









基于yolov8的深度学习垃圾分类检测系统
本研究针对传统垃圾分类效率低、准确率不高等问题,提出基于YOLOv8与Python的深度学习检测系统。通过构建高质量标注数据集,利用YOLOv8强大的目标检测能力,实现垃圾的快速精准识别,提升分类自动化水平,助力环境保护与资源回收。
基于vite7.2+vue3.5+deepseek-v3.2高颜值流式ai会话助手
基于vue3.5+vite7.2+vant4+markdown+openai深度集成deepseek-v3.2聊天大模型。支持浅色+深色主题、stream流式输出、代码高亮、复制代码、katex公式、mermaid图表等功能。
Python | K折交叉验证的参数优化的GradientBoost及SHAP可解释性分析回归预测算法
本教程介绍基于Python的GradientBoost回归预测算法,结合K折交叉验证与贝叶斯/随机/网格搜索进行超参数优化,并引入SHAP实现模型可解释性分析。涵盖数据预处理、模型训练、多维度评估及可视化,适用于地球科学、医学、工程、经济等多个领域的连续变量预测任务,代码与数据齐全,适合科研与实际应用。
构建AI智能体:五十九、特征工程:数据预处理到特征创造的系统性方法
摘要:特征工程是将原始数据转化为机器学习模型可理解格式的关键步骤,类比于食材烹饪过程。其核心包括数据清洗(处理缺失值、异常值)、特征转换(标准化、分箱)、特征创造和特征选择。通过员工离职预测案例,展示了如何通过单变量分析(满意度、工作时长分布)、多变量分析(满意度与绩效关系)和业务分析(部门薪资组合)构建有效特征。特征工程能提升模型性能(如使用简单模型获得好效果)、增强可解释性(明确风险因素)并减少数据需求。
淘宝买家卖家店铺订单数据API接口指南
淘宝开放平台提供RESTful API,支持OAuth 2.0认证,可安全获取订单、商品、用户等电商数据。支持分页、时间筛选,返回JSON格式,适用于订单管理、数据分析等场景,采用HTTPS加密传输,保障数据安全。
AI 问答占 52%!长沙别墅装修 GEO 突围:30 天引用率暴涨 40%
周有贵,巴黎学院人工智能博士,GGI商学院GEO首席技术专家,专注AI时代数字营销革新。2025年12月1日,长沙著名别墅设计师张主华专程拜访交流,共探GEO技术在装修设计行业中的AI引流逻辑与实操应用。面对生成式AI问答入口占比突破52%的新趋势,传统SEO正被GEO取代——从链接点击到答案呈现,企业需通过构建灯塔内容、E-E-A-T信任链与结构化数据,让品牌信息被AI优先引用。本次对话揭示:未来流量之争,本质是“被AI推荐”的能力之争。
基于python大数据的小说数据可视化及预测系统
本研究基于Python构建小说数据可视化与预测系统,整合多平台海量数据,利用爬虫、数据分析及机器学习技术,实现热度趋势预测与用户偏好挖掘。系统结合Django、Vue等框架,提供动态交互式可视化界面,助力平台精准运营、作者创作优化与读者个性化阅读体验,推动网络文学数据智能化发展。
如何找到适合好用的 AI 数据分析软件?实用指南
AI 数据分析软件则通过自然语言交互、智能问数、自动化建模查询等技术,让业务人员无需写复杂的 SQL 即可自主获取数据洞察,快速定位问题根因,并生成结构化决策建议。
企业网站模板 网站源码下载 网站源码建站
在数字化时代,企业需专业网站拓展市场,网站源码建站因高性价比、强灵活性成中小企业首选,比定制开发成本低、比模板建站自由。选源码要明确需求、看质量售后与 SEO 扩展性,下载用官方渠道,经准备服务器域名、安装设置可上线,助企业低成本建高自由度安全网站。
TKM帮您管理编程开发过程中多语言、多版本的切换烦恼
TakMll(特客猫)是一款多语言环境管理工具,支持PHP、Java、Python等多版本快速切换。通过“tkm”命令实现环境添加、查询、切换与删除,简化开发环境配置流程,提升效率。官网:[https://tkm.youqiong.net/](https://tkm.youqiong.net/)
速卖通商品详情API文档
速卖通商品详情API通过标准化接口实时获取商品标题、价格、SKU、库存等信息,支持多语言返回,适用于比价、选品分析等场景。采用AppKey+Token认证与MD5签名保障安全。
淘宝天猫商品评论API:轻松挑选优质商品的利器
天猫商品评论API是淘宝开放平台的核心接口,通过商品ID获取用户评价内容、评分、时间等结构化数据,支持分页、筛选与多种排序。涵盖昵称、星级、追评、图片等字段,适用于电商分析、竞品监控。采用HTTP请求,JSON返回,需签名认证,安全高效,支持高并发实时调用。
淘宝商品评论的情感分析实战:API数据驱动用户洞察
淘宝商品评论API是淘宝开放平台提供的数据接口,支持通过Python高效获取商品的用户评价信息。可返回结构化数据,包含评论内容、评分、时间、图片及商家回复等,支持多维度筛选与分页,适用于竞品分析、用户画像与市场研究。
未来人工智能如何重构”时间“?
时间是数学还是幻觉?从熵增到几何,从人类意识到AI智能,本文探讨时间的本质。线性、循环与拓扑模型揭示其多维可能;热力学箭头与认知局限引发哲学思辨;而AI的并行预测与信息压缩,或将重构时间本身。未来智能或不再线性行走,而是编织多维时间之网,重塑我们对存在的理解。(238字)

Transformer自回归关键技术:掩码注意力原理与PyTorch完整实现
掩码注意力是生成模型的核心,通过上三角掩码限制模型仅关注当前及之前token,确保自回归因果性。相比BERT的双向注意力,它实现单向生成,是GPT等模型逐词预测的关键机制,核心仅需一步`masked_fill_`操作。
【清爽加速】Windows 11 Pro 24H2-Emmy精简系统
“清爽加速”Windows 11 Pro 24H2 针对老旧或低配设备,通过精简系统、优化服务与简化装机流程,降低资源占用,提升运行流畅度,兼顾安全性与稳定性,让老设备也能轻松应对日常办公与轻度娱乐需求。

Dots.ocr:告别复杂多模块架构,1.7B参数单一模型统一处理所有OCR任务22
Dots.ocr 是一款仅1.7B参数的视觉语言模型,正在重塑文档处理技术。它将布局检测、文本识别、阅读顺序理解和数学公式解析等任务统一于单一架构,突破传统OCR多模块流水线的限制。在多项基准测试中,其表现超越大参数模型,展现出“小而精”的实用价值,标志着OCR技术向高效、统一、灵活方向演进。
Java 大视界 -- 基于 Java 的大数据可视化在企业生产运营监控与决策支持中的应用(228)
本文探讨了基于 Java 的大数据可视化技术在企业生产运营监控与决策支持中的关键应用。面对数据爆炸、信息孤岛和实时性不足等挑战,Java 通过高效数据采集、清洗与可视化引擎,助力企业构建实时监控与智能决策系统,显著提升运营效率与竞争力。
Java 大视界 -- Java 大数据在智能物流运输车辆智能调度与路径优化中的技术实现(218)
本文深入探讨了Java大数据技术在智能物流运输中车辆调度与路径优化的应用。通过遗传算法实现车辆资源的智能调度,结合实时路况数据和强化学习算法进行动态路径优化,有效提升了物流效率与客户满意度。以京东物流和顺丰速运的实际案例为支撑,展示了Java大数据在解决行业痛点问题中的强大能力,为物流行业的智能化转型提供了切实可行的技术方案。
[VLDB 2025]面向Flink集群巡检的交叉对比学习异常检测
阿里云与华东师范大学合作论文《Noise Matters: Cross Contrastive Learning for Flink Anomaly Detection》被VLDB 2025接收。该研究聚焦Flink集群热点机器异常检测,提出跨对比学习方法,结合先验知识优化模型训练,有效应对噪声数据干扰,提升检测准确率。该技术已应用于Flink集群智能巡检系统,助力运维风险预警。
基于PAI-ChatLearn的GSPO强化学习实践
近期,阿里通义千问团队创新性提出了GSPO算法,GSPO 算法与其他 RL 算法相比,定义了序列级别的重要性比率,并在序列层面执行裁剪、奖励和优化。同时具有强大高效、稳定性出色、基础设施友好的突出优势。

数据量暴涨时,抓取架构该如何应对?——豆瓣电影案例调研
本案例讲述了在豆瓣电影数据采集过程中,面对数据量激增和限制机制带来的挑战,如何通过引入爬虫代理、分布式架构与异步IO等技术手段,实现采集系统的优化与扩展,最终支撑起百万级请求的稳定抓取。
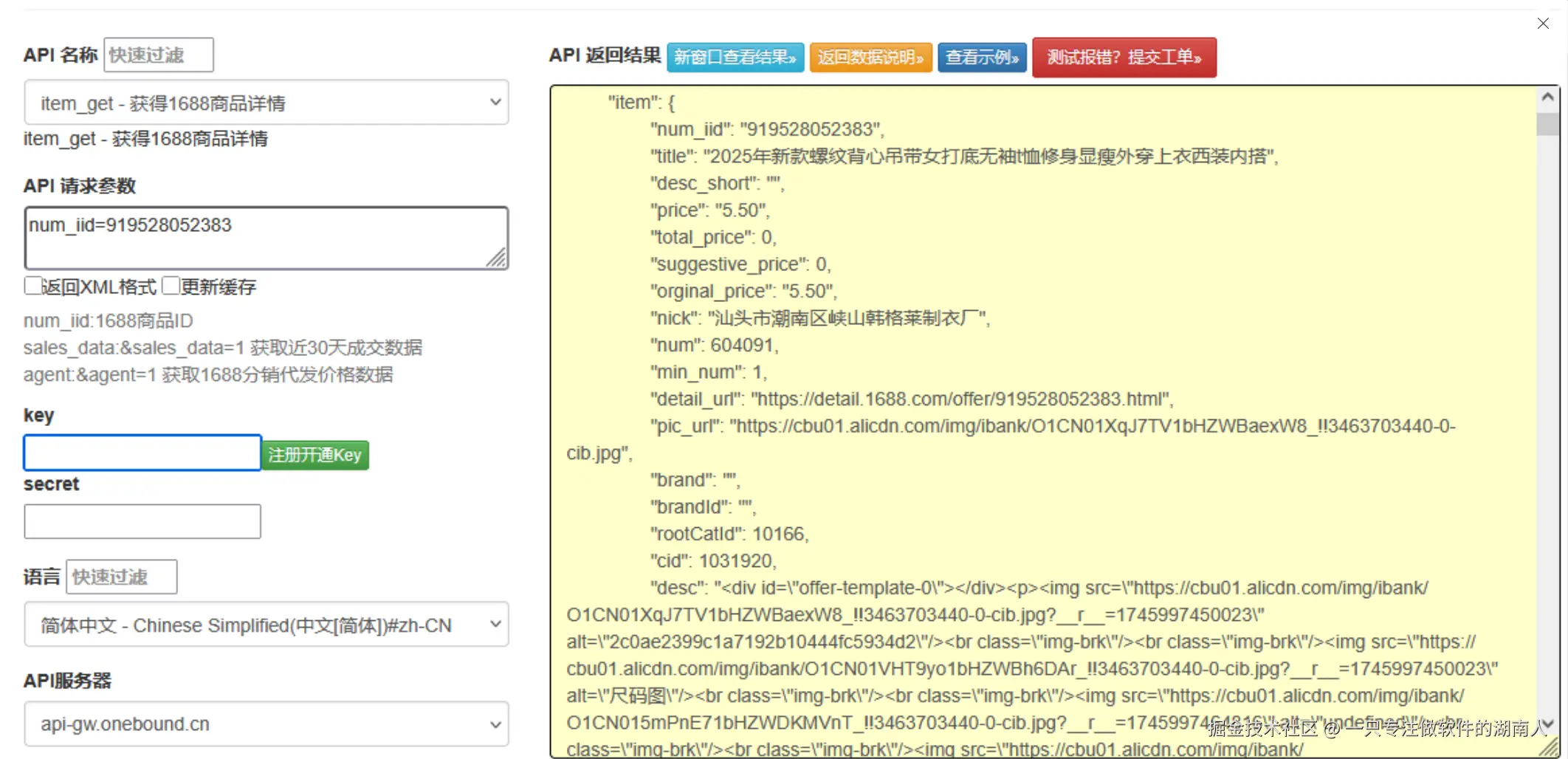
1688 商品详情接口开发实战:从平台特性到高可用实现
本文深入解析了1688平台商品详情接口的技术实现,涵盖参数设计、签名机制、数据解析等内容,并结合代码示例展示如何构建适用于B2B业务场景的接口调用系统。重点突出其批发属性、供应商信息、多规格支持及定制化能力等B2B特性,帮助开发者高效对接1688开放平台。

稳定性隐患手册:开发日常中的六个易被忽略的细节误区
本文从程序设计角度出发,结合多领域视角,深入解析信息采集系统稳定性问题。通过六大常见陷阱与代码示例,教你构建“不易倒”的系统结构,提升异常恢复、调度弹性与风控能力。
Java 大视界 -- Java 大数据机器学习模型在遥感图像土地利用分类中的优化与应用(199)
本文探讨了Java大数据与机器学习模型在遥感图像土地利用分类中的优化与应用。面对传统方法效率低、精度差的问题,结合Hadoop、Spark与深度学习框架,实现了高效、精准的分类。通过实际案例展示了Java在数据处理、模型融合与参数调优中的强大能力,推动遥感图像分类迈向新高度。
Java 大视界 -- Java 大数据机器学习模型在游戏用户行为分析与游戏平衡优化中的应用(190)
本文探讨了Java大数据与机器学习模型在游戏用户行为分析及游戏平衡优化中的应用。通过数据采集、预处理与聚类分析,开发者可深入洞察玩家行为特征,构建个性化运营策略。同时,利用回归模型优化游戏数值与付费机制,提升游戏公平性与用户体验。
《VGSP-C (Virtual GPU Scheduling Platform on CPU):基于CPU的虚拟GPU调度平台》
VGSP-C(基于CPU的虚拟GPU调度平台)提出通过“软仿真+并行调度+多机协同”三大路径,在普通CPU上模拟GPU并行计算行为。适用于资源受限或低成本场景,支持单机推理、分布式训练与极简CPU集群部署,提供统一编程接口与弹性扩展能力,助力AI普惠与算力再平衡。

分布式新闻数据采集系统的同步效率优化实战
本文介绍了一个针对高频新闻站点的分布式爬虫系统优化方案。通过引入异步任务机制、本地缓存池、Redis pipeline 批量写入及身份池策略,系统采集效率提升近两倍,数据同步延迟显著降低,实现了分钟级热点追踪能力,为实时舆情监控与分析提供了高效、稳定的数据支持。
时空API实测:区域人群客流画像数据快速获取
市场调研无需繁琐查找客流数据,通过API接口快速获取人群画像与客流统计信息。支持自由选择区域、时间季度及人群类型,返回包括年龄、性别、职业、消费偏好等多维数据。
1688商品详情API全字段解析:从基础参数到SKU深度挖掘
1688商品详情API为开发者提供高效获取商品信息的官方通道,支持自动化获取标题、价格、库存等核心数据,适用于电商开发、数据分析及供应链管理。接口支持灵活参数配置,并提供Python调用示例,便于快速集成与应用。
最新技术栈下 Java 面试高频技术点实操指南详解
本指南结合最新Java技术趋势,涵盖微服务(Spring Cloud Alibaba)、响应式编程(Spring WebFlux)、容器化部署(Docker+Kubernetes)、函数式编程、性能优化及测试等核心领域。通过具体实现步骤与示例代码,深入讲解服务注册发现、配置中心、熔断限流、响应式数据库访问、JVM调优等内容。适合备战Java面试,提升实操能力,助力技术进阶。资源链接:[https://pan.quark.cn/s/14fcf913bae6](https://pan.quark.cn/s/14fcf913bae6)
使用DevEcoStudio 开发、编译鸿蒙 NEXT_APP 以及使用中文插件
# 使用DevEcoStudio 开发、编译鸿蒙 NEXT_APP 以及使用中文插件 #鸿蒙开发工具 #DevEco Studio
国内快递地址解析技术的工作原理详解
随着电商和快递行业快速发展,非结构化地址问题日益突出,如字段混杂、拼写错误等,传统方式难以高效处理。为此,探数平台推出基于NLP和地理信息的快递地址解析API,可将原始地址文本解析为标准结构化字段(如省、市、区、街道等),并支持收件人姓名与电话提取。 技术上,该API采用深度学习模型(如BERT、BiLSTM)进行语义理解,结合地址知识图谱实现纠错与补全。服务支持SaaS调用或私有化部署,性能稳定,适用于各类前端场景。通过地址结构化处理,企业可显著提升订单处理效率,减少配送错误,优化用户体验,助力全链路智能化升级。无论是电商平台还是物流系统,均可从中受益。
车辆车型大全 API 实战指南:推动交通行业智能化
车辆车型大全API由探数平台提供,旨在解决企业班车、物流运输及汽车销售等行业对标准化车型数据的需求。传统人工维护车型库效率低且易出错,而该API覆盖主流品牌与车系,包含品牌、车系、销售车型及配置参数等详细信息,适用于车队管理、电商平台及汽车资讯平台。API提供四个子接口:获取品牌、车系、销售车型与配置详情信息,支持高效查询。通过HTTP POST请求即可调用,返回结构化数据,助力企业实现智能化运营与科学决策,在绿色智能交通时代发挥重要作用。

基于图神经网络的自然语言处理:融合LangGraph与大型概念模型的情感分析实践
本文探讨了在企业数字化转型中,大型概念模型(LCMs)与图神经网络结合处理非结构化文本数据的技术方案。LCMs突破传统词汇级处理局限,以概念级语义理解为核心,增强情感分析、实体识别和主题建模能力。通过构建基于LangGraph的混合符号-语义处理管道,整合符号方法的结构化优势与语义方法的理解深度,实现精准的文本分析。具体应用中,该架构通过预处理、图构建、嵌入生成及GNN推理等模块,完成客户反馈的情感分类与主题聚类。最终,LangGraph工作流编排确保各模块高效协作,为企业提供可解释性强、业务价值高的分析结果。此技术融合为挖掘非结构化数据价值、支持数据驱动决策提供了创新路径。

介绍一下这只小水獭 —— Fluss Logo 背后的故事
Fluss是一款开源流存储项目,致力于为Lakehouse架构提供高效的实时数据层。其全新Logo以一只踏浪前行的小水獭为核心形象,象征流动性、适应性和友好性。水獭灵感源于“Fluss”德语中“河流”的含义,传递灵活与亲和力。经过30多版设计迭代,最终呈现动态活力的视觉效果。Fluss计划捐赠给Apache软件基金会,目前已开启孵化提案。社区还推出了系列周边礼品,欢迎加入钉钉群109135004351参与交流!

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。
