开发者学堂课程【开源 Flink 极客训练营:PyFlink 快速上手】学习笔记,与课程紧密联系,让用户快速学习知识。
课程地址:https://developer.aliyun.com/learning/course/760/detail/13342
PyFlink 快速上手
二. PyFlink 功能介绍
1. Python Table API
目标:
①支持用户使用 Python 语言编写 Flink 作业。
Flink 中有三种类型 API: ProcessFunctionAPI、DataStreamAPI 和 SQL/T ableAPI。其中前两者是基于底层的 API,基于 ProcessFunctionAPI 和 DataStreamAPI 开发的作业逻辑会严格按照用户定义的行为执行,而 Table API 是基于包层的关系 API,提供的功能和 SQL 比较类似,基于 Table API 开发的作业逻辑会经过一系列的优化之后执行。
②Python Table API 功能丰富,能完成 Java Table API 所支持的绝大部分功能。
示例:

Python Table API 开发的作业,作业逻辑是读取文件,计算 word、count,再把计算结果写入文件中。这个例子包括了开发一个作业的所有的基本流程,比如说首先我们需要定义作业的执行模式是批模式还是流模式,作业的并发度,作业的配置以及定义一个 source 表和 sink 表,source 表定义了作业的数据源来源,数据的格式,sink表定义了作业的执行结果写到哪里,以及数据格式。在这个例子中,source 表和 sink 表的都都是写到本地的文件系统中。最后我们需要定义作业执行逻辑,在这个例子是计算 word、count 的,所以作业的执行逻辑比较简单,然后 group_by('word'),select ('word,count(1)'),最后需要把作业提交执行。
Python Table API 部分截图

从这里面大家可以看到,Python Table API 的数量还是比较多的。功能也很齐全。前面我们也说过 Python Table API 与 SQL 还是比较类似的。从列表中大家也可以看到这里觉得绝大多数的语句和SQL 是很相似的,比如 join 语句、group_by 语句、order_by 语句等等,如果对 SQL 熟悉,对这些 API 也不会太陌生。如果使用Python Table API 开发 Flink 作业,可以参考 Python Table API的文档,详细了解有哪些 API,每一个 API 的行为是什么。
2. Python UDF
目标:
①支持用户自定义和使用 Python UDF。
②Python UDF 除了可以使用在 Python Table API 作业中外,还可以使用在 Java Table API 作业以及 SQL 作业中。
Python table API 是一种关系型 API,其功能可以类比成 SQL,而在 SQL 里面自定义函数是非常重要的功能。可以极大的扩展 SQL的使用范围。Python UDF 的主要目的就是允许用户使用 Python语言来开发定义函数,从而扩展 Python table API 的使用场景。同时需要注意。Python UDF 除了可以使用在 Python table API 作业中外,还可以作用在 JAVA table API 作业以及 SQL 作业中。
(1)Python UDF-如何定义
在 PyFlink 中有多种方式来定义 Python UDF,用户可以定义一个Python 类,Python 类需要继承 ScalarFunction,在 Python 类中需要定义一个 eval 方法,在 eval 方法中可以实现自定义函数的逻辑,用户也可以定义一个普通的 Python 函数或者拉姆达函数,在这之中实现自定义函数的逻辑。除此之外,还支持通过 Callable Function已经 Partial Function 来定义 Python UDF。提供多种定义 Python UDF 的目的主要就是方便用户,可以根据需要选择最适合的方式。

(2)Python UDF-如何使用
PyFlink 中提供了多种使用方式
①Python Table API 作业中使用
定义完 Python UDF 之后,用户首先需要注册 Python UDF,可以调用 table_env.register_function 方法进行 Python UDF 的注册,注册需要给 Python UDF 命名,接下来可以在作业中通过该名字使用 Python UDF。

如上图例子,注册了 Python UDF,名字叫 add_one,输入只有一个参数是 BIGINT 类型,输出也只有一个参数是 BIGINT 类型。在 select API 中可以通过注册的 add_one 名字来引用 UDF。注意,在 Python Table API 中除了可以使用 Python UDF 之外,也可以使用 Java UDF。
②Java Table API 作业中使用
与 Python Table API 使用方式类似,注册方式不同,在 Java Table API 中需要通过 DDL 语句来注册,在 DDL 语句“create temporary system function add_one as 'udfs.add_one' language python”中 add_one 是 Python UDF 注册到系统中的名字,udfs.add_one 代表 Python UDF 来自于哪里,language python 表示这是 Python 的 UDF。

③SQL 作业中使用
与前两种方式类似,首先需要注册 Python UDF。在 SQL 作业中使用 Python UDF 时,有两种方式,用户可以在 SQL 搜索脚步中使用 DDL 语句注册,该 DDL 语句与在 Java Table API 中注册Python UDF 的 DDL 语句是类似的。如果用户使用 SQL client 提交作业的话,也可以在 SQL client 的环境配置文件中注册 Python UDF。

这里注册了一个 Python UDF add_one,类型是 Python,权限命名是 udfs.add_one。
Python UDF-如何使用
注册完成之后,用户可以在后续作业中使用 Python UDF。
使用 Python UDF 的 SQL 语句:
INSERT INTO sink
SELECT add_one(a)
FROM table
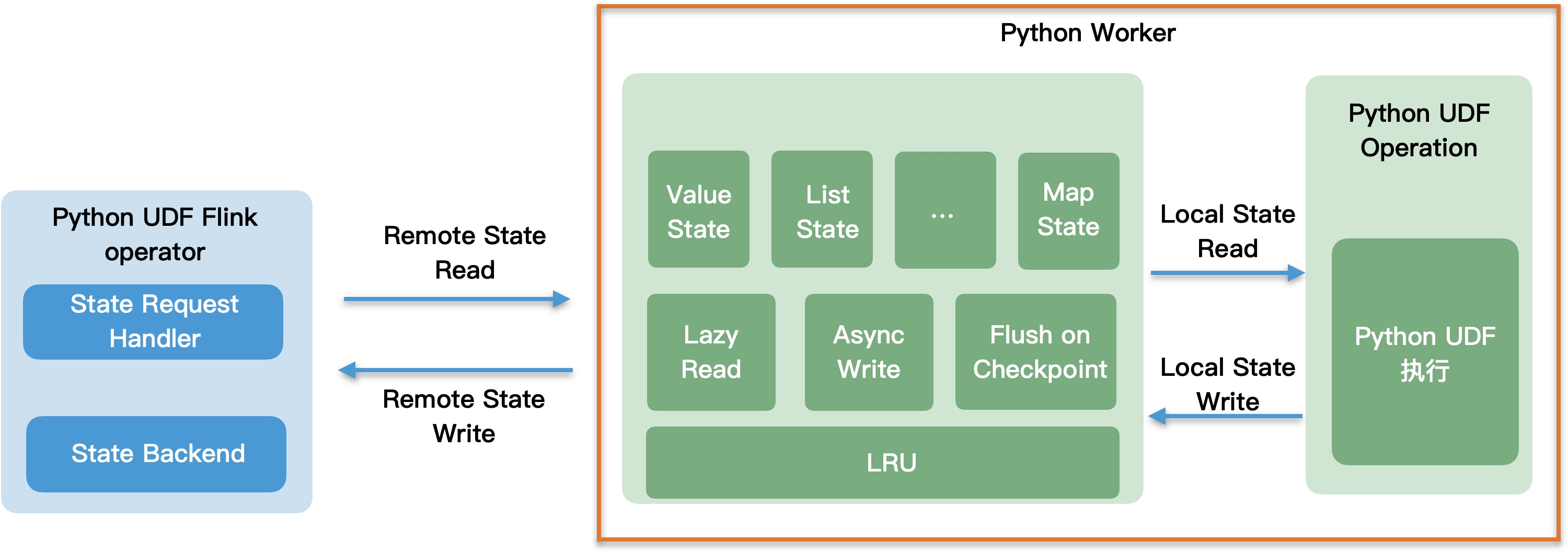
(3)Python UDF-架构

Flink 是由 Java 语言编写的,运行在 Java 虚拟机中,Python UDF 运行在 Python 虚拟机中。Python UDF 的执行涉及到在Java 进程中将输入数据准备好,序列化之后发送给 Python 进程,Python 进程执行 Python UDF 的计算逻辑,再把计算结果返回给Java 进程,可见在 Java 进程和 Python 进程之间是需要进行数据通信的。除此之外,Java 进程与 Python 进程之间还可能需要传输 state 数据,比如对于流式作业,自定义函数的执行,在执行过程中需要访问 state。在1.12将要支持的 Python
DataStreamAPI 在执行过程中也可能需要访问 state。用户可能会有需求在 Python UDF 的执行过程中会打印 log 或者汇报meteics 等,在 Java 进程和 Python 进程之间除了需要传输数据还需要传输 state、log、metrics,也就是说 Java 进程和 Python进程之间的传输协议需要满足这四种类型。
3.向量化 Python UDF
在刚刚发布的1.11中的新功能
目标:
①支持在 Flink Java/ Python Table API& SQL 作业中自定义和使用向量化 Python UDF
②方便 Python 用户基于 Pandas、NumPy 等数据分析领域常用的 Python 库,开发高性能的 Python UDF
普通 Python UDF vs 向量化 Python UDF

普通 Python UDF 以行作为计算的基本单位,每次 Python UDF调用处理一条数据。向量化 Python UDF 输入输出是列式结构,每一个列式结构中包括该列的多条数据,每次向量化 Python UDF 调用时处理多条数据。
Apache Arrow 是一个第三方的库,定义了一个跨语言的高效的列式存储格式,用于在不同的平台或组件之中高效的传输。Pandas 库是原生支持 Apache Arrow 的,所以对于向量化 Python UDF 的执行,在 Java 进程和 Python 进程之间传输数据时可以利用Arrow 格式极大地优化序列化/反序列化开销。
Python UDF 和向量化 Python UDF 可以极大的扩展 Python Table API 的表达能力。
向量化Python UDF-如何执行
在 Java 中会将多条数据积攒然后转换成 Arrow 格式,Arrow 格式的二进制数据发送给 Python, Python 收到数据之后,将 Arrow格式的二进制数据转化成 Pandas 的数据结构,如何调用用户自定义的向量化 Python 语言。注意,由于 Pandas 原生支持 Arrow,所以将 Arrow 格式的二进制数据转化成 Pandas 数据结构的过程开销是非常小的。同时向量化 Python UDF 的执行结果会再转化成Arrow 格式的数据发送给 Java 进程。
向量化 Python UDF-示例
在使用方式上,向量化 Python UDF 是类似的,只有几个地方稍有不同。首先,在向量化 Python UDF 的示例化上,需要添加一个udf_types,输入输出类型是 Pandas 的 Series,框架在通用向量化Python UDF 之前会将输入数据转化成 Pandas Series 类型然后再调用用户自定义的向量化 Python UDF。
4.Python UDF Metrics
Python UDF 有多种定义方式,如果需要在 Python UDF 中使用Metrics,Python UDF 必须继承 ScalarFunction 的方式进行定义,在Python UDF 的 open 方法中定义了一个 function_context 的参数,用户可以通过这个参数注册 Metrics,后续可以通过注册的Metrics 对象来汇报 Metrics。

示例:
在该示例中注册了一个 counter 类型的 Metrics,在 eval 方法中调数据时会给 counter 加上一定的值。在 PyFlink 中也支持其他类型的 Metrics:
5.Python 依赖管理

普通的 Python 文件是单个的 Python 文件,比较简单。存档文件是压缩包,用户可以用来上传数据集或者 Python 的虚拟环境。三方库是第三方的依赖。用户可以指定在使用 Python UDF 时所使用的 Python 解释器的位置,比如可以将 Python 解释器的路径指定到存档文件中上传到 Python 虚拟环境,或者在集群端安装了多个Python 环境,可以将 Python 解释器的路径指向某一具体 Python 版本。有需要的话用户也可以指定 Java 的依赖包。从PyFlink 提供的解决方案来看,每一种依赖 PyFlink 提供了两种解决方案。一种是 API 的解决方案,用户可以在作业中指定所用的依赖。另一种是命令行选项,用户可以在提交作业时,通过命令行选项的方式指定依赖。
6.Python UDF 执行优化
①执行计划优化
Ⅰ.不同类型的 UDF 的拆分
Ⅱ. Filter 下推到 Python UDF 之前
Ⅲ. Python UDF Chaining
由于在一个节点中可能同时包含多种类型的 UDF,不同类型的 UDF比如普通的 Python UDF 和向量化 Python UDF,这两个 UDF 同时位于一个 Project 节点中,是不能放在一起执行的。首先需要拆分这些 UDF,经过拆分之后,把 Project 节点拆分成两个 Project节点,其中第一个包含普通 Python UDF,第二个包含向量化 Python UDF,不同类型的 Python UDF 拆分到不同的节点之后,每一个节点只包含一种类型的 UDF,根据 UDF 类型,选择最合适的执行方法。
1)对于 Java UDF,方法调用即可
2)对于普通 Python UDF,按序列化,并发送到 Python进程执行
3)对于向量化 Python UDF,攒一批数据后,按列进行序列化,并发送到 Python 进程执行
第Ⅱ点前提是 Python UDF 的执行效率相对于 Java 来说更慢,Filter 下推的主要目的是尽可能的降低 Python UDF 节点输入数据的数据量,从而提升整个作业的执行性能。作业的原始计划包括两个 Project 节点,这个执行计划是可以运行的,但不是最优的,因为在Filter节点之前,Python UDF 的节点位于 Filter 节点之前,在 Filter 节点之前 Python UDF 已经算完了,但如果把 Filter 的逻辑或者部分下推到 Python UDF 之前,就可以大大降低 Python UDF 输入数据量。基于该思路,通过优化规则可以调整执行计划,比如先计算 Java UDF,然后根据 Java UDF 的计算结果,过滤一些数据,Python UDF 的输入数据量就可以大幅减少。由于 Python UDF 节点的输入数据量减少,整个作业的吞吐都能够得到提升。
由于 Java 进程和 Python 进程之间的通信开销以及序列化/反序列化的开销比较大,Python UDF Chaining 的主要目的是尽量减少Java/Python 进程之间的通信开销,比如说当一个 Python UDF 的输入来自于另一个 Python UDF 的输出时,可以将这两个Python UDF 组合在一起执行。例如 add 和 subtract 都是Python UDF,在这个执行计划中包含了两个 Project 节点,其中第一个 Project 节点先算 subtract,计算完 subtract 的输出,然后再传输给第二个 Project 节点执行。这个执行计划主要是说由于subtract 和 add 位于两个不同的节点,计算结果需要从 Python进程发送给 Java 进程,再从 Java 进程发送给第二个几点的Python 进程中执行,带来了完全没有必要的通信开销以及序列化/反序列化开销。基于以上问题,可以将执行计划优化,将 subtract和 add 放入一个节点去运行,subtract 结果计算出后直接调用add 节点。
②运行时优化
Ⅰ.Cython support
Ⅱ.自定义序列化器
Ⅲ.向量化 Python UDF support
默认都是开启的。这和搜狗非常相似,一个包含 Python UDF 的作业,首先会经历一些规则,生成一个最优的执行计划,在执行计划已经确定的情况下,在执行时可以利用其他的优化手段达到尽可能高的执行效率。