









一文读懂云服务器:工作原理与核心作用
云服务器通过虚拟化与分布式技术,将物理服务器集群转化为按需分配的弹性计算资源,解决资源浪费、降低部署门槛。支撑个人开发、企业运维及AI、直播、政务等千行百业,是数字经济的核心基础设施。
爬虫项目该选 Python 还是 Golang?看这篇就够了
本文对比Python与Golang在爬虫开发中的七大维度:语法简洁性、第三方库丰富度(如Scrapy vs Colly)、并发性能(Goroutine vs GIL限制)、内存占用、代码可读性、数据处理能力(Pandas等优势)及部署便捷性(Go可直接编译为跨平台二进制),助你按需选型。

让ChatGPT更懂你:深入浅出解析大模型微调中的强化学习(PPO/DPO篇)
本文深入浅出解析大模型对齐人类偏好的两大核心方法:PPO(需训练奖励模型、在线优化,强但复杂)与DPO(直接学习“好vs差”对比数据、离线高效、更易用)。对比原理、流程与实践,揭示为何DPO正成为主流选择,并强调高质量偏好数据与平台化工具的关键价值。(239字)
京东商品详情 API(jd.item_get)
京东商品详情API(jd.item_get)是京东开放平台提供的标准化REST接口,支持获取商品标题、价格、库存、规格、促销及售后等全量信息,适用于数据采集、价格监控、比价工具及代购系统等场景。
Opus 4.5、GPT-5.2 与 Gemini 3 Pro:企业级场景下的大模型工程表现对比
本文从工程与生产视角,对比Opus 4.5、GPT-5.2、Gemini 3 Pro三款大模型在输出一致性、可控性、长上下文、接口确定性等维度的表现,强调企业级AI选型应重稳定性与系统友好度,而非单纯比拼能力。
向量数据库实战:从“看起来能用”到“真的能用”,中间隔着一堆坑
本文揭示向量数据库实战的七大关键陷阱:选型前需明确业务本质(模糊匹配 or 精确查询?);embedding 比数据库本身更重要,决定语义“世界观”;文档切分是核心工程,非辅助步骤;建库成功≠可用,TopK 准确率会随数据演进失效;“相似但不可用”是常态,必须引入 rerank;需建立可追溯的bad case排查路径;向量库是长期系统,非一次性组件。核心结论:难在“用对”,不在“用上”。
为什么 ES 的搜索结果只到 10,000?强制“数清楚”的代价有多大
Elasticsearch 7.x后默认返回10,000总数,实为Block-Max WAND算法的性能优化——跳过低分文档块以提升查询速度。强行开启`track_total_hits:true`将禁用该优化,导致CPU飙升、延迟激增。本文深入Lucene底层,解析其原理、陷阱与治理方案。
别再刷短视频了!你的赛博替身正在工厂拧螺丝:揭秘 AI Agent 搭建师
本文揭秘AI Agent搭建师这一新兴职业:不教人用AI,而是教人“克隆”24小时在线、永不摸鱼的数字分身。涵盖认知架构、提示词工程、RAG增强、自动化流、工具调用、自主循环、记忆持久化等12大核心能力,揭示如何将AI从聊天机器人升级为可落地的“数字合伙人”。
别光“调戏”ChatGPT了!亲手微调一个专属大模型,你需要知道这些
本文深入浅出地讲解大模型“训练-微调-推理”三步法,类比医生培养过程,帮助读者理解AI如何从通才变为专才。涵盖技术原理、实操步骤、效果评估与GPU选型,助力个人与企业打造专属AI模型,推动AI应用落地。
【AI大模型面试宝典七】- 训练优化篇
【AI大模型面试宝典】详解知识蒸馏:从软标签、温度机制到特征对齐,涵盖KL散度、黑/白盒蒸馏策略与代码实现,拆解高频面试题,助你精准掌握大模型压缩核心考点,轻松应对技术追问,offer拿到手软!
最近比较火的GEO适合哪些行业的推广?
GEO(生成式引擎优化)正重塑营销格局,通过优化内容结构与语义逻辑,抢占AI问答场景的引用权。据IDC与中国信通院数据,2025年全球市场规模超120亿美元,中国占55.4%。其在本地生活、跨境电商、文旅、房地产、教育、B2B制造及金融医疗等行业广泛应用,助力企业实现精准获客、提升转化率并构建长期数字资产,成为AI时代营销新基建。
什么是 Code 39?
Code 39是1974年由Intermec开发的字母数字条形码,支持43个字符,广泛用于汽车、医疗、国防等领域。分Regular和Full ASCII两种,后者可编码全部128个ASCII字符。结构简单,自校验强,但密度较低。可通过HCreateLabelView轻松生成,适用于非零售场景。
2.部署篇(开发部署)
本文介绍如何将SpringCloud应用部署到Kubernetes云端。通过EDAS导入ACK集群,初始化应用并选择运行环境,开发者可利用IDE插件快速上传JAR/WAR包部署,提升开发效率。后续将讲解运维视角的自动化构建与部署流程。(238字)
超长String接收处理
Java中String变量最大长度为Integer.MAX_VALUE,但字符串字面量受class文件格式限制,最大65534。超过会编译错误,需通过StringBuilder分组处理长字符串。
卷积神经网络深度解析:从基础原理到实战应用的完整指南
蒋星熠Jaxonic带你深入卷积神经网络(CNN)核心技术,从生物启发到数学原理,详解ResNet、注意力机制与模型优化,探索视觉智能的演进之路。

从 Prompt 到 Parser:一次知乎采集的曲折经历
本文探讨了使用大模型和Playwright技术在知乎进行数据采集时遇到的挑战及其优化策略。初始方案因页面异步加载、DOM结构变化和限制策略而失败。为了提高数据采集的稳定性和可靠性,提出了增强渲染层、适配器层和回退监控机制的改进方案。通过这些改进,可以有效应对页面异步加载和DOM变化带来的问题,同时规避限制策略的影响,从而实现更高效、稳定的数据采集。

AMD Ryzen AI Max+ 395四机并联:大语言模型集群推理深度测试
本文介绍了使用四块Framework主板构建AI推理集群的过程,并基于AMD Ryzen AI Max+ 395处理器进行大语言模型推理性能测试,重点评估其并行推理能力及集群表现。
数据开发再提速!DataWorks正式接入Qwen3-Coder
阿里云DataWorks平台正式接入Qwen3-Coder模型,用户通过Copilot智能助手可实现自然语言交互生成代码,提升数据开发效率。支持SQL/Python代码生成、优化及Notebook文件创建,适用于数据分析与算法构建,助力企业高效开发。
自动驾驶还远吗?关键看“眼睛”
自动驾驶感知系统是智能车的“眼睛”,依赖摄像头、激光雷达、毫米波雷达等传感器实现环境感知。文章详解了感知架构、主流目标检测方法(如2D/3D检测、多传感器融合)、感知挑战(如极端天气、长尾问题)及发展趋势,并结合驭势科技实践,展示了数据闭环、BEV感知、全景分割等技术进展,推动自动驾驶向全天候、全无人目标迈进。
Java 大视界 -- Java 大数据在智能家居能源消耗模式分析与节能策略制定中的应用(198)
简介:本文探讨Java大数据技术在智能家居能源消耗分析与节能策略中的应用。通过数据采集、存储与智能分析,构建能耗模型,挖掘用电模式,制定设备调度策略,实现节能目标。结合实际案例,展示Java大数据在智能家居节能中的关键作用。
Post-Training on PAI (4):模型微调SFT、DPO、GRPO
阿里云人工智能平台 PAI 提供了完整的模型微调产品能力,支持 监督微调(SFT)、偏好对齐(DPO)、强化学习微调(GRPO) 等业界常用模型微调训练方式。根据客户需求及代码能力层级,分别提供了 PAI-Model Gallery 一键微调、PAI-DSW Notebook 编程微调、PAI-DLC 容器化任务微调的全套产品功能。
淘宝API文档:淘宝商品详情API接口
淘宝商品详情API(taobao.item.get)为开发者提供获取商品信息的途径,涵盖基础信息、价格、图文、评价及物流等。适用于电商数据分析、比价平台与购物助手开发。本文提供Python调用示例,含请求构造与响应处理流程。

信息检索重排序技术深度解析:Cross-Encoders、ColBERT与大语言模型方法的实践对比
本文将深入分析三种主流的重排序技术:Cross-Encoders(交叉编码器)、ColBERT以及基于大语言模型的重排序器,并详细阐述各方案在实际应用中的性能表现、成本考量以及适用场景。
AI 搜索 MCP 最佳实践
本文介绍了如何通过 MCP 协议,快速调用阿里云 OpenSearch 、ElasticSearch 等工具,帮助企业快速集成工具链、降低开发复杂度、提升业务效率。

Chonkie:面向大语言模型的轻量级文本分块处理库
Chonkie是一个专为大语言模型(LLM)应用场景设计的轻量级文本分块处理库,提供高效的文本分割和管理解决方案。该库采用最小依赖设计理念,特别适用于现实世界的自然语言处理管道。本文将详细介绍Chonkie的核心功能、设计理念以及五种主要的文本分块策略。
流批一体向量化引擎Flex
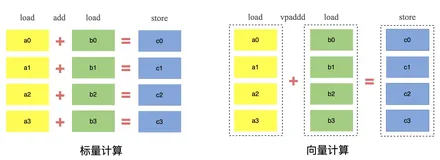
本文整理自蚂蚁集团技术专家刘勇在Flink Forward Asia 2024上的分享,聚焦流批一体向量化引擎的背景、架构及未来规划。内容涵盖向量化计算的基础原理(如SIMD指令)、现有技术现状,以及蚂蚁在Flink 1.18中引入的C++开发向量化计算实践。通过Flex引擎(基于Velox构建),实现比原生执行引擎更高的吞吐量和更低的成本。文章还详细介绍了功能性优化、正确性验证、易用性和稳定性建设,并展示了线上作业性能提升的具体数据(平均提升75%,最佳达14倍)。最后展望了未来规划,包括全新数据转换层、与Paimon结合及支持更多算子和SIMD函数。
婚恋交友相亲公众号app小程序系统源码「脱单神器」婚恋平台全套代码 - 支持快速二次开发
这是一套基于SpringBoot + Vue3开发的婚恋交友系统,支持微信公众号、Uniapp小程序和APP端。系统包含实名认证、智能匹配、视频相亲、会员体系等功能,适用于婚恋社交平台和相亲交友应用。后端采用SpringBoot 3.x与MyBatis-Plus,前端使用Vue3与Uniapp,支持快速部署和二次开发。适合技术团队或有经验的个人创业者使用。

构建智能AI记忆系统:多智能体系统记忆机制的设计与技术实现
本文探讨了多智能体系统中记忆机制的设计与实现,提出构建精细化记忆体系以模拟人类认知过程。文章分析了上下文窗口限制的技术挑战,并介绍了四种记忆类型:即时工作记忆、情节记忆、程序性记忆和语义知识系统。通过基于文件的工作上下文记忆、模型上下文协议的数据库集成以及RAG系统等技术方案,满足不同记忆需求。此外,高级技术如动态示例选择、记忆蒸馏和冲突解决机制进一步提升系统智能化水平。总结指出,这些技术推动智能体向更接近人类认知的复杂记忆处理机制发展,为人工智能开辟新路径。
体育直播网站如何实现实时数据
体育直播中的实时数据如何快速、准确地传递到用户手机上?本文揭秘了这一过程:数据来源包括官方合作伙伴和AI+人工双保险;传输借助WebSocket、MQTT协议及CDN加速;高并发通过Redis缓存、消息队列与自动扩容解决。未来,AI+5G将推动实时数据向更低延迟发展,甚至实现赛事预测。代码示例展示了比赛数据处理逻辑,确保用户获得精准信息。

鹰角网络:EMR Serverless Spark 在《明日方舟》游戏业务的应用
鹰角网络为应对游戏业务高频活动带来的数据潮汐、资源弹性及稳定性需求,采用阿里云 EMR Serverless Spark 替代原有架构。迁移后实现研发效率提升,支持业务快速发展、计算效率提升,增强SLA保障,稳定性提升,降低运维成本,并支撑全球化数据架构部署。
Python 实战:用 API 接口批量抓取小红书笔记评论,解锁数据采集新姿势
小红书作为社交电商的重要平台,其笔记评论蕴含丰富市场洞察与用户反馈。本文介绍的小红书笔记评论API,可获取指定笔记的评论详情(如内容、点赞数等),支持分页与身份认证。开发者可通过HTTP请求提取数据,以JSON格式返回。附Python调用示例代码,帮助快速上手分析用户互动数据,优化品牌策略与用户体验。
智能体Agent解析:用自然语言重构数据开发工作方式
大数据开发治理平台DataWorks基于MCP协议,正式发布了DataWorks Agent,内置DataWorks MCP Server V1.0。该功能支持在DataWorks Data Studio中通过自然语言交互完成数据开发任务,实现了需求即代码的开发体验。本文将详细介绍如何通过配置使用DataWorks MCP Server进行任务的开发和运维管理。
体育应用怎么通过API接口接入数据源与直播源
本文介绍了体育类应用接入数据源与直播源的API接口方案。主要包括:1) 数据源API接入,涉及选择提供商、接入流程及常见数据类型;2) 直播源接入,涵盖直播源类型、提供商和技术方案;3) 技术实现要点,如数据缓存、实时更新机制和安全性考虑;4) 成本优化建议。附有HLS播放示例及Node.js完整集成代码,帮助开发者高效实现体育应用功能。
金融数据分析:解析JavaScript渲染的隐藏表格
本文详解了如何使用Python与Selenium结合代理IP技术,从金融网站(如东方财富网)抓取由JavaScript渲染的隐藏表格数据。内容涵盖环境搭建、代理配置、模拟用户行为、数据解析与分析等关键步骤。通过设置Cookie和User-Agent,突破反爬机制;借助Selenium等待页面渲染,精准定位动态数据。同时,提供了常见错误解决方案及延伸练习,帮助读者掌握金融数据采集的核心技能,为投资决策提供支持。注意规避动态加载、代理验证及元素定位等潜在陷阱,确保数据抓取高效稳定。
基于 Megatron 的多模态大模型训练加速技术解析
Pai-Megatron-Patch 是一款由阿里云人工智能平台PAI 研发的围绕英伟达 Megatron 的大模型训练配套工具,旨在帮助开发者快速上手大模型,打通大模型相关的高效分布式训练、有监督指令微调、下游任务评估等大模型开发链路。本文以 Qwen2-VL 为例,从易用性和训练性能优化两个方面介绍基于 Megatron 构建的 Pai-Megatron-Patch 多模态大模型训练的关键技术
微信公众号接口测试实战指南
微信公众号接口测试是确保系统稳定性和功能完整性的重要环节。本文详细介绍了测试全流程,包括准备、工具选择(如Postman、JMeter)、用例设计与执行,以及常见问题的解决方法。通过全面测试,可以提前发现潜在问题,优化用户体验,确保公众号上线后稳定运行。内容涵盖基础接口、高级接口、微信支付和数据统计接口的测试,强调了功能验证、性能优化、安全保护及用户体验的重要性。未来,随着微信生态的发展,接口测试将面临更多挑战和机遇,如小程序融合、AI应用和国际化拓展。

FastAPI与Selenium:打造高效的Web数据抓取服务 —— 采集Pixabay中的图片及相关信息
本文介绍了如何使用FastAPI和Selenium搭建RESTful接口,访问免版权图片网站Pixabay并采集图片及其描述信息。通过配置代理IP、User-Agent和Cookie,提高爬虫的稳定性和防封禁能力。环境依赖包括FastAPI、Uvicorn和Selenium等库。代码示例展示了完整的实现过程,涵盖代理设置、浏览器模拟及数据提取,并提供了详细的中文注释。适用于需要高效、稳定的Web数据抓取服务的开发者。
很火的DeepSeek到底是什么
DeepSeek,全称杭州深度求索人工智能基础技术研究有限公司,成立于2023年。因推出开源 AI 模型 DeepSeek-R1 而引起了广泛关注。与ChatGPT相比,大幅降低了推理模型的成本。
Druid 架构原理及核心特性详解
Druid 是一个分布式、支持实时多维OLAP分析的列式存储数据处理系统,适用于高速实时数据读取和灵活的多维数据分析。它通过Segment、Datasource等元数据概念管理数据,并依赖Zookeeper、Hadoop和Kafka等组件实现高可用性和扩展性。Druid采用列式存储、并行计算和预计算等技术优化查询性能,支持离线和实时数据分析。尽管其存储成本较高且查询语言功能有限,但在大数据实时分析领域表现出色。
Flink 三种时间窗口、窗口处理函数使用及案例
Flink 是处理无界数据流的强大工具,提供了丰富的窗口机制。本文介绍了三种时间窗口(滚动窗口、滑动窗口和会话窗口)及其使用方法,包括时间窗口的概念、窗口处理函数的使用和实际案例。通过这些机制,可以灵活地对数据流进行分析和计算,满足不同的业务需求。

使用PaliGemma2构建多模态目标检测系统:从架构设计到性能优化的技术实践指南
本文详细介绍了PaliGemma2模型的微调流程及其在目标检测任务中的应用。PaliGemma2通过整合SigLIP-So400m视觉编码器与Gemma 2系列语言模型,实现了多模态数据的高效处理。文章涵盖了开发环境构建、数据集预处理、模型初始化与配置、数据加载系统实现、模型微调、推理与评估系统以及性能分析与优化策略等内容。特别强调了计算资源优化、训练过程监控和自动化优化流程的重要性,为机器学习工程师和研究人员提供了系统化的技术方案。
如何使用Python开发1688商品详情API接口?
本文介绍了如何使用Python开发1688商品详情API接口,获取商品的标题、价格、销量和评价等详细信息。主要内容包括注册1688开放平台账号、安装必要Python模块、了解API接口、生成签名、编写Python代码、解析返回数据以及错误处理和日志记录。通过这些步骤,开发者可以轻松地集成1688商品数据到自己的应用中。

基于prim算法求出网络最小生成树实现网络社团划分和规划
该程序使用MATLAB 2022a版实现路线规划,通过排序节点权值并运用Prim算法生成最小生成树完成网络规划。程序基于TSP问题,采用遗传算法与粒子群优化算法进行路径优化。遗传算法通过编码、选择、交叉及变异操作迭代寻优;粒子群优化算法则通过模拟鸟群觅食行为,更新粒子速度和位置以寻找最优解。

数据准备指南:10种基础特征工程方法的实战教程
在数据分析和机器学习中,从原始数据中提取有价值的信息至关重要。本文详细介绍了十种基础特征工程技术,包括数据插补、数据分箱、对数变换、数据缩放、One-Hot编码、目标编码、主成分分析(PCA)、特征聚合、TF-IDF 和文本嵌入。每种技术都有具体应用场景和实现示例,帮助读者更好地理解和应用这些方法。通过合理的特征工程,可以显著提升模型的性能和预测能力。

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。
