









【AI大模型面试宝典二】— 基础架构篇
【AI大模型面试宝典】聚焦分词器核心考点!详解BPE、WordPiece、SentencePiece原理与实战,覆盖中文分词最佳实践、词汇表构建、特殊标记处理,助你轻松应对高频面试题,精准提升offer竞争力!
最近比较火的GEO适合哪些行业的推广?
GEO(生成式引擎优化)正重塑营销格局,通过优化内容结构与语义逻辑,抢占AI问答场景的引用权。据IDC与中国信通院数据,2025年全球市场规模超120亿美元,中国占55.4%。其在本地生活、跨境电商、文旅、房地产、教育、B2B制造及金融医疗等行业广泛应用,助力企业实现精准获客、提升转化率并构建长期数字资产,成为AI时代营销新基建。
2.部署篇(开发部署)
本文介绍如何将SpringCloud应用部署到Kubernetes云端。通过EDAS导入ACK集群,初始化应用并选择运行环境,开发者可利用IDE插件快速上传JAR/WAR包部署,提升开发效率。后续将讲解运维视角的自动化构建与部署流程。(238字)
超长String接收处理
Java中String变量最大长度为Integer.MAX_VALUE,但字符串字面量受class文件格式限制,最大65534。超过会编译错误,需通过StringBuilder分组处理长字符串。
卷积神经网络深度解析:从基础原理到实战应用的完整指南
蒋星熠Jaxonic带你深入卷积神经网络(CNN)核心技术,从生物启发到数学原理,详解ResNet、注意力机制与模型优化,探索视觉智能的演进之路。

从 Prompt 到 Parser:一次知乎采集的曲折经历
本文探讨了使用大模型和Playwright技术在知乎进行数据采集时遇到的挑战及其优化策略。初始方案因页面异步加载、DOM结构变化和限制策略而失败。为了提高数据采集的稳定性和可靠性,提出了增强渲染层、适配器层和回退监控机制的改进方案。通过这些改进,可以有效应对页面异步加载和DOM变化带来的问题,同时规避限制策略的影响,从而实现更高效、稳定的数据采集。

AMD Ryzen AI Max+ 395四机并联:大语言模型集群推理深度测试
本文介绍了使用四块Framework主板构建AI推理集群的过程,并基于AMD Ryzen AI Max+ 395处理器进行大语言模型推理性能测试,重点评估其并行推理能力及集群表现。
数据开发再提速!DataWorks正式接入Qwen3-Coder
阿里云DataWorks平台正式接入Qwen3-Coder模型,用户通过Copilot智能助手可实现自然语言交互生成代码,提升数据开发效率。支持SQL/Python代码生成、优化及Notebook文件创建,适用于数据分析与算法构建,助力企业高效开发。
自动驾驶还远吗?关键看“眼睛”
自动驾驶感知系统是智能车的“眼睛”,依赖摄像头、激光雷达、毫米波雷达等传感器实现环境感知。文章详解了感知架构、主流目标检测方法(如2D/3D检测、多传感器融合)、感知挑战(如极端天气、长尾问题)及发展趋势,并结合驭势科技实践,展示了数据闭环、BEV感知、全景分割等技术进展,推动自动驾驶向全天候、全无人目标迈进。
电脑进入bios关闭网卡的技巧
华硕电脑开机显示字符无法进入系统,提示“PXE-MOF:Exiting PXE ROM”,表明电脑正尝试从网卡启动。解决方法为进入BIOS关闭网卡启动功能。开机时连续按F2进入BIOS,切换至“Security”选项卡,找到“I/O Interface Security”设置,选择“LAN Network Interface”并设为“LOCKED”以禁用网卡启动,最后按F10保存退出即可。
Java 大视界 -- Java 大数据在智能家居能源消耗模式分析与节能策略制定中的应用(198)
简介:本文探讨Java大数据技术在智能家居能源消耗分析与节能策略中的应用。通过数据采集、存储与智能分析,构建能耗模型,挖掘用电模式,制定设备调度策略,实现节能目标。结合实际案例,展示Java大数据在智能家居节能中的关键作用。
淘宝API文档:淘宝商品详情API接口
淘宝商品详情API(taobao.item.get)为开发者提供获取商品信息的途径,涵盖基础信息、价格、图文、评价及物流等。适用于电商数据分析、比价平台与购物助手开发。本文提供Python调用示例,含请求构造与响应处理流程。

信息检索重排序技术深度解析:Cross-Encoders、ColBERT与大语言模型方法的实践对比
本文将深入分析三种主流的重排序技术:Cross-Encoders(交叉编码器)、ColBERT以及基于大语言模型的重排序器,并详细阐述各方案在实际应用中的性能表现、成本考量以及适用场景。
AI 搜索 MCP 最佳实践
本文介绍了如何通过 MCP 协议,快速调用阿里云 OpenSearch 、ElasticSearch 等工具,帮助企业快速集成工具链、降低开发复杂度、提升业务效率。

Chonkie:面向大语言模型的轻量级文本分块处理库
Chonkie是一个专为大语言模型(LLM)应用场景设计的轻量级文本分块处理库,提供高效的文本分割和管理解决方案。该库采用最小依赖设计理念,特别适用于现实世界的自然语言处理管道。本文将详细介绍Chonkie的核心功能、设计理念以及五种主要的文本分块策略。
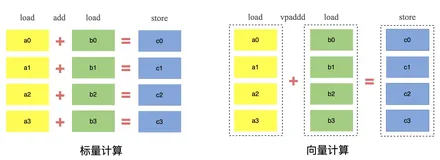
流批一体向量化引擎Flex
本文整理自蚂蚁集团技术专家刘勇在Flink Forward Asia 2024上的分享,聚焦流批一体向量化引擎的背景、架构及未来规划。内容涵盖向量化计算的基础原理(如SIMD指令)、现有技术现状,以及蚂蚁在Flink 1.18中引入的C++开发向量化计算实践。通过Flex引擎(基于Velox构建),实现比原生执行引擎更高的吞吐量和更低的成本。文章还详细介绍了功能性优化、正确性验证、易用性和稳定性建设,并展示了线上作业性能提升的具体数据(平均提升75%,最佳达14倍)。最后展望了未来规划,包括全新数据转换层、与Paimon结合及支持更多算子和SIMD函数。
婚恋交友相亲公众号app小程序系统源码「脱单神器」婚恋平台全套代码 - 支持快速二次开发
这是一套基于SpringBoot + Vue3开发的婚恋交友系统,支持微信公众号、Uniapp小程序和APP端。系统包含实名认证、智能匹配、视频相亲、会员体系等功能,适用于婚恋社交平台和相亲交友应用。后端采用SpringBoot 3.x与MyBatis-Plus,前端使用Vue3与Uniapp,支持快速部署和二次开发。适合技术团队或有经验的个人创业者使用。
两节锂电池保护芯片IC,PW7120在电路设计中的应用
1.两节锂电池保护芯片的工作原理 (1)过充保护:防止任何一节电池电压过高起火 (2)过放保护:防止任何一节电池电压过低损坏 (3)过流/短路保护:防止输出端短路或电流过大烧毁电池 2.两节锂电池保护板电路的要点 (1)为什么需要MOS管:(芯片是大脑,MOS管是肌肉,负责切断电流) 3.电路路径与连接方式 (1)电池连接顺序 (2)充电路径:充电电路+→P+/电池组+→电池组-→MOS管Q2→MOS管Q1→P-/充电电路 (3)放电路径:电池组-→MOS管Q2→MOS管Q1→P-/负载+/P+/电池组+ 4.与充电电路的组合 5.与均衡电路的组合
1949AI轻量化AI自动化:定时任务浏览器自动化+数据分发代码实战
基于1949AI轻量化理念,本工具以Python实现浏览器自动化采集、本地存储与飞书/邮箱双通道通知,全程无云依赖、低资源占用、安全合规,适配个人开发者及小型团队的轻量工程化需求。(239字)
数据智能引擎:从精准问数到深度分析的完整解决方案
数据智能引擎基于本体论,首创“精准问数+深度分析”双模式:技术专家可自然语言查数据,高管提方向性问题获自动洞察。多智能体协同、95%准确率、低门槛业务知识管理,赋能企业AI原生数据转型。(239字)
三节锂电池保护芯片电路攻略:PW7126设计要点与引脚功能
1,三节锂电池保护芯片的工作原理: ·过充保护:防正任何一节电池电压过高起火 ·过放保护:防止任何一节电池电压过低损坏 ·过流/短路保护:防止输出端短路或电流过大烧毁电池 2,三节锂电池保护板电路的要点 ·为什么需要MOS管:(芯片是大脑,MOS管是肌肉,负责切断电流) 3,电路路径与连接方式 ·电池接线顺序 ·充电路径:充电电路+一P+/电池组+一电池组-一MOS管O1一MOS管O2一采样电阻一P-/充电电路 ·放电路径:电池组-→MOS管Q2→P-/负载-→负载+/电池组+ 二、电路图 PW7126采用8引脚的SOP封装形式,PW7126是一款专用的三节可充电锂电池保护电路,它集高精度过电
SEP-YOLO:当频域分析遇上YOLO,透明物体实例分割迎来新突破,ISCAS 2026
本文提出SEP-YOLO框架,首创频域细节增强模块(可学习复数权重强化高频边界)、多尺度空间细化流(内容感知对齐+门控细化),并为Trans10K提供首个高质量实例标注。在Trans10K/GVD上mAP50超SOTA 3%+,兼顾精度与实时性。

PySpark入门教程(非常详细)从零基础入门到精通
本教程聚焦Spark Core核心原理,基于3.5.8版本,用Python详解RDD五大特性(分区、计算函数、依赖关系、分区器、首选位置)、容错机制、Shuffle、DAG调度及共享变量等,并通过WordCount实战演示。
京东商品详情 API(jd.item_get)
京东商品详情API(jd.item_get)是京东开放平台提供的标准化REST接口,支持获取商品标题、价格、库存、规格、促销及售后等全量信息,适用于数据采集、价格监控、比价工具及代购系统等场景。

RAG不只是问答!看完这些应用案例,才发现它的潜力这么大
RAG(检索增强生成)技术正赋能企业知识管理、智能客服、辅助决策、内容创作与教育培训等多元场景,通过语义检索+精准生成,提升信息获取效率与AI实用性,助力零代码构建专属智能系统。
1688宝贝详情数据接口实战—B 端视角下的竞品(供应商)数据拆解全指南
本指南面向B端企业,详解如何通过1688宝贝详情API实现竞品与供应商数据化拆解。涵盖API接入、字段商业价值映射(价格梯度、MOQ、SKU库存、资质认证、物流履约、销量反馈等)、实战分析框架及合规要点,助力跨境铺货、批发选品、定价优化与供应链决策,真正将API转化为业务增长引擎。(239字)

阿里云 OpenLake:AI 时代的全模态、多引擎、一体化解决方案深度解析
阿里云徐晟详解OpenLake:构建全模态、多引擎、一体化智能数据体系,融合大数据与AI,支持湖仓一体、Agentic Data及AI搜索,助力企业降本增效、加速AI落地。(239字)
2026年 智能体来了!什么是 AI 智能体工程化?为什么金加德强调 Workflow + Code 才能真正落地?
AI智能体工程化是将AI从聊天工具升级为“数字员工”,通过流程编排(Workflow)、代码逻辑(Code)与知识增强(RAG),让其稳定执行重复性业务流程,实现可复用、可落地的自动化生产。
什么是 Code 39?
Code 39是1974年由Intermec开发的字母数字条形码,支持43个字符,广泛用于汽车、医疗、国防等领域。分Regular和Full ASCII两种,后者可编码全部128个ASCII字符。结构简单,自校验强,但密度较低。可通过HCreateLabelView轻松生成,适用于非零售场景。
大模型专业名词解释手册
本手册由油炸小波设计提示词、Manus创作,系统梳理大语言模型核心概念,涵盖基础原理、训练技术、优化压缩、推理应用、评估调试及伦理安全六大模块,深入浅出解析LLM关键技术术语。
大模型训练方法与技术术语解释
预训练、微调、RLHF、思维链等技术共同推动大模型发展。预训练构建语言基础,微调适配特定任务,RLHF融入人类偏好,思维链提升推理能力,少样本与零样本实现快速迁移,指令微调增强指令理解,自监督学习利用海量无标数据,温度控制生成风格,蒸馏压缩模型规模,缩放定律指导模型扩展,全面提升大模型理解、生成与泛化能力。
详解RAG五种分块策略,技术原理、优劣对比与场景选型之道
RAG通过检索与生成结合,提升大模型在企业场景的准确性与安全性。分块策略是其核心,直接影响检索效果与回答质量。本文系统解析五种主流分块方法:固定大小、语义、递归、基于文档结构及LLM分块,对比其优缺点与适用场景,并提出组合优化路径,助力构建高效、可信的RAG系统。
虚拟机安装(CentOS7)
准备CentOS7镜像及VMware Workstation(可从百度云下载),提取码已提供。使用VMware创建虚拟机,参考指定教程完成安装。默认登录用户为root,密码由用户自设。确保电脑配置满足运行需求。(238字)
用 Python 实现 MySQL 数据库定时自动备份
本文介绍如何用Python脚本实现MySQL数据库的自动化备份。通过调用`mysqldump`工具,结合时间戳命名、文件压缩与定时任务(如crontab),可轻松实现“无人值守”备份。涵盖配置修改、安全建议及日志管理,提升备份效率与可靠性,适用于日常开发与生产环境。
1688关键字搜索工厂数据API使用指南
1688工厂数据接口支持通过关键词与多维度筛选(地区、类型、实力等)获取供应商核心信息,涵盖资质、产能、经营等20余项字段,助力产业带分析、源头直采与供应链调研,适用于电商选品、跨境 sourcing 等场景。
Python | 贝叶斯搜索参数优化的XGBoost+SHAP可解释性分析回归预测及可视化算法
本教程将推出Python实现的XGBoost贝叶斯调参+SHAP可解释性分析与可视化,涵盖数据应用、算法原理及SHAP理论,助力SCI论文提升模型可解释性,附完整代码与环境配置指南。

流、表与“二元性”的幻象
本文探讨流与表的“二元性”本质,指出实现该特性需具备主键、变更日志语义和物化能力。强调Kafka与Iceberg因缺乏更新语义和主键支持,无法真正实现二元性,唯有统一系统如Flink、Paimon或Fluss才能无缝融合流与表。
2025 ChatBI 产品选型推荐:智能问数+归因分析+报告生成
当企业站在 ChatBI 选型的十字路口,技术架构的先进性、场景适配的完整性、落地实践的可验证性应成为核心考量标准。
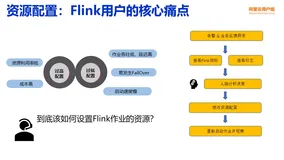
Flink 智能调优:从人工运维到自动化的实践之路
本文由阿里云Flink产品专家黄睿撰写,基于平台实践经验,深入解析流计算作业资源调优难题。针对人工调优效率低、业务波动影响大等挑战,介绍Flink自动调优架构设计,涵盖监控、定时、智能三种模式,并融合混合计费实现成本优化。展望未来AI化方向,推动运维智能化升级。
理想汽车基于 Hologres + Flink 构建万亿级车联网信号实时分析平台
理想汽车携手阿里云Hologres+Flink,打造万亿级车联网实时分析平台。面对百万余辆智能车、每秒百万级信号上报的挑战,通过存算分离、冷热分层、流批一体等创新,实现写入性能提升200%、查询QPS超万、成本降低40%,支撑数字孪生、智能诊断等高实时业务,构建高可用、弹性伸缩、低成本的下一代数据底座。
基于python大数据的台风灾害分析及预测系统
针对台风灾害预警滞后、精度不足等问题,本研究基于Python与大数据技术,构建多源数据融合的台风预测系统。利用机器学习提升路径与强度预测准确率,结合Django框架实现动态可视化与实时预警,为防灾决策提供科学支持,显著提高应急响应效率,具有重要社会经济价值。
基于MVO多元宇宙优化的DBSCAN聚类算法matlab仿真
本程序基于MATLAB实现MVO优化的DBSCAN聚类算法,通过多元宇宙优化自动搜索最优参数Eps与MinPts,提升聚类精度。对比传统DBSCAN,MVO-DBSCAN有效克服参数依赖问题,适应复杂数据分布,增强鲁棒性,适用于非均匀密度数据集的高效聚类分析。
企业级 AI 模型无代码落地指南:基于阿里云工具链,从 0 到 1 实现业务价值
某汽车零部件厂商通过阿里云PAI、OSS等工具,实现无代码AI质检落地:仅用控制台操作完成数据治理到部署,质检效率提升3倍,模型周期从2月缩至2周。本文详解全栈可视化方案,助力企业零代码落地AI。

LLM + 抓取:让学术文献检索更聪明
结合爬虫与大模型,打造懂语义的学术检索助手:自动抓取最新NLP+爬虫论文,经清洗、向量化与RAG增强,由LLM提炼贡献,告别关键词匹配,实现精准智能问答。

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。
