










阿里云大数据+AI技术沙龙上海站
EMR 团队在国内运营最大的 Spark 社区,为了更好地传播和分享业界最新技术和最佳实践,现在联合Intel及开源社区同行,打造一个纯粹的技术交流线下沙龙《大数据 + AI》,定期为大家做公益分享。首站上海开站,请猛戳链接报名!https://www.slidestalk.com/m/61
Flink 如何支持特征工程、在线学习、在线预测等 AI 场景?
人工智能应用场景中,Flink 在包括特征工程,在线学习,在线预测等方面都有一些独特优势,为了更好的支持人工智能的使用场景,Flink 社区以及各个生态都在努力。本文将介绍近期 Flink 在人工智能生态系统中的工作进展。
【译】用SQL统一所有:一种有效的、语法惯用的流和表管理方法
现在还没有一个统一的流式SQL语法标准,各家都在做自己的。本文在一些业界应用的基础上提出了一个统一SQL语法的建议。Spark同样存在这个问题,社区版本在流式SQL上迟迟没有动作。EMR Spark在今年上半年提供了自己设计版本的流式SQL支持,也会在后续的更新中吸收和支持这些优秀的设计建议。
#Apache spark系列技术直播# 第六讲【 What's New in Apache Spark 2.4? 】
Abstract(简介): This talk will provide an overview of the major features and enhancements in Spark 2.4 release and the upcoming releases and will be followed by a Q&A session.

学不动?Apache Member 教你评估实用技术的思路
是因为一项技术火,你才学的吗?是因为你老板决定用这项技术,你才学的吗?那你有没有想过为什么这项技术会火,为什么你老板决定用这项技术。今天我们就以 Flink 为例,来好好聊为什么要学习 Flink,以及如何看待一项新技术是否有潜力,希望对你有所启发。
EMR Spark Runtime Filter性能优化
Join是一个非常耗费资源耗费时间的操作,特别是数据量很大的情况下。一般流程上会涉及底层表的扫描/shuffle/Join等过程, 如果我们能够尽可能的在靠近源头上减少参与计算的数据,一方面可以提高查询性能,另一方面也可以减少资源的消耗(网络/IO/CPU等),在同样的资源的情况下可以支撑更多的查询。
HIVE TopN shuffle 原理
TopN 问题是排序中的一个经典问题。对于一个长度为 m 的数组,取其最大的 n (n

开源大数据生态下的 Flink 应用实践
11 月 28-30 日,Flink Forward Asia 邀请来自阿里巴巴、戴尔科技集团、英特尔、Cloudera、趣头条、百度、Stream Native 等不同方向的技术专家围绕 Apache Flink 核心大数据生态探讨当下大数据的发展趋势与未来动向,并展现相关技术在一线生产场景的优秀实践。
Flink 完美搭档:数据存储层上的 Pravega
本文将从大数据架构变迁历史,Pravega 简介,Pravega 进阶特性以及车联网使用场景这四个方面介绍 Pravega,重点介绍 DellEMC 为何要研发 Pravega,Pravega 解决了大数据处理平台的哪些痛点以及与 Flink 结合会碰撞出怎样的火花。
8月14日Spark社区直播【Spark Shuffle 优化】
本次直播介绍EMR Spark 在shuffle方面的相关优化工作,主要包含shuffle 优化的背景以及shuffle 优化的设计方案,最后会介绍Spark shuffle 在 TPC-DS测试中的性能数据
使用spark-redis组件访问云数据库Redis
本文演示了在Spark Shell中通过spark-redis组件读写Redis数据的场景。所有场景在阿里云E-MapReduce集群内完成,Redis使用阿里云数据库Redis
asd【文本分析】新闻分类aaa_2493
流控流控流控流控<br />数据源:<br />数据大小:261 KB<br />字段数量:3<br />使用组件:读数据表,类型转换,过滤与映射,增加序号列,合并列<br />
钉钉群直播【基于Spark实现的MLSQL如何帮助企业构建数据中台】
数据中台应该是什么样子?如何基于MLSQL完成数据中台的构建? MLSQL是如何基于Spark来完成这些扩展的? Databricks公司新开元项目Delta对于数据和机器学习的意义何在?
农业贷款预测的回归算法实现_0
iip<br />数据源:撒地方<br />数据大小:6.62 KB<br />字段数量:10<br />使用组件:读数据表,线性回归(旧),SQL脚本,过滤与映射,合并列<br />
重磅!Apache Flink 1.11 功能前瞻抢先看!
Flink 1.11 版本即将正式宣告发布!为满足大家的好奇与期待,我们邀请 Flink 核心开发者对 1.11 版本的功能特性进行解读与分享。Flink 1.11 在 1.10 的基础上对许多方面进行了完善和改进,并致力于进一步提高 Flink 的可用性及性能。
8月28日社区直播【Spark Streaming SQL流式处理简介】
本次直播将简要介绍EMR Spark Streaming SQL,主要包含Streaming SQL的语法和使用,最后做demo演示
test_multiEvaluation
实验名称实验名称实验名称<br />数据源:实验名称<br />数据大小:779 KB<br />字段数量:42<br />使用组件:读数据表<br />
从开发到生产上线,如何确定集群规划大小?
在 Flink 社区中,最常被问到的问题之一是:在从开发到生产上线的过程中如何确定集群的大小。这个问题的标准答案显然是“视情况而定”,但这并非一个有用的答案。本文概述了一系列的相关问题,通过回答这些问题,或许你能得出一些数字作为指导和参考。
心脏病预测案例_1480
分享到云栖社区<br />数据源:test<br />数据大小:7.49 KB<br />字段数量:15<br />使用组件:归一化,拆分,SQL脚本,读数据表,类型转换<br />
Multisim14.0中文下载安装步骤教程
Multisim14.0是由美国NI公司开发的EDA工具,适用于电路设计与仿真。本文提供详细中文安装步骤:下载安装包后解压,运行安装程序并设置路径,填写用户信息,选择安装位置,接受协议完成安装。随后安装NILicense激活器及中文语言包,最终实现软件汉化与正常运行。附带网盘下载链接,方便国内用户获取资源。

Spark Relational Cache实现亚秒级响应的交互式分析
阿里云E-MapReduce (EMR) 是构建在阿里云云服务器 ECS 上的开源 Hadoop、Spark、HBase、Hive、Flink 生态大数据 PaaS 产品。提供用户在云上使用开源技术建设数据仓库、离线批处理、在线流式处理、即时查询、机器学习等场景下的大数据解决方案。在2019杭州云栖大会大数据生态专场上,阿里巴巴技术专家王道远为大家分享了阿里云EMR的Spark Relational Cache实现亚秒级响应的交互式分析。
心脏病预测案例_1480
主要针对,心脏病预测,具体的场景具体访问中阐述<br />数据源:预测数据<br />数据大小:7.49 KB<br />字段数量:15<br />使用组件:归一化,拆分,SQL脚本,读数据表,类型转换<br />
钉钉群直播Spark + AI 北美峰会参会分享
Spark + AI 北美峰会 2019 盛况依然,这两天正如火如荼。大会的主题是 Build,Unify,Scale,对此如何理解?砖厂这次有哪些重磅消息和重要发布,并作如何解读?Spark 过去几年发展的基调和线索是什么,从这次峰会上又如何看出 Spark 在未来几年的发展端倪?阿里巴巴计算平台.
【推荐算法】商品推荐_3041
asdfsadf eee<br />数据源:<br />数据大小:328 KB<br />字段数量:4<br />使用组件:读数据表,SQL脚本,JOIN,过滤与映射<br />
【评分卡】信用卡消费分析_230
测试测试<br />数据源:<br />数据大小:1.36 MB<br />字段数量:25<br />使用组件:分箱,读数据表,评分卡预测,评分卡训练,拆分,样本稳定指数(PSI)<br />
如何在 Flink 中规划 RocksDB 内存容量?
本文将介绍跟 Flink 相关的一些 RocksDB 操作,并讨论一些提高资源利用率的重要配置。
CTR_GBDT_LR_TEST
实践分享:CTR中的GBDT+LR融合方案<br />数据源:internet<br />数据大小:770 KB<br />字段数量:20<br />使用组件:拆分,读数据表,特征编码<br />
【推荐算法】商品推荐_1450
测试一下功能<br />数据源:<br />数据大小:328 KB<br />字段数量:4<br />使用组件:过滤与映射,SQL脚本,读数据表,JOIN<br />
CTR_GBDT_LR
基于CTR的GBDT和LR方法融合<br />数据源:直播提供数据<br />数据大小:770 KB<br />字段数量:20<br />使用组件:拆分,读数据表,特征编码<br />
CTR_GBDT_LR_TEST
CTR中的GBDT+LR融合方案<br />数据源:internet<br />数据大小:770 KB<br />字段数量:20<br />使用组件:拆分,读数据表,特征编码<br />
Flink 与 Hive 的磨合期
在上篇文章中,笔者使用的 CDH 版本为 5.16.2,其中 Hive 版本为 1.1.0(CDH 5.x 系列 Hive 版本都不高于 1.1.0,是不是不可理解),Flink 源代码本身对 Hive 1.1.0 版本兼容性不好,存在不少问题。
雾霾天气预测_604
管网压力预测<br />数据源:<br />数据大小:37.3 KB<br />字段数量:7<br />使用组件:归一化,拆分,SQL脚本,读数据表,类型转换<br />
心脏病自传数据_07_03
心脏病自传数据预测<br />数据源:<br />数据大小:5.88 KB<br />字段数量:14<br />使用组件:读数据表<br />
心脏病预测案例_test_2455
test<br />数据源:<br />数据大小:7.49 KB<br />字段数量:15<br />使用组件:归一化,拆分,过滤式特征选择,SQL脚本,读数据表,类型转换<br />
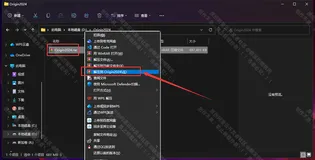
Origin2024 汉化安装专业解析|企业级部署教程+批量激活解决方案
Origin是一款由OriginLab开发的科学绘图与数据分析软件,支持Windows系统,提供丰富的2D/3D图形模板和强大的数据分析功能,如统计、信号处理、图像处理等。本文详细介绍Origin2024的下载与安装步骤,包括解压文件、运行安装程序、输入序列号、安装路径设置及破解方法,帮助用户快速完成软件安装与激活。
E-MapReduce产品探秘,扩展开源生态云上的能力
E-MapReduce的产品能力介绍,通过EMR来构建高效的云上大数据平台,优化云上的使用成本,更快的计算效率。
Miniconda 安装与环境配置全流程图解(2025 最新版)
Miniconda 可以看作是 Anaconda 的“轻装版”,只自带 conda 包管理器与基础的 Python 运行时。它体积小、部署速度快,特别适合按需创建与管理虚拟环境的用户。与 Anaconda 相比,Miniconda 不会预先安装一大堆科学计算库,你可以根据项目需求再单独选择、安装需要的包,因此整体更轻巧、更灵活。 本文将手把手演示在 Windows 下安装 Miniconda 的全过程:从下载安装器、完成向导配置、设置环境变量,到最后的基础验证与简单示例,帮助你迅速把 Miniconda 用起来。

8月14日Spark社区直播【Spark Shuffle 优化】
本次直播介绍EMR Spark 在shuffle方面的相关优化工作,主要包含shuffle 优化的背景以及shuffle 优化的设计方案,最后会介绍Spark shuffle 在 TPC-DS测试中的性能数据

Apache Flink 进阶(一):Runtime 核心机制剖析
本文主要介绍 Flink Runtime 的作业执行的核心机制。首先介绍 Flink Runtime 的整体架构以及 Job 的基本执行流程,然后介绍在这个过程,Flink 是怎么进行资源管理、作业调度以及错误恢复的。最后,本文还将简要介绍 Flink Runtime 层当前正在进行的一些工作。
Microsoft Activation Scripts v3.6 (MAS)激活工具安装教程!中文汉化版(激活工具)
Microsoft Activation Scripts v3.6(MAS)是一款开源、轻量级的批量激活工具,支持HWID、KMS38、TSforge等多种方式,可离线永久激活Win7至Win11及Office全系列。兼容旧系统如Vista,操作简单,无误报风险。
如何从 0 到 1 参与 Flink 社区?
本文首先介绍为何要参与开源社区以及在参与开源社区的过程中需要注意什么,然后重点介绍如何参与 Flink 社区以及在社区里面提交 PR 的整个流程。


普通电脑也能跑AI:10个8GB内存的小型本地LLM模型推荐
随着模型量化技术的发展,大语言模型(LLM)如今可在低配置设备上高效运行。本文介绍本地部署LLM的核心技术、主流工具及十大轻量级模型,探讨如何在8GB内存环境下实现高性能AI推理,涵盖数据隐私、成本控制与部署灵活性等优势。

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。
