中报错,idea最新版
com.intellij.openapi.diagnostic.RuntimeExceptionWithAttachments: Read access is allowed from inside
如何使用网站模版建设网站?
本文介绍了如何选择网站模板建站的步骤,包括确定网站类型和目标的重要性、选择模板品牌、网站内容修改和部署测试、以及网站上线后的维护。模板建站的优势包括便捷性和低成本、用户体验高、快速建站和节省成本。
在Hyper-V恢复过程中,要确保备份数据的完整性和可恢复性
在Hyper-V恢复过程中,确保备份数据的完整性和可恢复性至关重要。关键步骤包括:验证备份文件的校验和与完整性,审查日志文件;定期测试恢复,模拟故障场景,检查恢复点和恢复后的性能。最佳实践涵盖:将备份
课时17:Java运算符(关系运算符)
范例:进行关系判断。如果要进行关系运算的操作可使用:>、<、>=、<=、!=(不等于)、==。所有的关系运算符判断完成的数据返回结果都是布尔类型(boolean)。只要使用关系运算符进行逻辑判断,最终
课时16:Java运算符(三目运算符)
范例:将两个变量值在大的内容赋值给新变量。三目是一种赋值运算,它指的是根据条件来进行判断。(根据判断的结果来决定赋值内容)对于三目运算的基本使用语法如下: 数据类型 变量 = 布尔表达式 ?条件满足时
文献解读-Chromosome-Scale Genome of Masked Palm Civet (Paguma larvata) Shows Genomic Signatures of Its Biological Characteristics and Evolution
这项系统性的基因组研究揭示了果子狸的关键生物学特征和进化适应性,为理解其作为病毒宿主的分子机制提供了重要见解。不仅深化了对该物种的认识,也为人畜共患病防控提供了重要的科学依据。
点亮交通 “智慧眼”:路口监测平台应用实践
点亮交通“智慧眼”:路口监测平台应用实践 该平台基于YOLOX模型,通过PyQt5实现可视化界面,对交通路口的行人、汽车和自行车进行实时监测。系统支持摄像头实时监测和视频文件上传检测,并统计目标数量。
课时15:Java运算符(基础数学运算符)
课时15介绍了Java中的基础数学运算符,涵盖加、减、乘、除及自增自减运算。强调了运算符的优先级和使用括号的重要性,并通过范例展示了四则运算与自增自减的具体应用。提醒编写代码时应保持简洁,避免复杂的表
点晴PMS:港口码头管理的智能引擎,驱动效率革命
在全球贸易蓬勃发展的今天,港口码头作为连接世界的枢纽,正面临着效率提升和成本优化的双重挑战。点晴PMS港口码头管理系统,凭借其强大的核心功能和创新的管理理念,为港口码头企业提供了一站式解决方案,开启智
导入虚拟机到Hyper-V环境时,理解并配置网络适配器设置是确保网络通信的关键
在Hyper-V环境中,正确配置虚拟机的网络适配器是确保其网络通信的关键。需先启用Hyper-V功能并创建虚拟交换机。接着,在Hyper-V管理器中选择目标虚拟机,添加或配置网络适配器,选择合适的虚拟
Hyper-V的哪些性能?使其成为企业构建云平台和虚拟化环境的首选
Hyper-V凭借高效性、灵活性、高可用性及管理简便性等优势,成为企业构建云平台和虚拟化环境的首选。其微内核架构、硬件辅助虚拟化技术和动态内存管理提升了性能与资源利用率;支持多操作系统和硬件平台,具备
通过RPM 集中式部署的PolarDB-X集群,总会出现某一台数据库莫名奇妙挂掉的情况
我通过RPM 集中式部署的PolarDB-X集群总会出现某一台数据库莫名奇妙挂掉的情况版本号是t-polardbx-engine-8.4.19-20241112.el7.aarch64.rpm安装环
课时14:Java数据类型划分(初见String类)
课时14介绍Java数据类型,重点初见String类。通过三个范例讲解:观察String型变量、"+"操作符的使用问题及转义字符的应用。String不是基本数据类型而是引用类型,但
深入解析图神经网络注意力机制:数学原理与可视化实现
本文深入解析了图神经网络(GNNs)中自注意力机制的内部运作原理,通过可视化和数学推导揭示其工作机制。文章采用“位置-转移图”概念框架,并使用NumPy实现代码示例,逐步拆解自注意力层的计算过程。文中

工业零件不良率、残次率的智能数据分析和数字化管理
在传统工业领域,我们通过引入DataV-Note平台,成功实现了企业智能数据分析与数字化管理的初步目标。这一平台不仅显著提升了数据处理的效率和准确性,还为我们的日常运营提供了更加科学、直观的决策支持。
小白在做京东项目数据采集并实现可视化的过程中需要的步骤要点
根据业务需求和数据反馈,不断优化数据采集和分析流程。 引入新的数据源、算法和技术,提高分析效率和准确性。 通过以上步骤,京东可以利用数据采集和可视化分析来洞察市场趋势、优化库存管理、提升用户体验和增强
课时13:Java数据类型划分(布尔型)
观察布尔型的操作。布尔是一位数学家的名字,这个布尔发明了两个单词:True、False(一个表示真一个表示假)。一般布尔类型都只表示逻辑的计算结果。
如何使用阿里云做抖音无人直播
阿里云服务器第九代企业级g9i实例技术特点、性能优势、适用场景简介
阿里云不断推出创新产品和技术,以满足市场对高性能、高可靠、高性价比云计算资源的需求。近日,阿里云正式面向全球发布了第九代企业级实例ECS g9i,并开启了邀测活动。本文将深入解析阿里云ECS g9i实
关于AI助理的自定义能力,如何获取用户在AI助理上传的文件
通过聊天信息获取的文件链接是文件在钉钉的链接这个链接无法直接下载文件。我想下载到服务器上进行使用根据文件下载的接口需要spaceId和dentryId该如何获取呢
都按正常流程操作了,这到底什么问题?无法把问题具体描述
连接 Custom Provider 失败。这通常是由于配置错误或 Custom Provider 账户问题。请检查您的设置并验证您的 Custom Provider 账户状态。 API Error
阿里云企业用户最高100万上云补贴金怎么申请?有什么条件?
阿里云企业用户最高100万上云补贴金怎么申请有什么限制条件吗只要是实名认证是企业就行吗 https://www.aliyun.com/benefit/developer/company
基于 Python 广度优先搜索算法的监控局域网电脑研究
随着局域网规模扩大,企业对高效监控计算机的需求增加。广度优先搜索(BFS)算法凭借其层次化遍历特性,在Python中可用于实现局域网内的计算机设备信息收集、网络连接状态监测及安全漏洞扫描,确保网络安全
指南:Claude 3.7 怎么样?国内如何使用Claude 3.7 Sonnet?
本文主要介绍了Claude 3.7 Sonnet模型的发布教你如何订阅使用Claude 3.7 Sonnect及其新功能,特别是Claude Code工具的推出。
React 音频播放控制组件 Audio Controls
本文介绍了如何使用React构建音频播放控制组件,涵盖HTML5 `<audio>`标签和React组件化思想的基础知识。针对常见问题如播放状态管理、进度条更新不准确及跨浏览器兼容性,提供
java变量与数据类型:整型、浮点型与字符类型
### Java数据类型全景表简介 本文详细介绍了Java的基本数据类型和引用数据类型,涵盖每种类型的存储空间、默认值、取值范围及使用场景。特别强调了`byte`、`int`、`long`、`flo
求问llama-gguf-split的问题
要合并分片文件只能用这个工具但下载不到自己装了llama仓库用cmake、msys64、gcc、visualstudio等工具也没编译出exe只出了几个半成品实在没时间弄了请问谁能给个llama-g
【01】对APP进行语言包功能开发-APP自动识别地区ip后分配对应的语言功能复杂吗?-成熟app项目语言包功能定制开发-前端以uniapp-基于vue.js后端以laravel基于php为例项目实战-优雅草卓伊凡
【01】对APP进行语言包功能开发-APP自动识别地区ip后分配对应的语言功能复杂吗?-成熟app项目语言包功能定制开发-前端以uniapp-基于vue.js后端以laravel基于php为例项目实战
云产品评测|云安全这道坎,企业该怎么迈?阿里云「安全体检」实测报告
随着云计算的普及,云安全问题日益突出。阿里云提供的免费“安全体检”工具,能够自动化检测系统漏洞、风险配置和病毒攻击,帮助用户及时发现并修复潜在的安全隐患。通过实际测试,该工具在基础漏洞检测方面表现出色
算法系列之数据结构-二叉搜索树
二叉查找树(Binary Search Tree,简称BST)是一种常用的数据结构,它能够高效地进行查找、插入和删除操作。二叉查找树的特点是,对于树中的每个节点,其左子树中的所有节点都小于该节点,而右
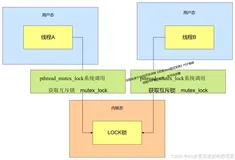
深入理解Java锁升级:无锁 → 偏向锁 → 轻量级锁 → 重量级锁(图解+史上最全)
锁状态bits1bit是否是偏向锁2bit锁标志位无锁状态对象的hashCode001偏向锁线程ID101轻量级锁指向栈中锁记录的指针000重量级锁指向互斥量的指针010尼恩提示,讲完 如减少锁粒度、






活动日历
