
缘起
近半年来AI非常火爆,我们深刻地体会到GPT类产品已经切实地在改变我们的生活和工作方式。我也比较关注AI相关的开源技术,最近看到了两个开源库给了我非常大的灵感:
1. LangChain:这个库把AI开发中可能会用到的相关技术都抽象成一个个小的模块,很多工具函数都开箱即用。官网里的一个向量数据库使用的例子给我留下了深刻的印象:从本地文件的读取、文本内容的拆分、向量的存储到相似向量的检索**, 这整个过程每个步骤都是几个非常简洁明了的函数调用,整个流程几十行代码**。不禁让我感叹:这么容易?有了这AI开发我也能搞啊!
2. AutoGPT:在给AutoGPT设定一个目标后,它会做类OKR分解,执行,检查完成情况,制定优化计划,依此 通过不断地自我 prompt 达成设定目标。在学习它源码的时候有一点对我的启发很大:首先代码中预定义了一堆command脚本,在和ChatGPT通话过程中会让它 回复{”command”: “xxx”, “thoughts”: ‘xxx’} 这样的 JSON,解析后可以继续执行本地脚本,从而实现自主执行 , 感觉这是这个项目的精华所在。其实看到 JSON , 作为前端开发是很兴奋了,通过调戏 LLM 让他给出 JSON,纯前端就能玩出很多花活呢!
想到上面几个灵感比较兴奋,于是趁着周末两天撸了个“套壳”应用。同时也验证下利用 Prompt Engineering 调戏 LLM 返回 JSON 的方式玩出花活的可能性
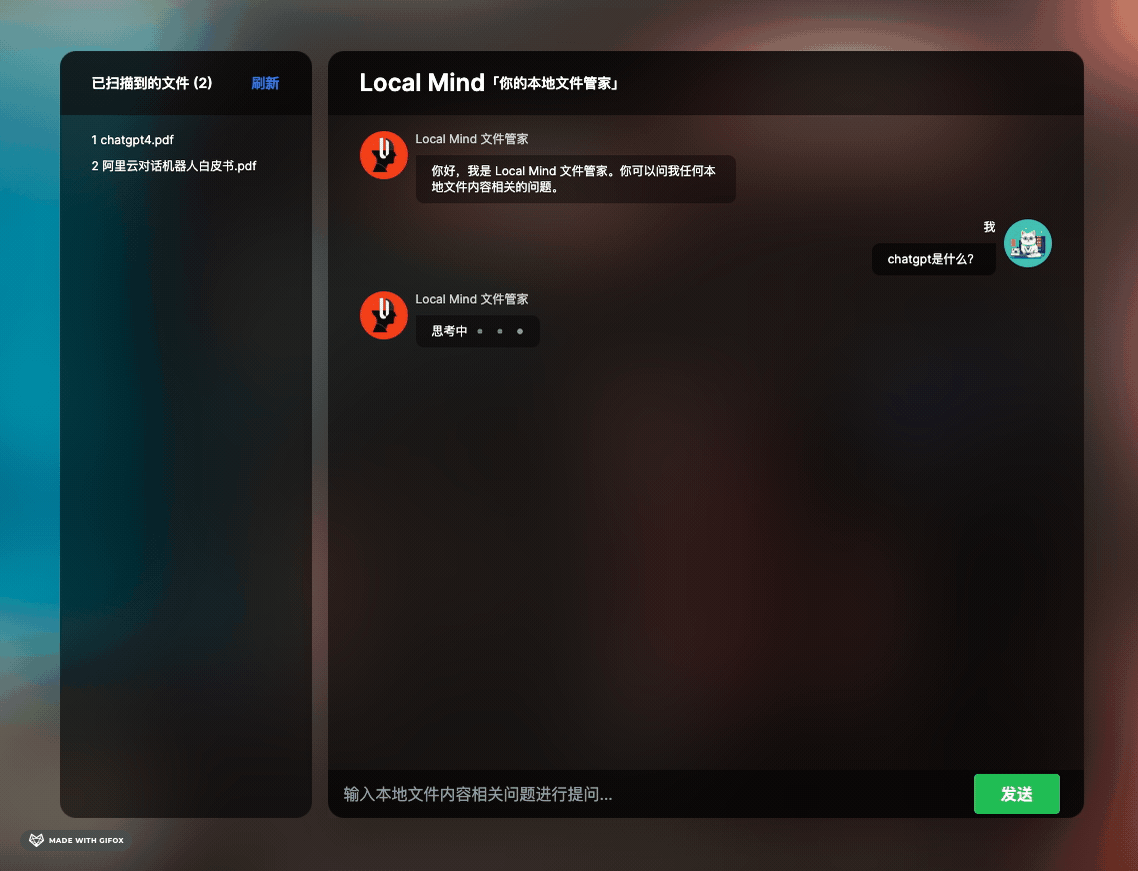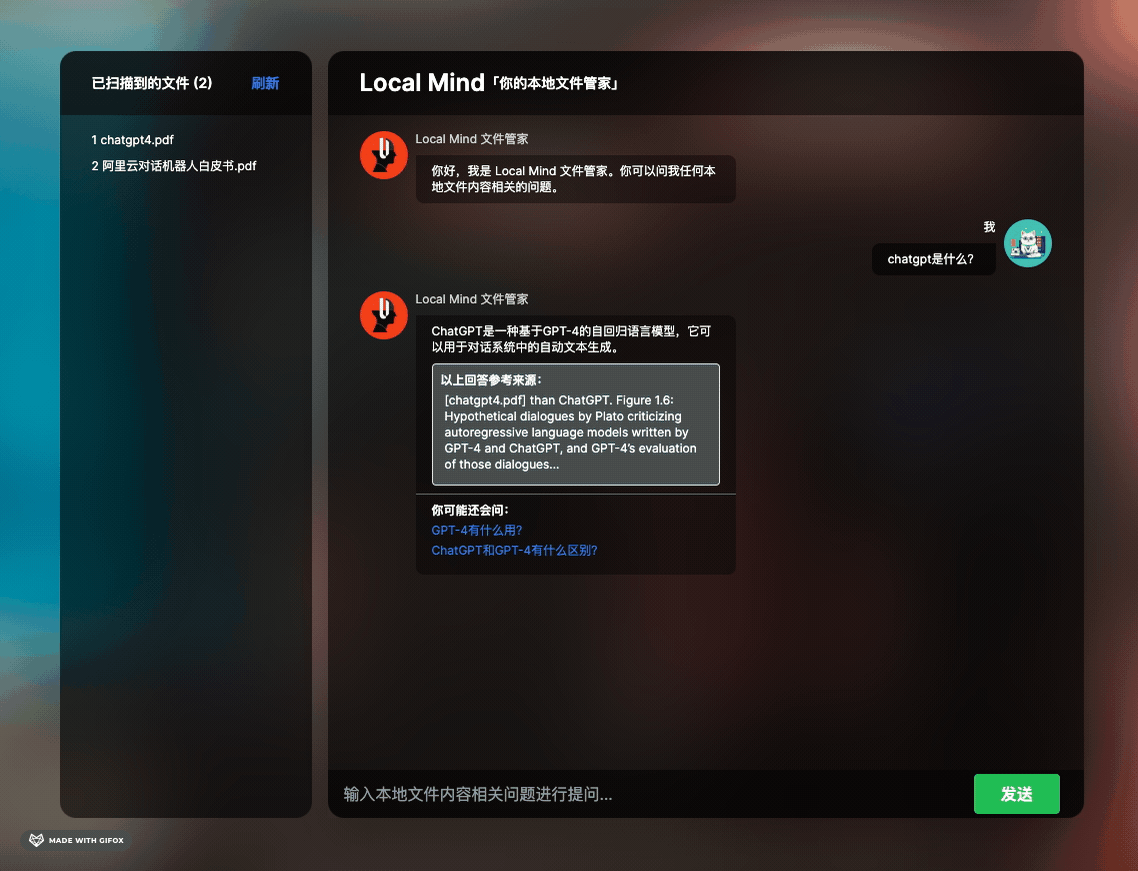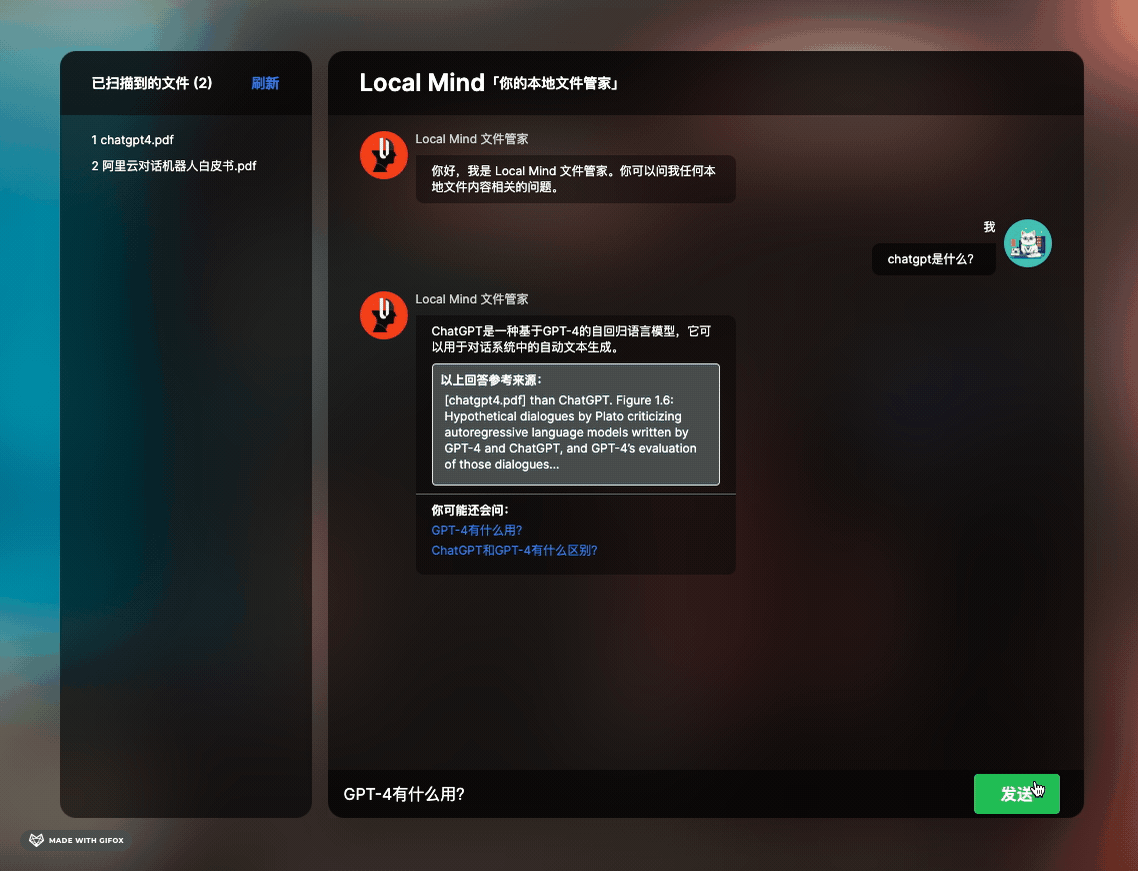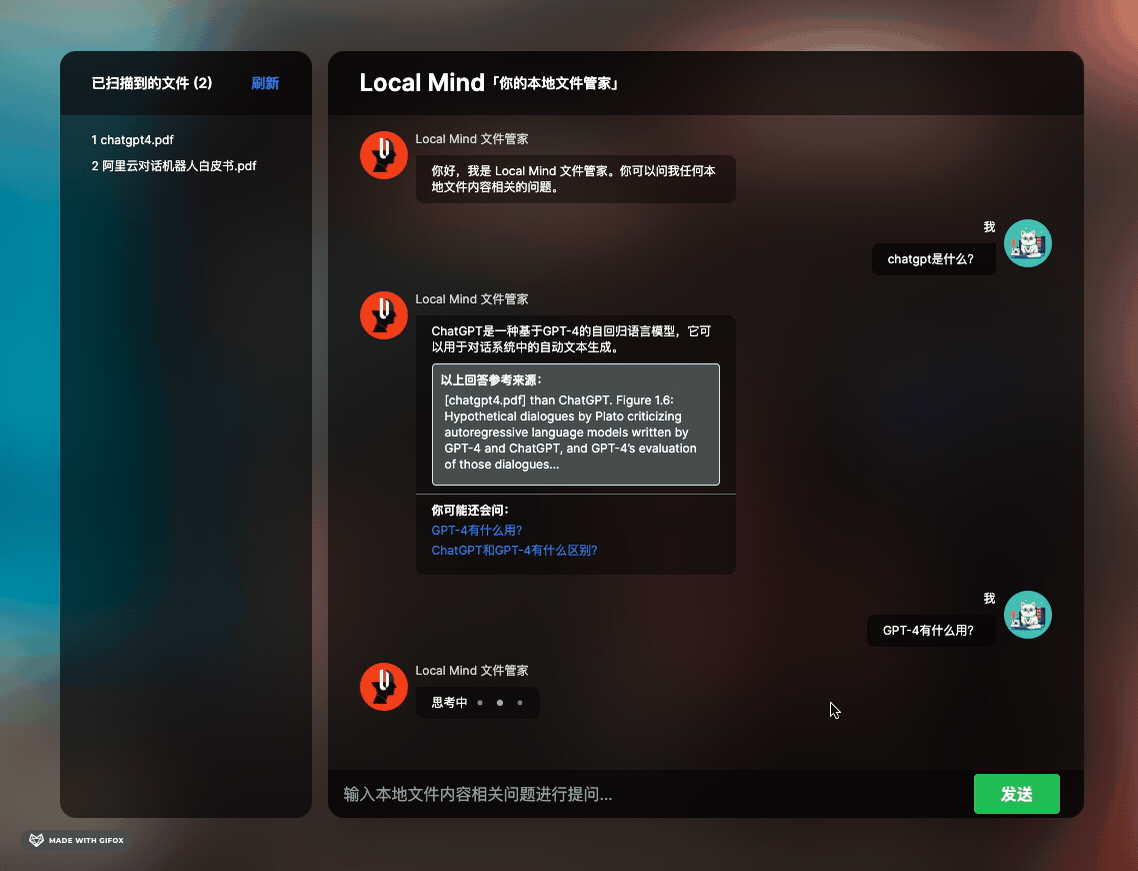
有观察市面上比较火的文档类问答工具 ChatPDF 和 ChatDocs 等产品,觉得非常酷。因此,我打算简单实现类似的功能:在应用程序的某个目录下放置一些文件(PDF、TXT、DOC、EXCEL),然后在聊天窗口中提出任何文档相关的问题,机器人将总结好答案并回复你。此外,我还设计了一些小交互(如文章开头 GIF 所示):让机器人在回复答案的同时说明参考原文,并联想一些类似的问题,方便用户持续提问。
实现分析
主要聚焦在两个问题: 1.如何调教 LLM 让它学会本地的知识, 2. “套壳应用”工程技术选型
如何喂数据给 LLM?
Fine-Turning
说到让大语言模型学会一些本地知识,首先会想到的是“训练”。通常的做法是为机器准备固定格式的数据集,类似于 [{question: 'xxx', answer: 'xxx'}, ...],然后使用 Fine-Tuning 的方法对非结构化数据进行训练。但对于像我这样的外行来说,去对数据做预处理和特征工程不是一种合适的解法。
Embedding
Embedding的理解是将高维数据向量化的过程。在LangChain中,有现成的工具函数可以完成这个任务。众所周知,GPT3.5的API有4K token 的长度限制,因此直接将所有的PDF文件一股脑地塞给LLM是不可行的,肯定超过了这个长度限制。LangChain中的 Document Loaders、Text Splitters、Vector Stores 提供了一种巧妙的方法来绕过这个4K token的限制。大致的工作原理是:首先在本地启动一个向量数据库,用来存储所有本地文档。然后,在进入GPT之前,先在本地进行一次相似度内容搜索。最后,将空间距离最近的几个答案嵌入提问中,交给LLM处理。

所以我们使用 LangChain,其实并没有真正意义上去训练LLM, 我们只是把 本地知识库 和 问题当做prompt的一部分给到LLM。 这么做非常的轻量级, LLM只需要 做的它最擅长的事情。翻译和总结是大语言模型非常擅长的两件事情,所以如果你在目录里放的是英文文档,聊天框里你是可以通过中文和应用进行对话的。
如何搭建“套壳”应用工程?
一旦确定了AI训练数据相关的方案后,工程化就相对容易了,分析了下大致需要以下几个部分:
-
LangChain提供了JS API,因此可以使用Node.js应用程序即可运行。
-
前端页面可以直接使用React、Vue甚至是原生HTML + JS。
-
LangChain实际上还提供了10多个向量数据库可供选择。我选择了HNSWLib,因为目前只是进行技术探索,所以选择了内存级向量数据库,非常轻便,支持Node.js,支持离线运行,不需要编写SQL,无需单独启动数据库程序,只需将其作为一个模块导入即可运行。在生产环境中,建议使用更高级的云端数据库,例如Pinecone、Supabase等。
所以其实只需一个Next.js应用程序即可包含以上所有部分,只需一行 npm start 即可启动所有模块(前端 、后端、数据库)。
工程代码关键实现
在代码部分,我个人认为基于 LangChain 进行开发非常简洁。当大家看到下面的实现后,应该也会有同样的感觉。
首先,看这段 Prompt 代码 ,它算是这个套壳应用最核心的代码

这段代码也是我在调试过程中花费了相当多时间的。首先,我让 GPT 扮演文档工程师的角色,让他帮我总结与“问题”相关的内容,这也充分利用了 LLM 的超强总结能力。我要求 LLM 返回一个包含三个字段的 JSON,这几个字段也是界面聊天框内吐出的答案所必需的内容,即机器人的总结回复、原文引用和相似答案。
其实中间我遇到了一个比较大的问题:就是 LLM 有较大的概率不会返回完整的 JSON 结构体。这会导致应用 JSON.parse 失败。解决办法有很多,例如 AutoGPT 中有自定义的 fix_json_using_multiple_techniques 函数用于修复 JSON,LangChain 中也有 OutputFixingParser 等解析函数。不过我尝试的是另一种 SAO 操作——“威胁”,如下:
“不要包含任何其他非JSON内容,否则你将被扣分!!!”
经实测,回答出错率的确会下降很多,但无法完全避免出错。还需要进一步研究研究,也许需要更大参数量的 API 来解决这个问题。
流程中其他流程相关的代码我贴一些图,大家也能感受一下 LangChain 的简单易用:
本地文件的解析

通过Embedding方式做文档切片并初始化向量数据库

近似向量内容检索

LLM API 调用

聊天前端代码:把 HTML + JS 都算上不到300行代码

顺带安利一下,tailwind 是 next.js 自带的 CSS 框架。时常在其他开源项目中看到,这次聊天页面的 CSS 基本上都是用 tailwind 编写的。上手成本非常低,基本上可以不离开 HTML 就将 CSS 全部搞定,这得益于 GPT 的支持。

最后几点零散想法
-
探索的价值:上周末在开始写这个项目的时候,有看到一个新闻(Claude 已支持100K token 长度的上下文),长上下文方案比起我这个依赖前置向量数据库的效果显然会是降维打击, 不过我还是硬着头皮把代码写完了, 这个工程化的探索还是有价值的,毕竟随便魔改一下就可以摇身一变另外一个垂类领域的“套壳”应用。
-
AI开发的壁垒在哪:AI生态蓬勃的状态非常像前几年前端生态,真是以“天”为单位的迸发出令人惊叹的项目。现在开发应用也变得越来越容易,所以我认为开发出一个好的应用的难点并不在于像 LangChain 等工具库的使用本身,而更多在于 如何充分利用 LLM 的优势,充分利用积累的数据,“调戏”LLM, 最终设计出良好的交互体验优秀并解决用户痛点的产品。
-
项目代码:因为项目是周末时间兴起在个人电脑上写的,所以写完后直接 push到了 github 上,供大家交流学习。 https://github.com/nigulasikk/local-mind

