











外部工具连接SaaS模式云数仓MaxCompute 实战—— 数据库管理工具篇
本次直播将主要分享MaxCompute查询加速功能、数据库管理工具DBeaver、DataGrip、SQL Workbench/J的部分连接演示。
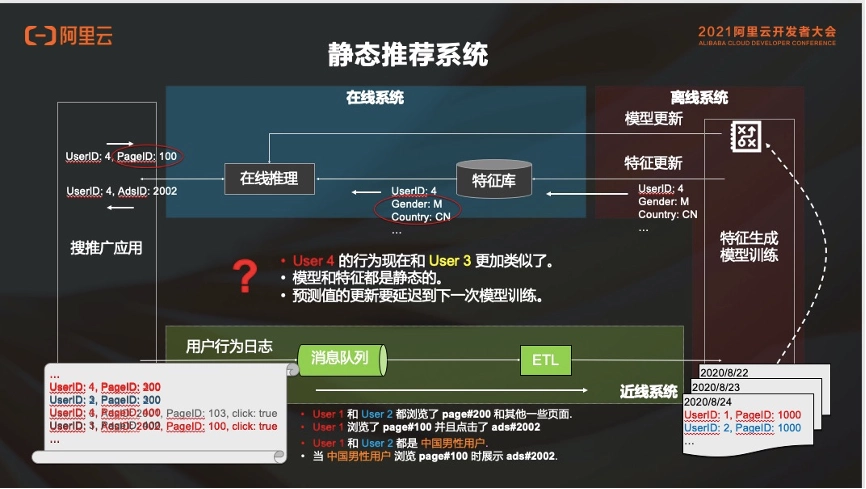
基于实时深度学习的推荐系统架构设计和技术演进
整理自 5 月 29 日 阿里云开发者大会,秦江杰和刘童璇的分享,内容包括实时推荐系统的原理以及什么是实时推荐系统、整体系统的架构及如何在阿里云上面实现,以及关于深度学习的细节介绍

持续定义Saas模式云数据仓库+实时搜索
本文由阿里云计算平台事业部 MaxCompute 产品经理孟硕为大家带来《持续定义Saas模式云数据仓库+实时搜索》的相关分享。以下是视频内容精华整理,主要包括以下三个部分:1.Why:概述与价值;2.What:应用场景;3.How:最佳实践。

持续定义SaaS模式云数据仓库+AI
本文由阿里云计算平台事业部 MaxCompute 产品经理孟硕为大家带来《持续定义SaaS模式云数据仓库+AI》的相关分享。

数据湖 VS 数据仓库之争?阿里提出大数据架构新概念:湖仓一体
随着近几年数据湖概念的兴起,业界对于数据仓库和数据湖的对比甚至争论就一直不断。有人说数据湖是下一代大数据平台,各大云厂商也在纷纷的提出自己的数据湖解决方案,一些云数仓产品也增加了和数据湖联动的特性。但是数据仓库和数据湖的区别到底是什么,是技术路线之争?是数据管理方式之争?二者是水火不容还是其实可以和谐共存,甚至互为补充?本文作者来自阿里巴巴计算平台部门,深度参与阿里巴巴大数据/数据中台领域建设,将从历史的角度对数据湖和数据仓库的来龙去脉进行深入剖析,来阐述两者融合演进的新方向——湖仓一体,并就基于阿里云MaxCompute/EMR DataLake的湖仓一体方案做一介绍。

大神都这么做,让 Kibana 搜索语法 query string 也能轻松上手
kibana 的搜索框默认选择了 query string 的搜索语法,虽然简洁却不简单,本文来帮大家如何轻松上手;

Demo 示例:如何原生的在 K8s 上运行 Flink?
Kubernetes 相信大家都比较熟悉,近两年大家都在讨论云原生的话题,讨论 Kubernetes。本文由阿里巴巴技术专家王阳(亦祺)分享,社区志愿者翟玥整理主要介绍如何原生的在 Kubernetes 上运行 Flink。

MaxCompute - ODPS重装上阵 第七弹 - Grouping Set, Cube and Rollup
MaxCompute中的GROUPING SETS功能是SELECT语句中GROUP BY子句的扩展。允许采用多种方式对结果分组,而不必使用多个SELECT语句来实现这一目的。这样能够使MaxCompute的引擎给出更有的执行计划,从而提高执行性能。
【X-Pack解读】阿里云Elasticsearch X-Pack 机器学习组件功能详解
阿里云Elasticsearch集成了Elastic Stack商业版的X-Pack组件包,包括安全、告警、监控、报表生成、图分析、机器学习等组件,用户可以开箱即用。本文将对X-Pack 的机器学习功能进行详细解读。
阿里云大数据利器Maxcompute-使用mapjoin优化查询
small is beautiful,small is powerful
#Nginx教程 Nginx作为目前最流行的高性能Web服务器和反向代理服务器,凭借其高并发、低内存消耗的特点,被广泛应用于各类生产环境。本文将从零开始,带你快速掌握Nginx的核心配置与实战技巧。
本教程详解Nginx安装、核心配置、反向代理、负载均衡与HTTPS部署,并内嵌标准JSON-LD结构化数据(Article/BreadcrumbList/WebPage等),助力SEO优化与搜索富摘要展现,提升点击率。
天猫商品详情API数据解析
天猫商品详情API解析方案,涵盖taobao/tmall.item.get接口字段说明、JSON结构、解析代码及SKU/详情图/规格提取。支持价格库存、竞品监测、舆情预警等场景,AI智能清洗、卖点解析与爆款预测,助力中小卖家高效用数。(239字)
基于Flutter3.41+Dart3.11+DeepSeek生成式AI对话应用App助手
Flutter3.41+Dart3+Dio+Getx+Markdown聚合DeepSeek-chat实战AI流式打字智能会话模板。新增深度思考模式、latex公式、mermaid图表,代码高亮/复制代码、图片预览、链接、表格等功能。
我学GEO的第一天:原来AI搜东西和百度完全不一样
第1天学GEO,我发现:以前做SEO是让网页排得靠前,现在做GEO是让AI直接提到你。我用这篇文章做了第一个实验,一个月后告诉你结果。

基于云边协同的电线电缆押出机智能调机解决方案设计与落地
本方案基于云边协同架构,融合阿里云云原生技术,破解线缆行业押出机调机效率低、原料损耗高、数据孤岛等难题;边缘毫秒级实时控制+云端Al训练优化,实现调机提效80%、降耗60%,部署快、运维省、可扩展
1949AI轻量化AI自动化:有头浏览器自动化竞品词排名监控与邮件提醒实践
1949AI轻量化AI自动化工具,基于Playwright实现有头浏览器本地监控:可视化调试、低资源占用、安全合规。支持关键词排名追踪、波动预警与邮件提醒,单文件部署、零外部依赖,专为个人开发者与小型团队打造。
1949AI 轻量化 AI 自动化办公场景应用方案 本地自动化工具与浏览器自动化实践
1949AI是一款轻量化AI办公自动化工具,基于Python实现,无需高性能算力,支持本地文件处理、网页数据抓取与Agent自主调度。模块化设计、低资源占用、全程离线运行,适配个人开发者与小型团队,安全合规、开箱即用。(239字)
Linux内核三大核心模块深度解析:调度、内存与I/O
Linux内核三大核心模块——进程调度(CFS/EEVDF等)、内存管理(buddy/slub、页回收、THP)与文件I/O(io_uring、页缓存、I/O调度)——共同决定系统性能与稳定性。深入理解其原理及协同机制,是高性能开发、调优与故障诊断的基石。(239字)

别再用ChatGPT群发祝福了!手把手教你“喂”出一个懂人情的AI,连马术梗都能接住
本文揭秘春节祝福AI背后的数据构建逻辑:不靠大模型堆参数,而用“关系感知”六维框架(称呼/关系/细节/场合/风格/篇幅)定义人情分寸;通过人工精写种子数据、模型辅助繁殖(400→3107条)、结构化提示词模板,让AI写出有记忆点的专属祝福。技术是导盲犬,帮人打捞真心。
亚马逊商品详情数据获取实战:从商品链接提取 ID 到解析详情
亚马逊商品详情API(PA-API v5与SP-API)是官方合规数据接口,分别面向第三方开发者与入驻卖家,支持获取ASIN/关键词对应的商品标题、价格、图片、评价等核心信息,广泛用于比价、选品、竞品分析及Listing优化。接入稳定、数据权威。(239字)
大模型微调后,如何判断它是不是“变聪明”了?这套评估方法论请收好。
本文系统阐述大模型微调效果评估的核心价值与实践方法:强调评估是检验泛化能力的“试金石”,须坚持人工主观评估(重业务适配性)与自动化客观评估(重量化指标)双轨并行;详解测试集构建、指标选择、基线对比等关键步骤,助力从0到1建立科学、可信、可迭代的评估体系。(239字)
梯度累积真的省显存吗?它换走的是什么成本
梯度累积常被当作OOM“急救药”,但它并非免费:仅降低单步显存峰值,却牺牲训练速度、梯度信号密度、优化器响应灵敏度与调参手感。它适合快速验证,却不适配长期精调——真正的瓶颈,往往不是显存,而是系统设计。
8080 和 3128 端口的核心区别及使用场景
HTTP代理常用端口8080与3128各有侧重:8080多用于管理监控(如Web配置界面),易记但可能被防火墙拦截;3128为标准端口,稳定性高,主供客户端正常请求转发。端口可自定义,需据安全与性能需求合理选用。
智能体来了!2026 AI 元年:在全新赛道上重构人类生产力边界
2026年被定义为“智能体元年”:AI从“能说”跃升为“能干”,实现自主决策、跨系统协作与具身执行。产业迎来智能体市场、数字劳动力网络和可信治理三大爆发点,人类角色转向目标设定与智能体调度。技术终指向人的升华。(239字)
智能体来了从 0 到 1:数据、工具与规则的协同范式
随着AI深入产业,单一模型已难支撑复杂流程。智能体作为以大模型为核心、融合数据(知识/记忆)、工具(执行接口)与规则(行为约束)的协同系统,实现感知—推理—执行闭环。其价值在于三者可复用、可治理的工程化协同,而非模型本身。
智启未来:2026年,AI从“技术工具”到“共生文明”的跨代元年
2026年,“会基础设施”范式跃迁开启人类与非生物智能共治的“第二个起源”。AI从工具升维为文明要素:技术迈入工业级确定性应用,能力下沉至个体;产业全链重构,制度启动动态合规、权责厘清与红利再分配;文明契约转向生态共生、意义赋予与思维共同体培育——未来在制度与共识之中。
大模型“驯化”指南:从人类偏好到专属AI,PPO与DPO谁是你的菜?
本文深入解析让AI“懂你”的关键技术——偏好对齐,对比PPO与DPO两种核心方法。PPO通过奖励模型间接优化,适合复杂场景;DPO则以对比学习直接训练,高效稳定,更适合大多数NLP任务。文章涵盖原理、实战步骤、评估方法及选型建议,并推荐从DPO入手、结合低代码平台快速验证。强调数据质量与迭代实践,助力开发者高效驯化大模型,实现个性化输出。
向量数据库技术内核:从存储到检索,拆解其高效运作的秘密
本文深入剖析向量数据库从存储到检索的工程实现,揭秘其高效运作的核心机制。不同于传统数据库,它通过近似最近邻(ANN)、向量压缩与分层索引(如HNSW)等技术,在高维空间中以“算得少”实现“查得快”。文章结合真实场景,揭示其本质:不是追求绝对精确,而是工程权衡下的极致优化,是AI时代数据检索的实用化落地。
用好代理 IP:加密付费拒绝免费陷阱
代理IP兼具隐私保护与安全风险,合规使用可防追踪、保障跨境业务,但非正规服务易致信息泄露、账号风控,甚至被用于违法活动。用户应选择加密付费代理,避开免费陷阱,遵守法规,强化安全防护,让技术真正服务于合法需求。
从原理到实操:大模型微调效果评估完全指南
微调大模型后如何判断效果?本文系统讲解评估核心方法:结合人工与自动化评估,覆盖通用能力与专项技能。通过明确目标、构建测试集、选用工具(如OpenCompass)、分析结果四步,打造完整评估体系。强调“对比”与“迭代”,助你避免灾难性遗忘,真实提升模型性能。
AI数字人技术厂商市场格局观察
AI数字人技术正从娱乐迈向多元实用场景,2024年市场规模达41.2亿元,增速超85%。世优科技深耕全栈技术,拥60余项专利,服务千余家品牌,助力政企智能化升级,推动行业向标准化、生态化发展。
当流量失效之后,企业真正的增长变量是什么?
“系统信任增长范式”提出:当流量红利消退,增长逻辑正从“获取用户”转向“积累可复用的信任资产”。信任不再是话语表达,而是跨时间、跨场景的行为一致性与可验证修复能力。企业需被系统判定为“值得持续推荐”,方能获得长期增长动力。这是一场规则层面的迁移,而非策略优化。
大模型应用开发中MCP与Function Call的关系与区别
MCP与Function Call是大模型应用中两大关键技术。前者为跨模型标准化通信协议,实现工具与模型解耦;后者是模型调用外部功能的内置机制。二者互补协作,推动AI应用向更开放、灵活、可扩展的方向发展。
详解RAG五种分块策略,技术原理、优劣对比与场景选型之道
RAG通过检索与生成结合,提升大模型在企业场景的准确性与安全性。分块策略是其核心,直接影响检索效果与答案质量。本文系统解析五种主流分块方法——固定大小、语义、递归、基于结构及LLM分块,对比优缺点与适用场景,助力构建高效、可靠的RAG系统。
让AI真正读懂长文本的秘密武器
通义实验室推出QwenLong-L1.5,基于Qwen3-30B-A3B打造的长文本推理专家。通过高质量多跳数据合成、稳定强化学习算法与突破窗口限制的记忆框架,系统性解决长文本“学不好、用不了”难题,在多跳推理、超长上下文等任务中媲美GPT-5与Gemini。
SpringCloud自定义注解
本文介绍Java自定义注解的实现与应用,结合Spring AOP与过滤器,演示日志处理、权限控制等场景。通过@Target、@Retention等元注解定义注解,并在Controller中结合AOP或拦截器实现登录验证等功能,提升代码可读性与复用性。(238字)
大模型伦理与公平性术语解释
大语言模型中的偏见、公平性、可解释性、安全对齐、人类对齐与隐私保护是AI伦理核心议题。偏见源于训练数据,导致性别、种族等歧视;公平性追求无差别对待,需技术与社会协同;可解释性提升模型透明度,增强信任;安全对齐防止有害输出;人类对齐确保价值观一致;隐私保护防范数据泄露。这些维度共同构成负责任AI的发展基石,需多学科协作持续优化,以实现安全、公正、可信的AI系统。
CNFANS模式淘宝1688代购系统搭建指南
CNFANS模式整合国内电商资源,对接淘宝、1688商品库,为海外用户提供代购、集运、物流清关等一站式服务。通过API打通电商平台、支付(PayPal/Stripe)、国际物流及仓储系统,实现商品采集、下单、支付、发货全流程自动化,解决海外用户“买不到、价格高”难题,提升跨境购物体验。(238字)
1688店铺详情API使用指南
1688店铺详情API是阿里巴巴开放平台核心接口,支持通过店铺ID获取商家基本信息、资质、等级及主营类目等数据,适用于电商分析、供应链对接等场景。本文详解接口参数、Python调用示例及注意事项,助开发者高效集成与应用。
开源项目分享:Gitee热榜项目 2025年12月第二周 周榜
本文档汇总Gitee本周热门开源项目,涵盖Fay、JeeLowCode等明星项目,结合AI与低代码趋势,深入分析技术融合与场景创新,助力开发者把握前沿动态。
1688买家/卖家店铺订单API接口指南
1688店铺订单API提供订单查询、详情获取、状态更新等功能,支持与ERP、CRM系统集成。可按条件筛选订单、获取商品及收货信息,同步发货与物流状态,并进行取消订单等操作。使用时需注意密钥授权、调用频率及异常处理,提升订单管理效率。

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。
