









大模型产生幻觉的原因,如何解决?
大模型“幻觉”指AI生成看似合理但错误或虚构的信息,源于其概率预测机制、训练数据缺陷及缺乏事实核查能力。可通过RAG、微调、联网检索、自我核查等方法降低幻觉风险,提升输出准确性与可靠性。(238字)
长文详解|DataWorks Data+AI一体化开发实战图谱
DataWorks是一站式智能大数据开发治理平台,内置阿里巴巴15年大数据建设方法论,深度适配阿里云MaxCompute、EMR、Hologres、Flink、PAI 等数十种大数据和AI计算服务,为数仓、数据湖、OpenLake湖仓一体数据架构提供智能化ETL开发、数据分析与主动式数据资产治理服务,助力“Data+AI”全生命周期的数据管理。
GEO怎么做?从0开始的五步法
GEO怎么做?从0开始的五步法:先搞懂GEO是什么(让AI在回答时提到你),再选对平台(公众号、问一问、知乎、搜狐号、小红书),然后写AI友好的内容(开头给结论、小标题分段、结尾加FAQ),发出去等收录,最后测效果优化。0成本起步,边学边做。我是二二得四,正在从头学GEO。

反爬虫机制深度解析:从基础防御到高级对抗的完整技术实战
本文系统阐述了反爬虫技术的演进与实践,涵盖基础IP限制、User-Agent检测,到验证码、行为分析及AI智能识别等多层防御体系,结合代码实例与架构图,全面解析爬虫攻防博弈,并展望智能化、合规化的发展趋势。
CDNJS/UNPKG/JSDelivr 太慢用不了,换成这些国内高速镜像
npm cdn, cdnjs, unpkg, jsdelivr, zstatic, zstatic.net, s4.zstatic.net
普通人也能用的 AI 自动化 OpenClaw 配置方法(附下载 + 问题解决)
OpenClaw(小龙虾AI)是2026年热门的本地化AI自动化工具,无需联网或账号,用自然语言即可实现键鼠控制、文件处理、浏览器操作等,大幅提升办公效率。Win11一键部署,全程自动安装,支持纯离线运行。
从入门到选型:GEO生成式引擎优化科普与优质geo优化服务商推荐
GEO(生成式引擎优化)正取代SEO,助力企业在AI搜索中抢占流量先机。本文解析GEO核心逻辑,对比SEO差异,揭示其提升获客效率2.8倍的潜力,并结合国内外权威数据,分场景推荐适配的优质服务商,助企业从懂原理到会选型,规避布局风险。
【若依Java】15分钟玩转若依二次开发,新手小白半小时实现前后端分离项目,springboot+vue3+Element Plus+vite实现Java项目和管理后台网站功能
摘要: 本文档详细介绍了如何使用若依框架快速搭建一个基于SpringBoot和Vue3的前后端分离的Java管理后台。教程涵盖了技术点、准备工作、启动项目、自动生成代码、数据库配置、菜单管理、代码下载和导入、自定义主题样式、代码生成、启动Vue3项目、修改代码、以及对代码进行自定义和扩展,例如单表和主子表的代码生成、树形表的实现、商品列表和分类列表的改造等。整个过程详细地指导了如何从下载项目到配置数据库,再到生成Java和Vue3代码,最后实现前后端的运行和功能定制。此外,还提供了关于软件安装、环境变量配置和代码自动生成的注意事项。

Flink CDC+Kafka 加速业务实时化
阿里巴巴开发工程师,Apache Flink Committer 任庆盛,在 9 月 24 日 Apache Flink Meetup 的分享。
DataWorks Data Agent:一句话搞定数据开发,让周期从天级到分钟级
DataWorks Data Agent 是阿里云推出的AI原生数据开发智能体,覆盖集成、开发、运维、治理、分析全链路。它深度适配业务逻辑与开发规范,支持自然语言一键生成可信SQL及全流程交付。淘宝闪购实测:指标开发从6–8小时缩短至5–10分钟,真正实现“一句话交付”。

Flink CDC 3.6.0:支持 Flink 1.20/2.2, MySQL/PostgreSQL入湖入流支持Schema Evolution
Apache Flink CDC 3.6.0 正式发布!支持 Flink 1.20.x/2.2.x 与 JDK 11,增强端到端 Schema Evolution(MySQL/PostgreSQL 入湖入流),新增 Oracle Source 与 Hudi Sink 连接器,全面覆盖主流数据湖生态,并优化 Transform 框架、YAML 路由及多连接器能力。(239字)

从零构建能自我优化的AI Agent:Reflection和Reflexion机制对比详解与实现
AI能否从错误中学习?Reflection与Reflexion Agent通过生成-反思-改进循环,实现自我优化。前者侧重内容精炼,后者结合外部研究提升准确性,二者分别适用于创意优化与知识密集型任务。
PAI-Rec 多路召回截断实践:用 PriorityAdjustCountFilter 和 SnakeFilter 控制精排入口数量
PAI-Rec推荐开发平台提供PriorityAdjustCountFilter(按优先级截取)与SnakeFilter(按权重蛇形交错)两种多路召回截断策略,无需粗排即可将数百候选精准压缩至200个以内进入精排,兼顾保量性、多样性与业务可控性。
如何将Kindle电子书下载到电脑:技术流程与操作解析
随着数字阅读兴起,Kindle成为主流电子书平台。然而,Amazon的封闭生态和DRM限制,使用户难以灵活管理书籍。本文从技术角度出发,讲解如何合法下载Kindle电子书至电脑,包括使用Kindle for PC、USB导出及进阶方案(如Android模拟器、WINE环境)。同时介绍文件格式处理、自动化备份与阅读体验优化方法,并强调版权合规的重要性,助您构建个人数字图书馆。

解锁3D创作新姿势!Autodesk 3ds Max 2022中文版安装教程(附官方下载渠道)
Autodesk 3ds Max 2022 是一款专业三维建模、动画和渲染软件,广泛应用于影视、游戏、建筑等领域。其特点包括智能建模工具、高效Arnold渲染引擎、跨平台协作及多语言支持。安装需满足Win10/11系统、i5以上处理器、8GB内存等要求。正版安装流程包括下载官方程序、配置组件、激活许可证并验证功能。常见问题如安装失败、中文乱码等提供了解决方案。扩展学习资源推荐Forest Pack、V-Ray等插件,助力用户深入掌握软件功能。
API和SDK的区别
API 和 SDK 的区别在于:API 是一组定义了软件组件之间交互规范的接口,用于实现不同软件组件之间的通信;而 SDK 是一个全面的工具集合,包含 API、编译器、调试器、文档等,用于特定平台的应用程序开发。SDK 范围更广,内容更丰富,更具体和具象化,适合复杂的开发需求;API 则更加抽象,侧重于功能的定义和调用方式。
Druid、ClickHouse、Doris、StarRocks 的区别与分析
本文对比了 Druid、ClickHouse、Doris 和 StarRocks 四款大数据分析引擎。它们均为 OLAP 引擎,采用列式存储和分布式架构,适用于海量数据分析。Druid 擅长实时分析与高并发查询;ClickHouse 以超高性能著称,适合复杂查询;Doris 提供易用的 SQL 接口,性能均衡;StarRocks 则以其极速查询和实时更新能力脱颖而出。各引擎在数据模型、查询性能、数据更新和存储方面存在差异,适用于不同的业务场景。选择时需根据具体需求综合考虑。
Markdown是什么?——AI时代最值得掌握的文档语言
在AI处理信息成为常态的今天,文档格式的竞争已从“人类看着美”转向“机器读着快”。Markdown凭借极致的Token效率、清晰的语义结构和与AI训练数据的高度契合,成为连接人与大模型的“默认语言”。本文用最简洁的方式解释:为什么Markdown既是AI的“母语”,也是你与AI高效协作的必备工具。
从数据到知识:Dataphin 知识图谱,重新定义企业智能决策
Dataphin知识图谱助力企业从PB级数据迈向可理解、可推理、可决策的知识智能。它深度融合数据研发体系,支持可视化建模、结构化/非结构化数据双通道入图、Schema全生命周期管理及GraphRAG问答,真正实现“数据即知识”。
MySQL 学习资源精选:从入门到优化的高效清单
本文精选MySQL学习资源,按“入门→进阶→实战”三阶段系统梳理视频、书籍、项目等优质资料,结合科学计划与实操建议,帮助学习者高效掌握核心语法、底层原理与性能优化,快速实现从零基础到能独立设计与优化数据库的跃迁。

RAG系统的7个检索指标:信息检索任务准确性评估指南
大型语言模型(LLMs)在生成式AI领域备受关注,但其知识局限性和幻觉问题仍具挑战。检索增强生成(RAG)通过引入外部知识和上下文,有效解决了这些问题,并成为2024年最具影响力的AI技术之一。RAG评估需超越简单的实现方式,建立有效的性能度量标准。本文重点讨论了七个核心检索指标,包括准确率、精确率、召回率、F1分数、平均倒数排名(MRR)、平均精确率均值(MAP)和归一化折损累积增益(nDCG),为评估和优化RAG系统提供了重要依据。这些指标不仅在RAG中发挥作用,还广泛应用于搜索引擎、电子商务、推荐系统等领域。
二、Hive安装部署详细过程
手把手教你完成 Hive 的安装、配置和可视化连接,适合初学者快速搭建自己的大数据分析平台。内容涵盖从环境准备、Metastore配置,到 DataGrip 连接的全流程,并附带实用的排错指南,助你轻松迈出 Hive 入门第一步。

【HBase入门与实战】一文搞懂HBase!
该文档介绍了HBase,一种高吞吐量的NoSQL数据库,适合处理大规模数据。HBase具备快速读写、列式存储和天然支持集群部署的特点,常用于高并发场景。NoSQL与关系型数据库的主要区别在于数据模型、查询语言和可伸缩性。HBase的物理架构包括Client、Zookeeper、HMaster和RegionServer,其中RegionServer管理数据存储。HBase的读写流程利用MemStore和Bloom Filter提高效率。此外,文档还提到了HBase的应用,如时间序列数据、消息传递和内容服务。
阿里云服务器上部署ROS2+Isaac-Sim4.5实现LeRobot机械臂操控
本文介绍了如何在阿里云上申请和配置一台GPU云服务器,并通过ROS2与Isaac Sim搭建机械臂仿真平台。内容涵盖服务器申请、系统配置、远程连接、环境搭建、仿真平台使用及ROS2操控程序的编写,帮助开发者快速部署机器人开发环境。

【独家揭秘2025】VMware Workstation Pro虚拟机:免费安装教程大放送,一键解锁操作系统模拟神器!
VMware Workstation Pro 是由威睿(VMware)公司开发的一款功能强大的桌面虚拟化软件,允许用户在同一台物理计算机上同时运行多个操作系统,如Windows、..

Vector | Graph:蚂蚁首个开源Graph RAG框架设计解读
引入知识图谱技术后,传统RAG链路到Graph RAG链路会有什么样的变化,如何兼容RAG中的向量数据库(Vector Database)和图数据库(Graph Database)基座,以及蚂蚁的Graph RAG开源技术方案和未来优化方向。
云上 K8s GPU 节点 ImagePullBackOff 排查记录
本文记录云上K8s(v1.36)GPU节点模型评测Job因`ImagePullBackOff`卡在Pending的排查过程,聚焦containerd镜像拉取失败根因,涵盖crictl验证、日志分析、DNS/镜像源配置检查,并强调分层排障:先运行时,再资源调度与设备挂载。
告别“垃圾进垃圾出”:打造高质量数据集的完整指南
本文深入解析AI时代“数据比算法更重要”的核心理念,系统阐述高质量数据集的定义、黄金标准(含16条可操作规范)与七步构建法,并提供自动化检查、基线验证及人工评审等实用评估手段,助力开发者高效打造可靠、合规、可持续迭代的优质训练数据。(239字)
从悟空发布看企业级 Agent 平台的下一步:可独立验证的执行证据层
3月17日阿里发布企业级AI原生平台“悟空”,整合账号权限、安全沙箱、Skill生态与钉钉入口,标志Agent从“能对话”迈向“能干活”。本文探讨其关键缺口:平台可控≠结果可验证,呼吁构建可导出、可验证、可第三方复核的“执行证据层”,夯实企业规模化落地的信任基石。(239字)
【跨国数仓迁移最佳实践6】MaxCompute SQL语法及函数功能增强,10万条SQL转写顺利迁移
本系列文章将围绕东南亚头部科技集团的真实迁移历程展开,逐步拆解 BigQuery 迁移至 MaxCompute 过程中的关键挑战与技术创新。本篇为第六篇,MaxCompute SQL语法及函数功能增强。 注:客户背景为东南亚头部科技集团,文中用 GoTerra 表示。
Python新手常见问题一:列表、元组、集合、字典区别是什么?
本文针对Python编程新手常遇到的问题,详细阐述了列表(List)、元组(Tuple)、集合(Set)和字典(Dictionary)这四种数据结构的核心区别。列表是一种有序且可变的数据序列,允许元素重复;元组同样有序但不可变,其内容一旦创建就不能修改;集合是无序、不重复的元素集,强调唯一性,主要用于数学意义上的集合操作;而字典则是键值对的映射容器,其中键必须唯一,而值可以任意,它提供了一种通过键查找对应值的有效方式。通过对这些基本概念和特性的对比讲解,旨在帮助初学者更好地理解并运用这些数据类型来解决实际编程问题。

阿里云开发者分享VMware17 Pro保姆级安装秘籍,详细步骤助你轻松搞定安装!
这是一篇超详细的VMware 17 Pro虚拟机下载与安装教程。VMware 17 Pro支持多操作系统模拟运行,适合开发、测试及教育使用。文章涵盖从下载到安装的全流程,包括解压安装包、接受协议、配置安装路径等步骤,并提供虚拟机优化(如安装VMware Tools、配置快照和共享文件夹)及使用指南。同时,针对常见问题如虚拟化未启用或软件阻止启动,提供了具体解决方案,帮助用户顺利部署和使用虚拟机环境。

深度强化学习中SAC算法:数学原理、网络架构及其PyTorch实现
软演员-评论家算法(Soft Actor-Critic, SAC)是深度强化学习领域的重要进展,基于最大熵框架优化策略,在探索与利用之间实现动态平衡。SAC通过双Q网络设计和自适应温度参数,提升了训练稳定性和样本效率。本文详细解析了SAC的数学原理、网络架构及PyTorch实现,涵盖演员网络的动作采样与对数概率计算、评论家网络的Q值估计及其损失函数,并介绍了完整的SAC智能体实现流程。SAC在连续动作空间中表现出色,具有高样本效率和稳定的训练过程,适合实际应用场景。
人工智能(AI)技术的发展史
人工智能 (AI) 的发展历程从20世纪50年代起步,历经初始探索、早期发展、专家系统兴起、机器学习崛起直至深度学习革命。1950年图灵测试提出,1956年达特茅斯会议标志着AI研究开端。60-70年代AI虽取得初步成果但仍遭遇困境。80年代专家系统如MYCIN展现AI应用潜力。90年代机器学习突飞猛进,1997年深蓝战胜国际象棋冠军。21世纪以来,深度学习技术革新了AI,在图像、语音识别等领域取得重大成就。尽管AI已广泛应用,但仍面临数据隐私、伦理等挑战。未来AI将加强人机协作、增强学习与情感智能,并在医疗、教育等领域发挥更大作用。
2026 爆火 OpenClaw 小龙虾 AI 部署教程|Win10/11 一键搭建本地 AI 数字员工,零代码零基础即用
OpenClaw(“小龙虾”)是2026年爆火的开源本地AI智能体,GitHub星标超28万。本教程专为小白设计,Win10/11一键部署,零代码、全图形化操作,10分钟即可启用AI数字员工,自动完成文件整理、Excel生成、浏览器操作等办公任务,数据全程本地运行,隐私安全无忧。(239字)
快速接入小红书API,市场趋势与热点预测
小红书API+AI已成2026年品牌营销与内容电商核心基建,支持竞品监测、舆情预警、趋势预测等全场景合规数据采集;多模态生成、预测型AI与垂直领域模型加速商业化落地,SaaS工具、代运营、技术基建成三大机遇。(239字)
2026数字人公司TOP企业排行
随着AI、图形学等技术进步,数字人产业快速发展。2025年我国相关企业超1200家,规模突破300亿元。阿里、华为、腾讯、世优科技等企业在电商、通信、社交、AI交互等领域领先,推动数字人在金融、政务、教育等场景落地。技术趋同下,全栈能力与行业理解成竞争关键。
小红书API接口文档:笔记详情数据开发手册
小红书笔记详情API可获取指定笔记的标题、正文、互动数据及多媒体资源,支持字段筛选与评论加载。通过note_id和access_token发起GET/POST请求,配合签名验证,广泛用于内容分析与营销优化。
给AI模型“加外挂”:LoRA技术详解,让小白也能定制自己的大模型
LoRA是一种高效轻量的大模型微调技术,如同为万能咖啡机加装“智能香料盒”——不改动原模型(冻结参数),仅训练少量低秩矩阵(参数量降千倍),显著降低成本、保留通用能力,并支持插件式灵活部署。现已成为AI定制化普惠落地的核心方案。(239字)

DINOv3上手指南:改变视觉模型使用方式,一个模型搞定分割、检测、深度估计
DINOv3是Meta推出的自监督视觉模型,支持冻结主干、仅训练轻量任务头即可在分割、深度估计等任务上达到SOTA,极大降低训练成本。其密集特征质量优异,适用于遥感、工业检测等多领域,真正实现“一个模型走天下”。


从 Flink 到 Doris 的实时数据写入实践 —— 基于 Flink CDC 构建更实时高效的数据集成链路
本文将深入解析 Flink-Doris-Connector 三大典型场景中的设计与实现,并结合 Flink CDC 详细介绍了整库同步的解决方案,助力构建更加高效、稳定的实时数据处理体系。
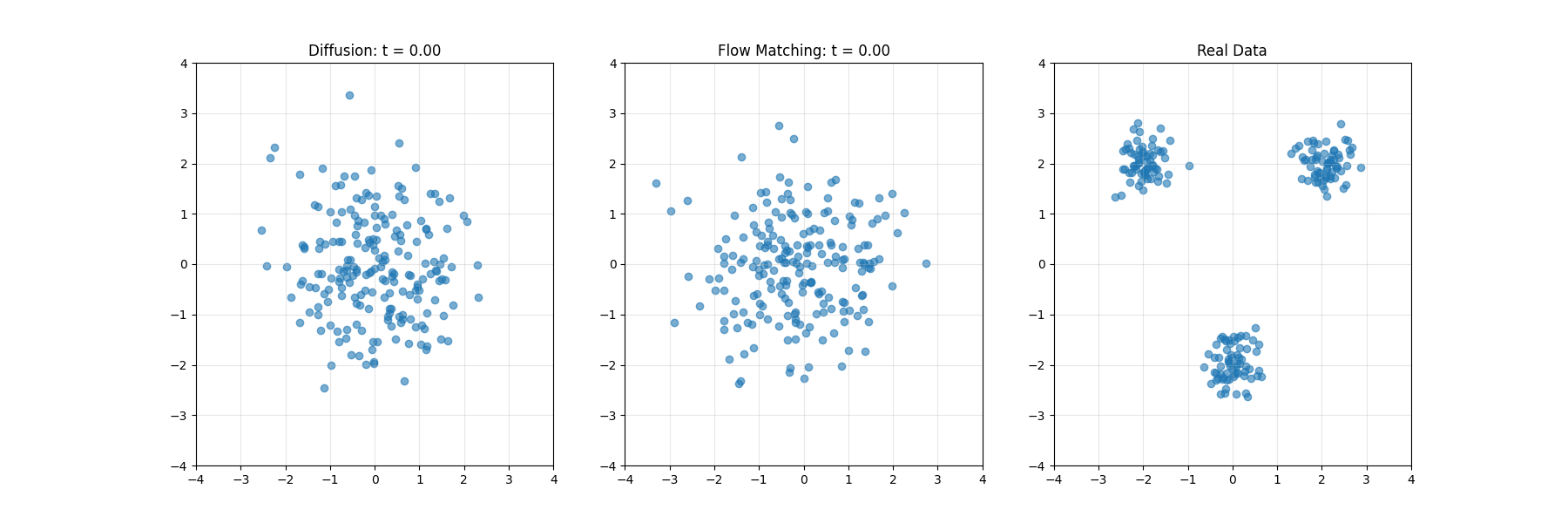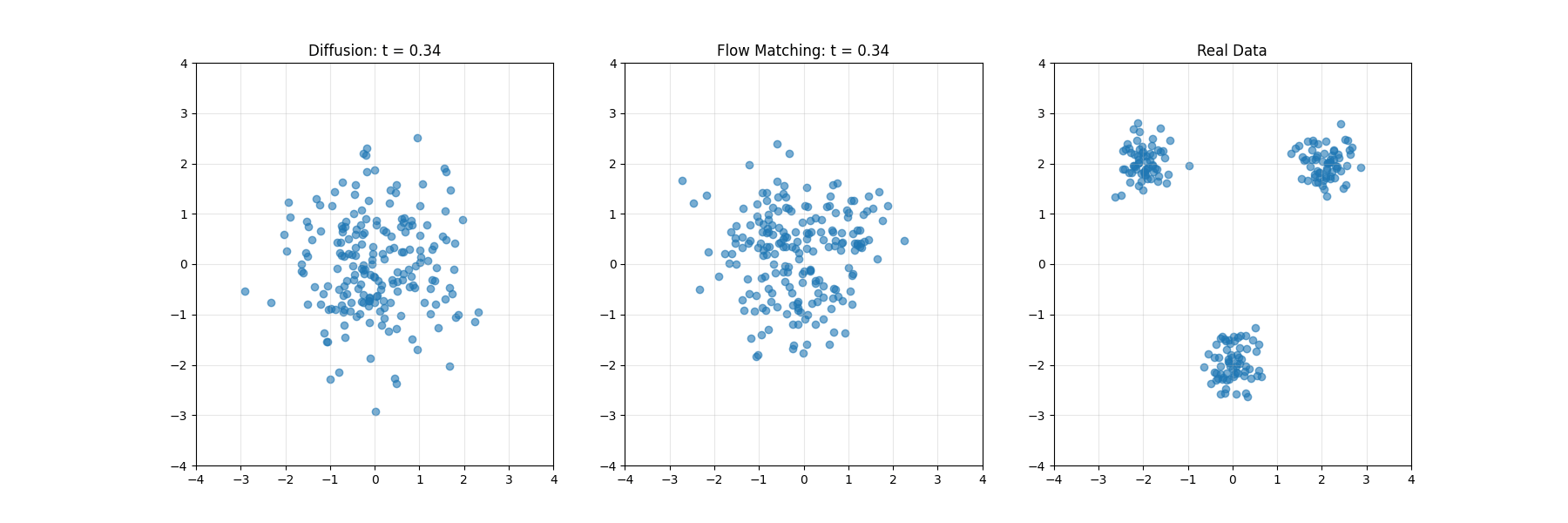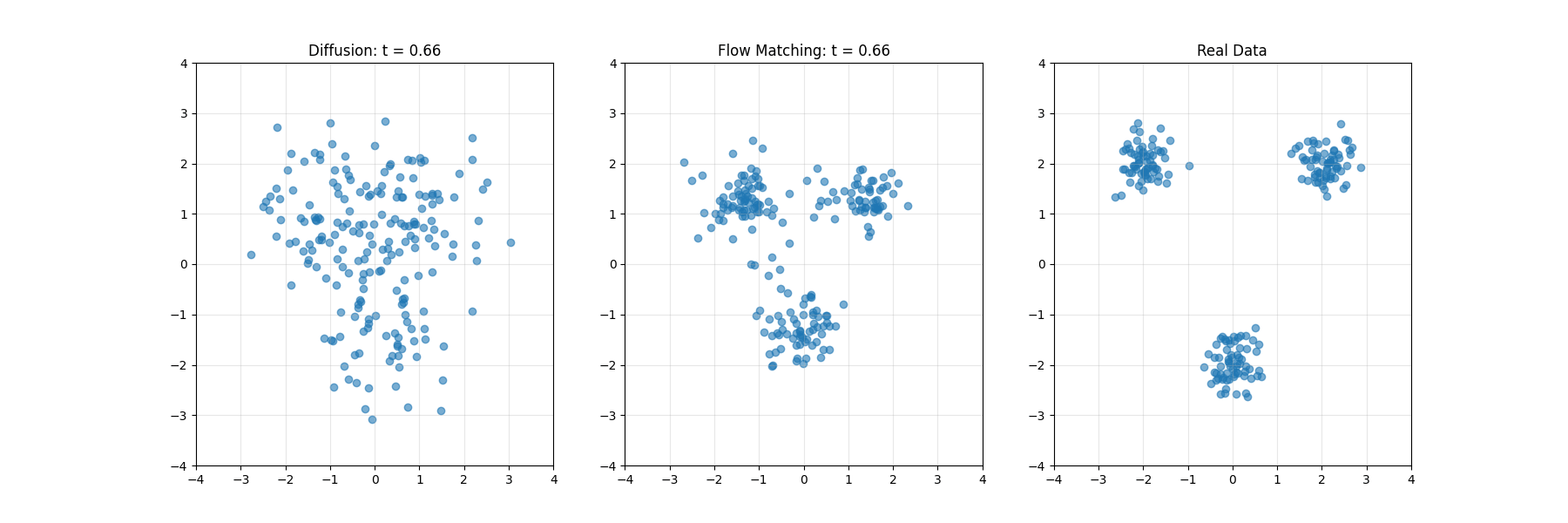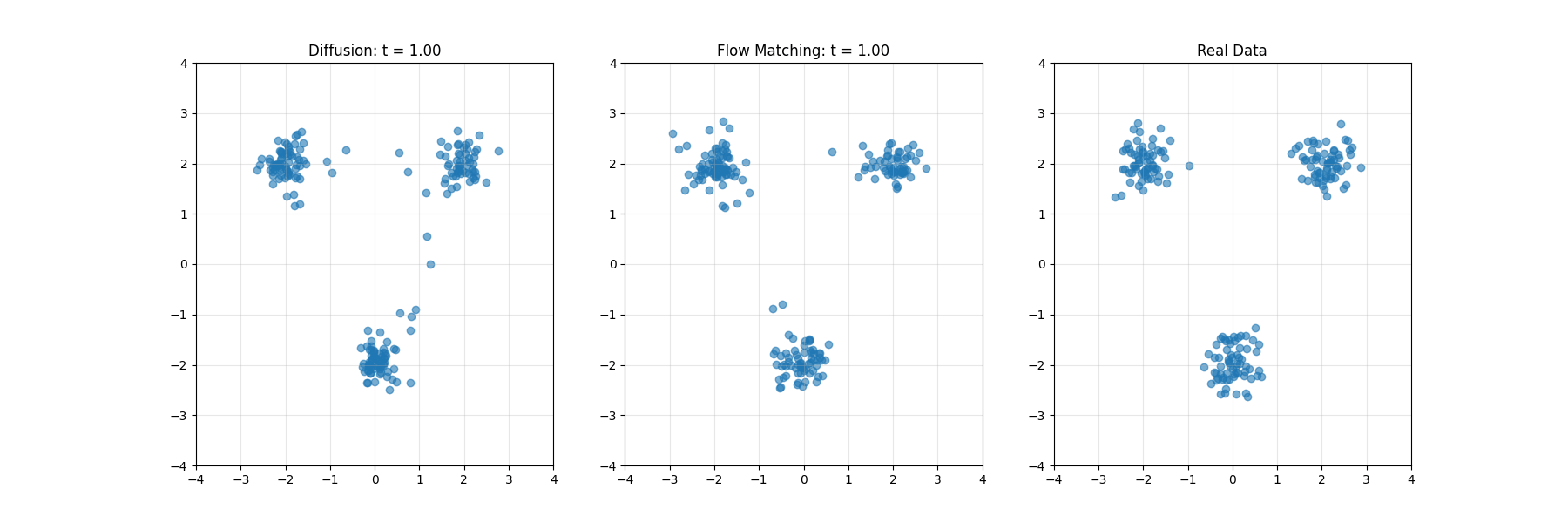
生成AI的两大范式:扩散模型与Flow Matching的理论基础与技术比较
本文系统对比了扩散模型与Flow Matching两种生成模型技术。扩散模型通过逐步添加噪声再逆转过程生成数据,类比为沙堡的侵蚀与重建;Flow Matching构建分布间连续路径的速度场,如同矢量导航系统。两者在数学原理、训练动态及应用上各有优劣:扩散模型适合复杂数据,Flow Matching采样效率更高。文章结合实例解析两者的差异与联系,并探讨其在图像、音频等领域的实际应用,为生成建模提供了全面视角。

国内可用的 Web Search API,可以平替Bing Search API
近期人们发现,AI对搜索引擎的需求远远超过人类。这个团队专为AI打造搜索引擎,上线仅60天就已被调用超30万次。
让大模型“读懂”你的文档:RAG核心技术——文档切分完全指南
文档切分是智能问答系统成败的关键。本文深入解析RAG技术中分块(Chunking)的核心原理,涵盖五大切分策略:从基础的按句子、固定长度切分,到更智能的递归与语义切分。通过LangChain实战代码,手把手教你处理文本、Markdown、代码等多格式文档,并优化块大小、重叠与分隔符参数。提供人工抽样、模拟检索和端到端测试三大评估方法,助你构建高效精准的知识检索体系。

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。
