
大多数 RAG 系统,都是“死在太热心”
如果你回顾一个 RAG 项目的演化过程,往往会发现一条非常一致的路径:
- 初期:
“模型老说不知道,肯定是文档没召回全。”
- 中期:
“那就把 TopK 开大一点。”
- 后期:
“再多加点文档,总有一个能用。”
在这个过程中,有一个隐含假设始终没有被质疑过:
“模型看到的信息越多,
答案就会越可靠。”
但只要你把系统跑到真实业务规模,这个假设几乎一定会崩。
于是你会看到一些非常诡异的现象:
- 模型不再说“不知道”
- 回答越来越完整
- 语气越来越自信
但错误率,反而在悄悄上升。
这篇文章要回答的,就是:
RAG 系统里,
什么时候“多看”已经变成了“风险放大”,
而不是“效果提升”?
RAG 演化路径:少看 → 多看 → 过载
先给一个必须先接受的结论(非常重要)
在展开之前,我先把这篇文章最核心的一句话写出来:
RAG 里的“多看一点”,
并不会让模型更聪明,
只会让它更难判断什么是重要的。
如果你仍然把 RAG 理解成“给模型喂资料”,
那后面所有现象都会显得不可理解。
第一层误解:把 RAG 当成“信息补全系统”
这是 RAG 最常见、也最根深蒂固的误解。
很多人潜意识里把 RAG 想成:
“模型不知道 → 我给它补资料 → 它就知道了。”
这个逻辑在极简问答场景下,确实成立。
但在真实系统中,问题往往不是:
- 信息是否存在
而是:
- 信息是否适用于当前问题
- 信息之间是否彼此兼容
- 信息是否构成完整推理路径
而 RAG 的“多看”,并不会自动解决这些问题。
第二层:模型并不会“筛选证据”,它只会“努力利用”
这是一个很多人不愿意承认,但必须正视的事实。
模型面对上下文时,并不会:
- 判断哪条证据更权威
- 主动丢弃不相关内容
- 提醒你“这些信息互相冲突”
它真正会做的,是:
在你给的所有内容里,
尽量拼出一个
“听起来合理”的答案。
这意味着什么?
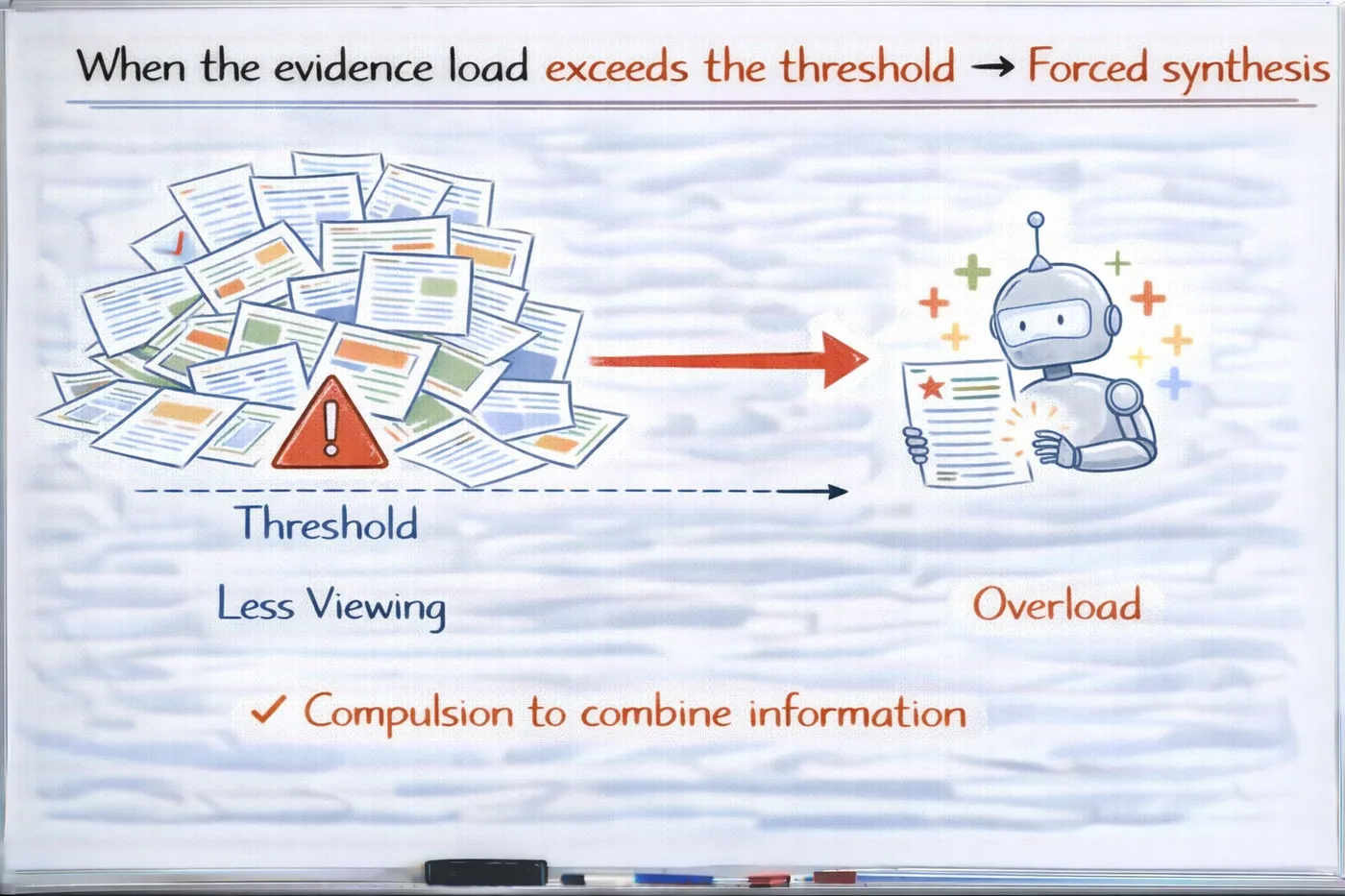
意味着当你让模型“多看一点”时:
- 你不是在帮它判断
- 而是在增加它必须解释的信息负担
而一旦负担超过模型的“判断能力阈值”,
模型就会自动进入:
“强行综合模式”
这正是胡说开始的地方。
证据负载超过阈值 → 强行综合
第三层:TopK 变大,本质上是在放大“错误的概率空间”
我们单独把 TopK 拿出来说。
TopK 的本质是:
在所有 chunk 中,
选出相似度最高的 K 个
注意这里没有任何一步是:
- 检查逻辑一致性
- 检查时间先后
- 检查适用范围
于是当 K 变大时,必然发生三件事:
- 更多边缘相关内容被引入
- 更高概率引入过期 / 例外 / 特殊情况
- chunk 之间发生冲突的概率迅速上升
这时候,模型面临的不是“信息更充分”,
而是:
证据空间被快速污染。
第四层:什么时候“证据不足”反而比“证据过载”更安全
这是一个非常反直觉、但在工程上极其重要的判断。
在 RAG 系统中,两种失败模式是不可避免的:
- 证据不足
- 证据冲突 / 过载
从风险角度看,这两者并不对等。
证据不足时
- 模型更容易犹豫
- 更容易说“不知道”
- 错误往往是“没答出来”
证据过载时
- 模型更自信
- 更容易强行总结
- 错误往往是“答得很像,但是错的”
从线上风险来看,第二种几乎永远更危险。
这也是为什么:
成熟系统,宁可偶尔“不答”,
也不愿频繁“自信地答错”。
第五层:什么时候你已经在“剥夺模型的犹豫能力”
这是判断“该不该少看”的一个非常关键信号。
你可以回顾一下模型最近的行为变化:
- 是否几乎不再说“信息不足”?
- 是否对模糊问题也给出完整结论?
- 是否很少出现条件性表达?
如果答案是“是”,那很可能不是模型变强了,
而是:
你通过 RAG,
帮它提前做了“信息完备”的假设。
而一旦模型失去了“犹豫信号”,
它就只剩下:
生成答案这一种选择。
第六层:chunk size × TopK,是“少看”的关键调节点
很多人把“少看一点”理解成:
“那就把 TopK 调小。”
但这是一个过于粗糙的理解。
真正影响模型“看多少”的,其实是:
- 单个 chunk 的信息密度
- TopK 聚合后的总证据复杂度
这两个变量是乘法关系。
你会发现一个非常稳定的规律:
- chunk 越大,越该减 K
- chunk 越小,才有资格加 K
如果你反着来:
- 大 chunk × 大 TopK
那你几乎一定会得到:
信息极度丰富、
但逻辑极度混乱的上下文。
第七层:一个极简示意,理解“少看”的工程意义
我们用一段极简伪代码,描述模型面对上下文时的“心理负担”。
def answer(query, contexts):
if contexts.is_coherent():
return generate_answer()
else:
# 模型不会报错
return force_merge_and_generate()
当你不断加 context 时:
is_coherent()的概率迅速下降- 但模型不会停
- 只会更努力地
force_merge
“少看一点”的意义就在于:
让
is_coherent()
仍然有机会为 True。
第八层:什么时候你应该明确“限制模型看到的东西”
在工程实践中,以下几种场景,非常明确地应该少看:
- 高风险问答(法规、医疗、金融)
- 强时效性问题
- 文档存在版本差异
- 文档内部有大量条件、例外
在这些场景中:
减少证据数量,
比增加证据数量更安全。
第九层:一个非常实用的判断问题(强烈建议)
在你准备继续“多给点文档”之前,问自己一句话:
如果模型现在答错了,
更可能是因为
“没看到”,
还是因为
“看多了看乱了”?
- 如果是前者 → 可以考虑多看
- 如果是后者 → 你已经该减了
这个判断,比任何指标都可靠。
很多团队在 RAG 系统中不断扩大 TopK 和上下文长度,却忽略了模型判断能力的上限。用LLaMA-Factory online对不同“可见证据规模”下的模型输出进行对照,更容易判断:当前系统是因为信息不足在犯错,还是因为信息过载在胡说。
总结:RAG 的成熟标志,不是“什么都能答”
我用一句话,把这篇文章彻底收住:
RAG 系统真正成熟的标志,
不是模型看得够多,
而是你知道什么时候
必须让它少看一点。
当你开始:
- 把“不知道”当成健康输出
- 把证据冲突当成主要风险
- 在多看之前,先想“谁该负责判断”
你才真正开始工程化地设计 RAG 系统。

