

阿里云开发者社区
































综合
最新
有奖励
免费用
QwQ-32B一键部署!真正的0代码,0脚本,0门槛
阿里云发布的QwQ-32B模型通过强化学习显著提升了推理能力,核心指标达到DeepSeek-R1满血版水平。用户可通过阿里云系统运维管理(OOS)一键部署OpenWebUI+Ollama方案,轻松将Q
K8S异常诊断之俺的内存呢
本文讲述作者如何解决客户集群中出现的OOM(Out of Memory)和Pod驱逐问题。文章不仅详细记录了问题的发生背景、现象特征,还深入探讨了排查过程中的关键步骤和技术细节。

技术小白如何利用DeepSeek半小时开发微信小程序?
通过通义灵码的“AI程序员”功能,即使没有编程基础也能轻松创建小程序或网页。借助DeepSeek V3和R1满血版模型,用户只需用自然语言描述需求,就能自动生成代码并优化程序。例如,一个文科生仅通过描


一篇关于DeepSeek模型先进性的阅读理解
本文以DeepSeek模型为核心,探讨了其技术先进性、训练过程及行业影响。首先介绍DeepSeek的快速崛起及其对AI行业的颠覆作用。DeepSeek通过强化学习(RL)实现Time Scaling
【最佳实践系列】通过AppFlow,支持飞书机器人调用百炼应用
本文介绍了如何创建并配置飞书应用及机器人,主要包括三个步骤:1. 登录飞书开发者后台,创建企业自建应用并添加机器人卡片和API权限;2. 创建AppFlow连接流,配置飞书平台凭证和百炼鉴权凭证,发布
快速使用 DeepSeek-R1 满血版
DeepSeek是一款基于Transformer架构的先进大语言模型,以其强大的自然语言处理能力和高效的推理速度著称。近年来,DeepSeek不断迭代,从DeepSeek-V2到参数达6710亿的De

DeepSeek个人站点一键部署流程演示

Flink CDC任务从savepoint/checkpoints状态中恢复作业错误问题
flink CDC任务监听mysql数据。只要不是从savepoint/checkpoint中恢复都是能成功运行并监听数据的但是只要从savepoint/checkpoint中恢复作业就会报如下错误
人人懂AI之从机器学习到大模型
本书面向广大IT从业者,作者将尽可能通俗易懂的把机器学习、深度学习、神经网络等基本原理讲解清楚,并分享大语言模型、知识库等当下很火爆的AIGC应用,探讨大语言模型“知识茧房”问题及解法。期望本书能成为

基于阿里百炼的DeepSeek-R1满血版模型调用【零门槛保姆级2084小游戏开发实战】
本文介绍基于阿里百炼的DeepSeek-R1满血版模型调用,提供零门槛保姆级2048小游戏开发实战。文章分为三部分:定位与核心优势、实战部署操作指南、辅助实战开发。通过详细步骤和案例展示,帮助开发者高

自动化AutoTalk第十七期-基础设施自动化IaC实践之企业案例
企业视角下的自动化业务效率化 1、实操1:TF+Docker+Gitlab+GitlabRunner构建代码管理基础 2、实操2:资源遗产配置及应用

Serverless+AI 轻松玩转高频 AIGC 场景
本书旨在整理和介绍函数计算如何构建各类 AI 应用,以及如何基于函数计算结合其他云产品来部署各种 AI 大模型。主要内容包括:【构建个人专属AI助手】【AI生图】、【AI内容创作】、【打造多形态全天候

快来零门槛、即刻拥有 DeepSeek-R1 满血版
随着人工智能技术的发展,DeepSeek作为一款新兴推理模型,凭借强大的技术实力和广泛的应用场景崭露头角。本文基于阿里云提供的零门槛解决方案,评测DeepSeek的部署与使用。该方案支持多模态任务,涵
指南:Claude 3.7 怎么样?国内如何使用Claude 3.7 Sonnet?
本文主要介绍了Claude 3.7 Sonnet模型的发布教你如何订阅使用Claude 3.7 Sonnect及其新功能,特别是Claude Code工具的推出。
Heygem:开源数字人克隆神器!1秒视频生成4K超高清AI形象,1080Ti显卡也能轻松跑
Heygem 是硅基智能推出的开源数字人模型,支持快速克隆形象和声音,30秒内完成克隆,60秒内生成4K超高清视频,适用于内容创作、直播、教育等场景。
基于 DIFY 的自动化数据分析实战
本文介绍如何使用DIFY搭建数据分析自动化流程,实现从输入需求到查询数据库、LLM分析再到可视化输出的全流程。基于经典的employees数据集和DIFY云端环境,通过LLM-SQL解析、SQL执行、
本地部署DeepSeek模型技术指南
DeepSeek模型是一种先进的深度学习模型,广泛应用于自然语言处理等领域。本文详细指导如何在本地部署DeepSeek模型,涵盖环境准备(硬件和软件要求、依赖库安装)、模型下载与配置、部署(创建Fla
快速调用 Deepseek API!【超详细教程】
Deepseek 强大的功能,在本教程中,将指导您如何获取 DeepSeek API 密钥,并演示如何使用该密钥调用 DeepSeek API 以进行调试。
从零开始教你打造一个MCP客户端
Anthropic开源了一套MCP协议,它为连接AI系统与数据源提供了一个通用的、开放的标准,用单一协议取代了碎片化的集成方式。本文教你从零打造一个MCP客户端。
在ECS上使用百炼部署满血版DeepSeek R1
本文为您介绍如何在ECS实例上部署Open WebUI,并通过大模型服务平台百炼API调用DeepSeek-R1模型推理服务。帮助您快速体验满血版DeepSeek-R1模型。
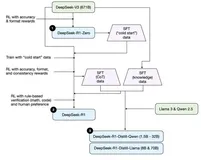
使用A10单卡24G复现DeepSeek R1强化学习过程
本文描述DeepSeek的三个模型的学习过程,其中DeepSeek-R1-Zero模型所涉及的强化学习算法,是DeepSeek最核心的部分之一会重点展示。
Manus:或将成为AI Agent领域的标杆
随着人工智能技术的飞速发展,AI Agent(智能体)作为人工智能领域的重要分支,正逐渐从概念走向现实,并在各行各业展现出巨大的应用潜力。在众多AI Agent产品中,Manus以其独特的技术优势和市
从0到1彻底掌握Trae:手把手带你实战开发AI Chatbot,提升开发效率的必备指南!
Trae是字节跳动推出的一款免费的AI集成的开发环境,集成了Claude3.5与GPT-4o等主流AI模型,提供AI问答、智能代码生成、智能代码补全,多模态输入等功能。支持界面全中文化,为中文开发者提
Browser Use:40.7K Star!一句话让AI完全接管浏览器!自动规划完成任务,多标签页同时管理
Browser Use 是一款专为大语言模型设计的智能浏览器自动化工具,支持多标签页管理、视觉识别、内容提取等功能,并能记录和重复执行特定动作,适用于多种应用场景。

进行GPU算力管理
本篇主要简单介绍了在AI时代由‘大参数、大数据、大算力’需求下,对GPU算力管理和分配带来的挑战。以及面对这些挑战,GPU算力需要从单卡算力管理、单机多卡算力管理、多机多卡算力管理等多个方面发展出来的
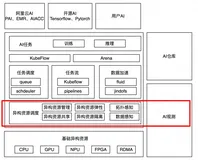
零门槛、百万token免费用,即刻拥有DeepSeek-R1满血版,还有实践落地调用场景等你来看
DeepSeek 是热门的推理模型,能在少量标注数据下显著提升推理能力,尤其擅长数学、代码和自然语言等复杂任务。本文涵盖四种部署方案,可以让你快速体验云上调用 DeepSeek-R1 满血版的 API
1分钟集成DeepSeek满血版!搭建智能运维助手
阿里云 AI 搜索开放平台面向企业及开发者提供丰富的组件化AI搜索服务,本文将重点介绍基于AI搜索开放平台内置的 DeepSeek-R1 系列大模型,如何搭建 Elasticsearch AI Ass
大模型推理主战场:通信协议的标配
DeepSeek加速了模型平权,大模型推理需求激增,性能提升主战场从训练转向推理。SSE(Server-Sent Events)和WebSocket成为大模型应用的标配网络通信协议。SSE适合服务器单
Botgroup.chat:超有趣的开源 AI 聊天室!多个 AI 在线互怼,一键搭建你的专属 AI 社群
Botgroup.chat 是一款基于 React 和 Cloudflare Pages 的开源 AI 聊天应用,支持多个 AI 角色同时参与对话,提供类似群聊的交互体验。

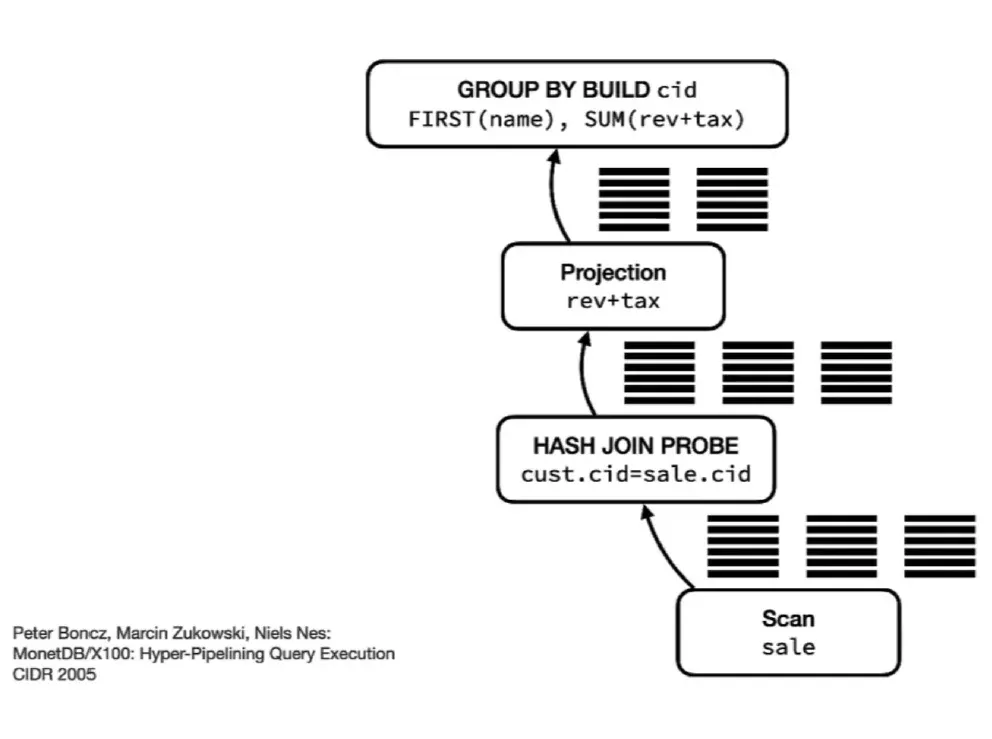
阿里妈妈基于 Flink+Paimon 的 Lakehouse 应用实践
本文总结了阿里妈妈数据技术专家陈亮在Flink Forward Asia 2024大会上的分享,围绕广告业务背景、架构设计及湖仓方案演进展开。内容涵盖广告生态运作、实时数仓挑战与优化,以及基于Paim

QwQ-32B,支持Function Call的推理模型,深度思考Agent的时代来了!
近期,Qwen 发布了 QwQ-32B - 一个在许多基准测试中性能可与 DeepSeek-R1 相媲美的推理模型。
三分钟让Dify接入Ollama部署的本地大模型!
本文介绍了如何运行 Ollama 并在 Dify 中接入 Ollama 模型。通过命令 `ollama run qwen2:0.5b` 启动 Ollama 服务,访问 `http://localhos
CentOS下载ISO镜像的方法
访问CentOS官方网站(https://www.centos.org/download/),在“Downloads”页面找到ISO镜像下载链接,选择所需版本和架构(如x86_64)开始下载。Cent
Trae 接入 Claude 3.7:AI 编程工具界的“卷王”,完全免费使用!
Trae 是一款完全免费的AI编程工具,现已接入 Claude 3.7 模型,提供代码生成、调试等强大功能,支持多模态输入和上下文理解,用户可享受24小时高速服务,无需担心付费限制。Trae 支持多平
2025年NVIDIA RTX 4090服务器租赁价格与选型详解
随着AI训练、深度学习与图形渲染需求激增,NVIDIA RTX 4090显卡成为算力租赁市场的热门选择。本文从价格体系、配置适配、成本优化三方面解析4090服务器租赁策略,涵盖短租长租价格差异、主流平
DeepSeek一体机!飞天企业版上新“AI Stack”,支持DeepSeek满血版和Qwen单机部署!
飞天企业版上新“AI Stack”,支持DeepSeek满血版和Qwen单机部署!
新用户100万token免费额度!阿里云上线DeepSeek-R1满血版
阿里云推出DeepSeek-R1满血版,新用户可享100万免费Token额度。平台支持多种模型,包括671B参数的DeepSeek-R1和通义千问。结合开源工具Chatbox,用户能轻松对接API,体
模型上新!来通义灵码体验 QwQ-32B 推理模型!
今天,阿里云发布并开源全新的推理模型通义千问QwQ-32B。通过大规模强化学习,千问QwQ-32B在数学、代码及通用能力上实现质的飞跃,整体性能比肩DeepSeek-R1。在保持强劲性能的同时,千问Q
小鱼深度评测 | 通义灵码2.0,不仅可跨语言编码,自动生成单元测试,更炸裂的是集成DeepSeek模型且免费使用,太炸裂了。
小鱼深度评测 | 通义灵码2.0,不仅可跨语言编码,自动生成单元测试,更炸裂的是集成DeepSeek模型且免费使用,太炸裂了。

【保姆级教程]】5分钟用阿里云百炼满血版DeepSeek, 手把手做一个智能体
阿里云推出手把手学AI直播活动,带你体验DeepSeek玩法。通过阿里云百炼控制台,用户可免费开通满血版R1模型,享受100w token免费额度。活动还包括实验步骤、应用开发教程及作业打卡赢好礼环节
RocketMQ 5.x,当使用Proxy时消费者无法从slave节点拉取消息
RocketMQ版本5.3部署采用主从异步复制Proxy独立部署。当主节点宕机后使用Proxy无法从slave节点拉取消息而使用Remoting协议Nameserver可以从slave节点拉取消息。
JVM实战—7.如何模拟GC场景并阅读GC日志
本文主要介绍了:如何动手模拟出频繁Young GC的场景、JVM的Young GC日志应该怎么看、编写代码模拟动态年龄判定规则进入老年代、编写代码模拟S区放不下部分进入老年代、JVM的Full GC日

JVM实战—6.频繁YGC和频繁FGC的后果
本文详细探讨了JVM中的GC机制及其优化策略,涵盖Young GC、Old GC和Full GC的触发条件与影响。首先分析了JVM GC可能导致系统卡顿的问题,特别是大内存机器上的YGC性能瓶颈,并通

基于SC-FDE单载波频域均衡的MPSK通信链路matlab仿真,包括帧同步,定时同步,载波同步,MMSE信道估计等
本内容展示了基于MATLAB 2022a的SC-FDE单载波频域均衡通信链路仿真,包括UW序列设计、QPSK调制、帧同步、定时与载波同步、SNR估计及MMSE信道估计等关键环节。通过8张仿真结果图验证
基于模糊PID控制器的puma560机器人控制系统的simulink建模与仿真
本课题研究基于模糊PID控制器的PUMA 560机器人控制系统建模与仿真,对比传统PID控制器性能。通过Simulink实现系统建模,分析两种控制器的误差表现。模糊PID结合了PID的线性控制优势与模
云计算任务调度优化matlab仿真,对比蚁群优化和蛙跳优化
本程序针对云计算任务调度优化问题,旨在减少任务消耗时间、提升经济效益并降低设备功耗。通过对比蚁群优化算法(ACO)与蛙跳优化算法(SFLA),分别模拟蚂蚁信息素路径选择及青蛙跳跃行为,在MATLAB2
MM-Eureka:多模态推理新纪元!54K训练量吊打百万级模型,K12数学能力暴增8.2%
MM-Eureka 是由上海人工智能实验室、上海创智学院、上海交通大学和香港大学联合开发的多模态推理模型,通过基于规则的强化学习,显著提升了多模态推理能力,尤其在数据效率和推理准确性方面表现突出。
MedRAG:医学AI革命!知识图谱+四层诊断,临床准确率飙升11.32%
MedRAG是南洋理工大学推出的医学诊断模型,结合知识图谱与大语言模型,提升诊断准确率11.32%,支持多模态输入与智能提问,适用于急诊、慢性病管理等多种场景。

AudioX:颠覆创作!多模态AI一键生成电影级音效+配乐,耳朵的终极盛宴
AudioX 是香港科技大学和月之暗面联合推出的扩散变换器模型,能够从文本、视频、图像等多种模态生成高质量音频和音乐,具备强大的跨模态学习能力和泛化能力。

zabbix7.0.9安装-以宝塔安装形式-非docker容器安装方法-系统采用AlmaLinux9系统-最佳匹配操作系统提供稳定运行环境-安装教程完整版本-优雅草卓伊凡
zabbix7.0.9安装-以宝塔安装形式-非docker容器安装方法-系统采用AlmaLinux9系统-最佳匹配操作系统提供稳定运行环境-安装教程完整版本-优雅草卓伊凡
数智化转型不是“买硬件”,DeepSeek一体机别乱上
过去一个月,DeepSeek一体机成为热门生意,各厂商纷纷推出相关产品。然而,其是否为企业最优解仍需探讨。云厂商如华为云已上线DeepSeek系列模型推理服务,提供全面部署方案。本文对比两种典型部署方
深入解密 :Postman、Apipost和Apifox API 协议与工具选择
作为全栈开发者,每天与API打交道是常态。本文总结了多年经验,深入解析常见API协议(HTTP(s)、SSE、gRPC、WebSocket、Socket.IO)及其适用场景,并对比三款主流调试工具(P
理解Akamai EdgeGrid认证在REST API中的应用
Akamai作为内容分发和云服务的领导者,提供了EdgeGrid平台以提升Web应用的速度、可靠性和安全性。EdgeGrid认证(Auth)通过基于令牌的安全机制,利用HMAC-SHA256签名、时间
AI变革药物研发:深势科技的云原生实践之路
阿里云与深势科技联合推出Bohrium®科研云平台和Hermite®药物计算设计平台,通过分子模拟技术大幅缩短药物研发周期、降低成本并提升成功率,为生物医药行业带来变革。
一文总览阿里云存储产品年度升级!
阿里云在“回顾·向新:AI浪潮下的数据存储进化”活动上,总结了过去一年在AI领域的存储研究成果,提出“AI领域”与“高可用底层架构”双轨策略。会上推出的CPFS智算版,针对模型训练场景全链路性能升级,
ACK Gateway with AI Extension:面向Kubernetes大模型推理的智能路由实践
本文介绍了如何利用阿里云容器服务ACK推出的ACK Gateway with AI Extension组件,在Kubernetes环境中为大语言模型(LLM)推理服务提供智能路由和负载均衡能力。文章以
Hologres Dynamic Table快速入门
本文由Hologres PD赵红梅分享,主题为Dynamic Table快速入门。内容分为三部分:一是介绍Dynamic Table,包括其在实时数仓中的应用场景及技术实现;二是讲解Dynamic T
前端开发必备!Node.js 18.x LTS保姆级安装教程(附国内镜像源配置)
本文详细介绍了Node.js的安装与配置流程,涵盖环境准备、版本选择(推荐LTS版v18.x)、安装步骤(路径设置、组件选择)、环境验证(命令测试、镜像加速)及常见问题解决方法。同时推荐开发工具链,如

在Rocky Linux 9上安装JDK并配置环境变量!
本教程介绍在Rocky Linux 9上安装JDK并配置环境变量的完整步骤。首先更新系统,清理旧版本JDK相关包及残留文件,确保环境干净。接着搜索并安装所需版本的JDK(如OpenJDK 17),验证
告别加班!用DeepSeek搭建全自动爆款图文工厂
随着人工智能技术的飞速发展,图文创作迎来了革命性飞跃。DeepSeek作为强大的AI工具,可批量生成高质量图文笔记,精准适配小红书、抖音、B站等平台。通过明确选题、撰写提示词,用户能轻松定制内容风格,
1688拍立淘图片搜索接口全攻略
1688拍立淘图片搜索接口由阿里巴巴提供,支持通过上传图片在1688平台搜索相似商品。该接口基于图像识别技术,具备高精度匹配、丰富商品信息返回、支持多图片格式及可定制化搜索等特点,适用于电商选品、商品
三大运营商骨干网架构深度剖析:线路建设与用户体验
本文全面解析了中国三大电信运营商(中国电信、中国联通、中国移动)的网络架构及性能特点,涵盖骨干网技术、区域线路实测、应用场景优化及未来发展趋势。具体内容包括:中国电信的双网体系(163骨干网与CN2精
策略模式(Strategy Pattern)深度解析教程
策略模式属于行为型设计模式,通过定义算法族并将其封装为独立的策略类,使得算法可以动态切换且与使用它的客户端解耦。该模式通过组合替代继承,符合开闭原则(对扩展开放,对修改关闭)。
物业如何使用消防安全管理系统实现数字化转型
监管越来越严,人手越来越少,传统办法走不通了,数字化转型就成了必经之路。草料二维码这种轻量化的方案,不仅仅是工具,更像是个“贴心帮手”,帮物业从“被动应付检查”变成“主动管好安全”

1688商品列表API接口指南
1688 商品列表 API 可帮助开发者和商家获取商品基本信息(如 ID、名称、价格等)、支持筛选排序(类目、价格、销量等条件)、分页查询及指定店铺商品获取,便于商品管理与竞品分析。调用流程包括:注册
生态融合与价值深耕:中国CRM行业的未来格局与路径抉择
中国CRM行业从野蛮生长迈向生态竞合,低价烧钱模式难以为继,深耕客户价值的长期主义逐渐成为主流。销售易与腾讯的战略合作标志着行业进入生态博弈时代,技术赋能、资源整合与国际化布局成为关键赛点。未来,企业
【YashanDB知识库】如何使用jdbc向YashanDB批量插入gis数据
本文以GIS表为例,介绍通过Java代码向数据库插入POINT类型地理数据的方法。首先创建包含ID和POS字段的GIS表,POS字段为ST_GEOMETRY类型。接着利用Java的PreparedSt
【YashanDB知识库】kettle同步大表提示java内存溢出
在数据导入导出场景中,使用Kettle进行大表数据同步时出现“ERROR:could not create the java virtual machine!”问题,原因为Java内存溢出。解决方法包
【📕分布式锁通关指南 08】源码剖析redisson可重入锁之释放及阻塞与非阻塞获取
本文深入剖析了Redisson中可重入锁的释放锁Lua脚本实现及其获取锁的两种方式(阻塞与非阻塞)。释放锁流程包括前置检查、重入计数处理、锁删除及消息发布等步骤。非阻塞获取锁(tryLock)通过有限

【YashanDB知识库】kettle同步PG至崖山提示no encryption pg_hba.conf记录
在使用 Kettle 进行 PostgreSQL 至崖山数据库的数据同步时,可能出现连接报错。原因是 `pg_hba.conf` 文件未正确配置 IP 连接规则。此文件控制客户端认证,决定哪些主机和用
【YashanDB知识库】MySQL迁移至崖山char类型数据自动补空格问题
**简介**:在MySQL迁移到崖山环境时,若字段类型为char(2),而应用存储的数据仅为'0'或'1',查询时崖山会自动补空格。原因是mysql的sql_mode可
YashanDB共享集群产品能力观测:细节足见功底
本文根据前泽塔数科研发总监王若楠在“2024年国产数据库创新生态大会”上的演讲整理,全面测试了崖山共享集群YAC的架构、功能、高可用性与性能。测试结果显示,YAC具备全对称架构,兼容Oracle特性,
【YashanDB知识库】要有好的跑批性能,有哪些参数要注意
本文来自YashanDB官网,主要探讨了在使用YashanDB进行批量任务时如何优化性能。文章列举了影响跑批性能的关键参数,并提供了最佳配置建议,涵盖空间划分、快照管理、统计信息收集及参数调整等方面。
【YashanDB知识库】同样建表语句,大整型数字在Oracle插入成功,在YashanDB插入失败
本文来自YashanDB官网,探讨在YashanDB与Oracle中执行相同建表语句时,插入大整型数字引发的错误(YAS-00013)。问题源于YashanDB的INT类型取值范围有限(-2,147,
解读 C++ 助力的局域网监控电脑网络连接算法
本文探讨了使用C++语言实现局域网监控电脑中网络连接监控的算法。通过将局域网的拓扑结构建模为图(Graph)数据结构,每台电脑作为顶点,网络连接作为边,可高效管理与监控动态变化的网络连接。文章展示了基
【YashanDB知识库】如何将mysql含有group by的SQL转换成崖山支持的SQL
本文探讨了在YashanDB(崖山数据库)中执行某些SQL语句时出现的报错问题,对比了MySQL的成功执行结果。问题源于SQL-92标准对非聚合列的严格限制,要求这些列必须出现在GROUP BY子句中
【YashanDB知识库】UNDO表空间膨胀怎么处理
本文来自YashanDB官网,针对用户反馈的UNDO表空间持续膨胀问题进行分析与解决。问题影响功能使用,主要出现在23.2及以上版本。文章提供了排查方法,如通过视图`dba_tablespaces`和
【YashanDB知识库】oracle与yashanDB的jdbc返回常量列"0.00"的精度和刻度不一致
本文分析了YashanDB中一个客户遇到的问题:常量列"0.00"在Java中被错误映射为整型而非浮点型,导致查询失败。问题源于Oracle与YashanDB的JDBC驱动对常量列
《解锁AI-量子计算初创密码:从0到1的关键一跃》
AI-量子计算领域是科技前沿的交汇点,融合人工智能与量子计算技术,蕴含改变未来的无限可能。然而,创业之路充满挑战,初创企业需在技术创新、市场定位、人才团队和资金支持等方面全面发力。通过优化算法与硬件、
《量子加密携手AI:构筑网络安全的坚固防线》
在数字化时代,网络安全至关重要。量子加密技术基于量子力学原理,提供近乎绝对的信息传输安全性;AI安全防护则通过机器学习实时检测和防御网络威胁。两者的结合为密钥管理、加密算法优化及威胁防御带来了革命性提
鸿蒙开发:ArkTs数据类型
最后一点是,ArkTS不支持any和unknown类型,需要显式指定具体类型,否则会报异常,具体原因是,这是ArkTS的特性之一,那就是使用静态类型;如果程序采用静态类型,即所有类型在编译时都是已知的

《AI数据挖掘牵手量子计算:打破边界,重塑未来》
在数字化时代,AI数据挖掘与量子计算的数据处理机制作为探索数据宇宙的先锋,正逐步融合。AI数据挖掘通过算法从海量数据中提取价值,应用于电商推荐、医疗诊断等领域;量子计算凭借叠加态和纠缠态特性实现高效并
《量子门与AI神经元:计算世界的奇妙碰撞》
量子计算与人工智能是当今科技领域的两大前沿,其核心机制分别为量子门操作和神经元计算。量子门利用叠加与纠缠特性操控量子比特,实现高效并行计算;而神经元计算模拟生物神经网络,通过权重调整学习数据模式。两者
告别数据库束缚!用esProc在 csv 文件上执行 SQLv
esProc SPL 是一款支持简单 SQL 的计算工具,可直接在结构化文本文件(如 CSV、TXT)上执行 SQL 语句,无需数据库即可完成数据分析。它根据文件扩展名自动识别分隔符,支持无标题行文件






