
flink中Mesos在大数据领域用的更多?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在大数据领域,Apache Mesos和Apache Flink都是非常流行的技术,但它们的使用场景和目的略有不同。
Apache Mesos是一个开源的集群管理器,用于在数据中心的分布式环境中进行资源管理和调度。它能够将集群中的物理或虚拟资源抽象为一种通用的资源,并提供一种灵活的方式来定义和隔离应用程序的执行环境。Mesos被广泛用于大数据处理、云计算和容器编排等领域,因为它能够有效地管理和调度大规模的分布式资源,并提供高可用性和可伸缩性的保证。
Apache Flink本身具有强大的分布式处理能力,可以在大规模集群上高效地处理数据。Flink提供了自己的集群管理和调度功能,因此通常直接在Flink集群上部署和运行作业,而不需要使用其他资源调度框架。
然而,在某些场景下,可能会将Flink与Mesos结合使用。例如,一些组织可能会使用Mesos来管理和调度其他类型的分布式应用程序,而在同一集群上运行Flink作业作为其中一部分。这样可以充分利用Mesos的资源管理和调度功能,同时使Flink能够利用集群中的计算资源。
在大数据领域,Apache Mesos和Apache Flink都是非常流行的技术,但它们的使用场景和目的略有不同。
Apache Mesos是一个开源的集群管理器,用于在数据中心的分布式环境中进行资源管理和调度。它能够将集群中的物理或虚拟资源抽象为一种通用的资源,并提供一种灵活的方式来定义和隔离应用程序的执行环境。Mesos被广泛用于大数据处理、云计算和容器编排等领域,因为它能够有效地管理和调度大规模的分布式资源,并提供高可用性和可伸缩性的保证。
而Apache Flink是一个开源的流处理框架,用于构建实时数据流的应用程序。它提供了一种高度灵活的数据流编程模型,支持批处理和流处理,并提供了高效的分布式计算能力。Flink在处理大规模数据流时具有高性能和低延迟的特性,因此被广泛应用于实时数据分析、在线机器学习、ETL等场景。
因此,Mesos和Flink在大数据领域都有广泛的应用,但它们的使用场景和目的有所不同。具体选择哪种技术取决于应用程序的需求和资源管理的要求。
Apache Mesos和Apache Flink都是大数据领域的开源技术,但它们各自的作用和关注点略有不同。Apache Mesos是一个集群管理系统,用于提供高效、弹性、分布式系统的资源管理和调度,可以管理包括CPU、内存、存储等多种资源。而Apache Flink则是一个分布式流处理和批处理框架,用于进行实时数据处理和分析。
在大数据领域,Mesos和Flink可以配合使用,以实现更加高效和灵活的资源管理和数据处理。Mesos可以提供细粒度的资源管理和调度,使得Flink作业可以更加高效地利用集群资源,从而提高数据处理的速度和效率。同时,Flink也可以作为Mesos上的一个框架,通过Mesos来管理和调度Flink作业,从而简化了Flink集群的部署和管理。
然而,是否使用Mesos取决于具体的应用场景和需求。虽然Mesos在大数据领域有一定的应用,但并不是所有的大数据应用都需要使用Mesos。一些其他的大数据技术,比如Hadoop YARN、Kubernetes等也可以提供类似的资源管理和调度功能,而且Flink也支持在这些技术上进行部署和运行。
Flink利用Mesos提供的worker来运行其TaskManager。Apache Flink提供了bin/meso-appmaster.sh脚本来启动mesos集群上的Flink。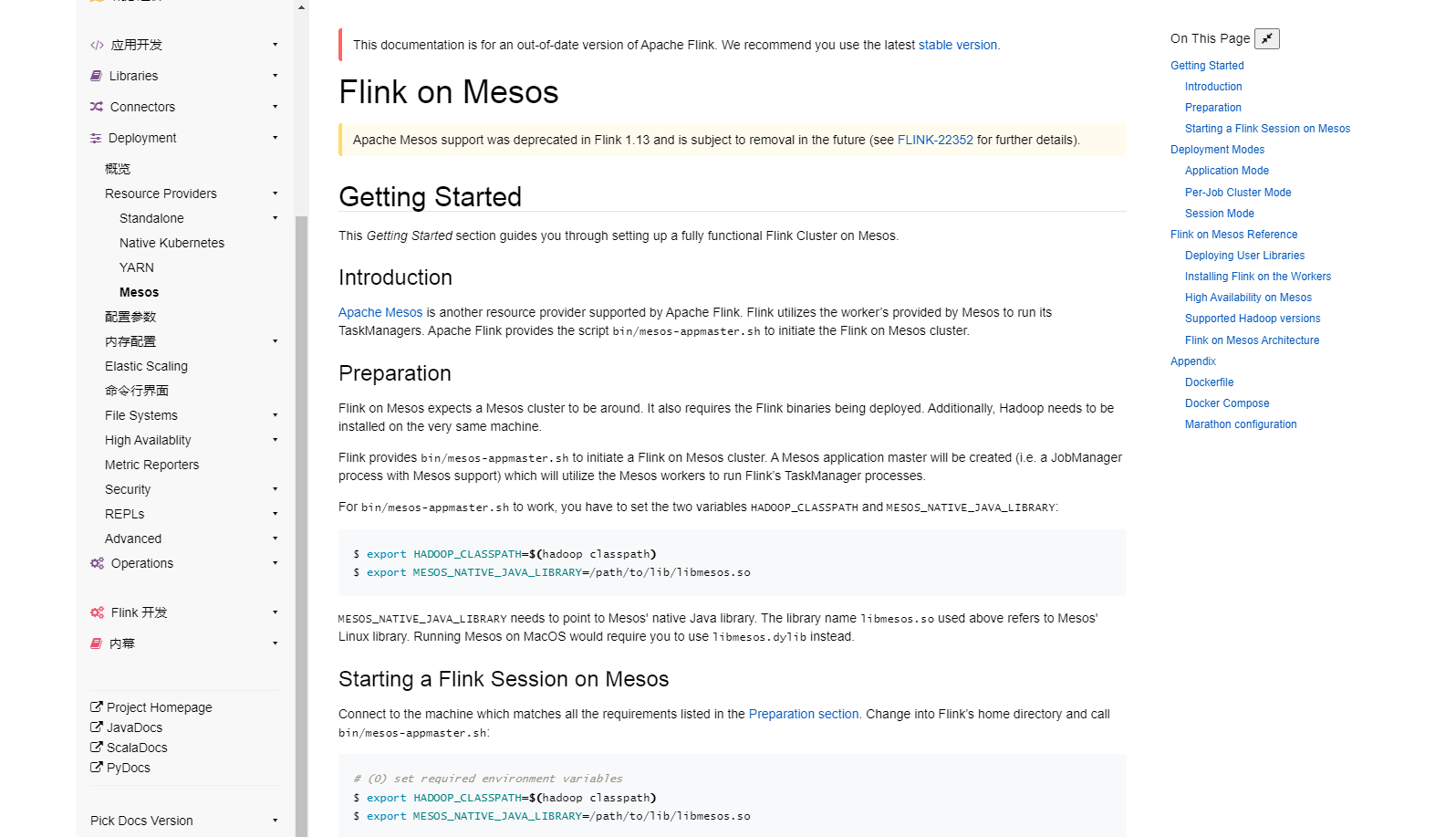
——参考来源于Flink的官方文档。
Apache Flink 是一个分布式流处理框架,它可以用于构建实时数据流应用程序。在大数据领域,Flink 通常与资源管理器一起使用,以便在分布式环境中运行 Flink 作业。其中,Apache Mesos 是一个流行的资源管理器,它允许 Flink 作业在集群上动态地获取资源并进行调度。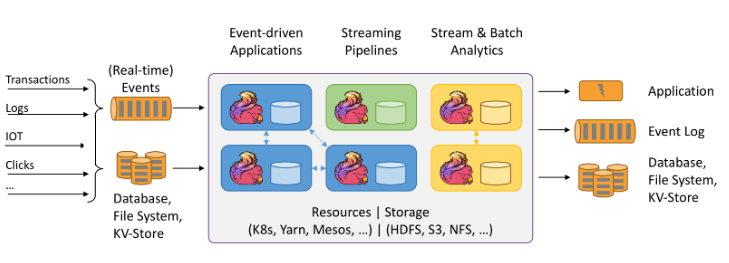
在大数据领域,Apache Mesos 是一种常见的资源管理器,它可以将集群中的多个节点上的CPU、内存和存储等资源抽象为一个共享的资源池,以便更好地利用集群资源并提高数据处理效率。
与 YARN(Yet Another Resource Negotiator)相比,Mesos 提供了更细粒度的资源管理和更高效的资源分配机制。它可以将集群中的所有资源视为一个整体,并根据应用程序的需求动态地分配资源。因此,对于需要处理大规模数据流的应用程序,使用 Flink 与 Mesos 集成可以提供更好的性能和扩展性。
当然,除了 Mesos,Flink 还可以与其他的资源管理器一起使用,如 Hadoop YARN 和 Kubernetes。每个资源管理器都有自己的特点和优势,具体选择哪个取决于应用程序的需求和环境配置。
Apache Flink是一个分布式系统,用于处理无界和有界数据流,它可以以数据并行和流水线方式执行任意流数据程序。Flink的流水线运行时系统可以执行批处理和流处理程序,并且可以在所有常见集群环境中运行,包括Mesos。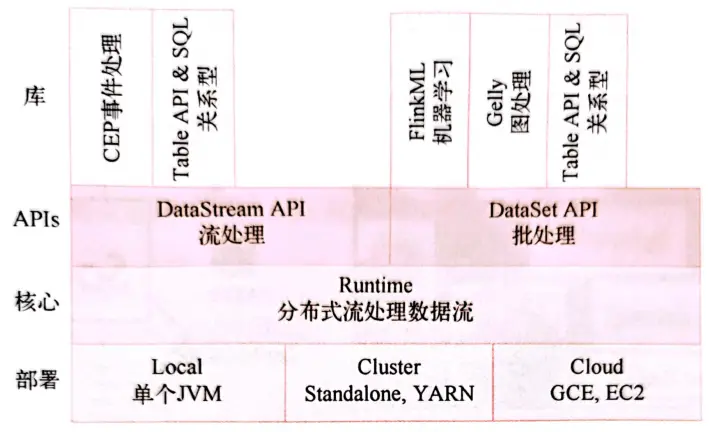
至于在大数据领域中,使用Flink与Mesos的情况,这主要取决于具体的应用需求和环境配置。在某些情况下,将Flink与Mesos结合使用可以提供更好的资源管理和调度能力,以支持大规模的数据处理和分析工作负载。
然而,是否选择使用Flink与Mesos主要取决于具体需求,包括数据处理模式(流处理或批处理)、数据规模、实时性要求、资源利用率和系统稳定性等方面。在做出决策之前,最好评估各种因素并考虑其他可用的技术和工具。
此外,值得注意的是,Flink不仅与Mesos集成,还可以与其他的集群资源管理器(如YARN和Kubernetes)以及独立部署选项一起使用。这为大数据应用程序提供了更大的灵活性和可扩展性。
综上所述,虽然Flink可以与Mesos一起使用,但选择是否使用它们主要取决于具体的需求和环境配置。在大数据领域中,根据应用程序的需求和资源管理要求进行适当的评估是至关重要的。
在大数据领域,Apache Mesos 是一种常用的资源管理系统,主要用于管理和协调大规模集群中的计算资源。尽管 Mesos 主要的设计目的是作为一个通用平台,但它特别适用于诸如 Spark、Hadoop、Kubernetes 等大型分布式系统的工作负载管理。在这些应用场景中,Mesos 提供了一种高效的方式来利用大量计算机节点的能力,使开发者无需关心底层硬件细节即可轻松构建和维护复杂的分布式架构。
Apache Mesos 包含三个主要组成部分:Master、Slave 和 Framework。Master 节点负责全局资源管理和调度决策,Slave 节点充当 Worker Node的角色,负责执行 Master 发布的具体任务,而 Framework 则是由开发人员编写的业务逻辑模块,它们注册到 Mesos 上面,等待 Master 分派任务。
Flume 和 Storm 是两个流行的大数据处理框架,它们都可以受益于 Mesos 的强大支撑。Flume 是一款用来收集、聚合和移动大体积日志数据的可靠系统,Storm 则是一款实时事件驱动的分布式计算引擎,常用于实时数据分析和处理。
虽然 Mesos 在大数据领域的运用广泛,但在 Kubernetes 成为主流容器化技术的时代背景下,Mesos 的市场份额逐渐受到挤压。如今,许多公司开始转向基于 Kubernetes 构建他们的大数据生态系统,因为 Kubernetes 已经成为事实上的容器编排标准。Kubernetes 提供了一系列强大的原生功能,如 Pod 自动伸缩、Service Discovery、持久卷挂载等,这些都是 Mesos 所不具备的优势。
总的来说,Mesos 曾经在大数据领域占据重要地位,但现在随着 Kubernetes 的崛起和发展趋势,越来越多的企业倾向于使用后者来搭建和管理他们的大数据平台。尽管如此,Mesos 仍然是那些追求高度定制性和灵活性的组织的理想之选。
Flink在Mesos上的使用主要是在大数据领域中。Mesos是一个开源的集群管理系统,它可以管理和调度多个框架的资源,从而提高了资源的利用率和系统的稳定性。使用Mesos可以让Flink与其他大数据框架(如Hadoop、Spark等)共享资源,提高了系统的整体性能和效率。
因此,在大数据领域中,Flink使用Mesos的情况相对较多。但是,这并不意味着在其他领域中Mesos就不常用。实际上,Mesos在云服务、容器化、边缘计算等领域也有广泛的应用。
总的来说,选择使用Mesos还是其他框架,取决于具体的应用场景和需求。在大数据领域中,由于Flink与Mesos的紧密集成和性能优势,使用Mesos的情况相对较多。但随着技术的发展和应用的扩展,其他框架和平台也可能成为更好的选择。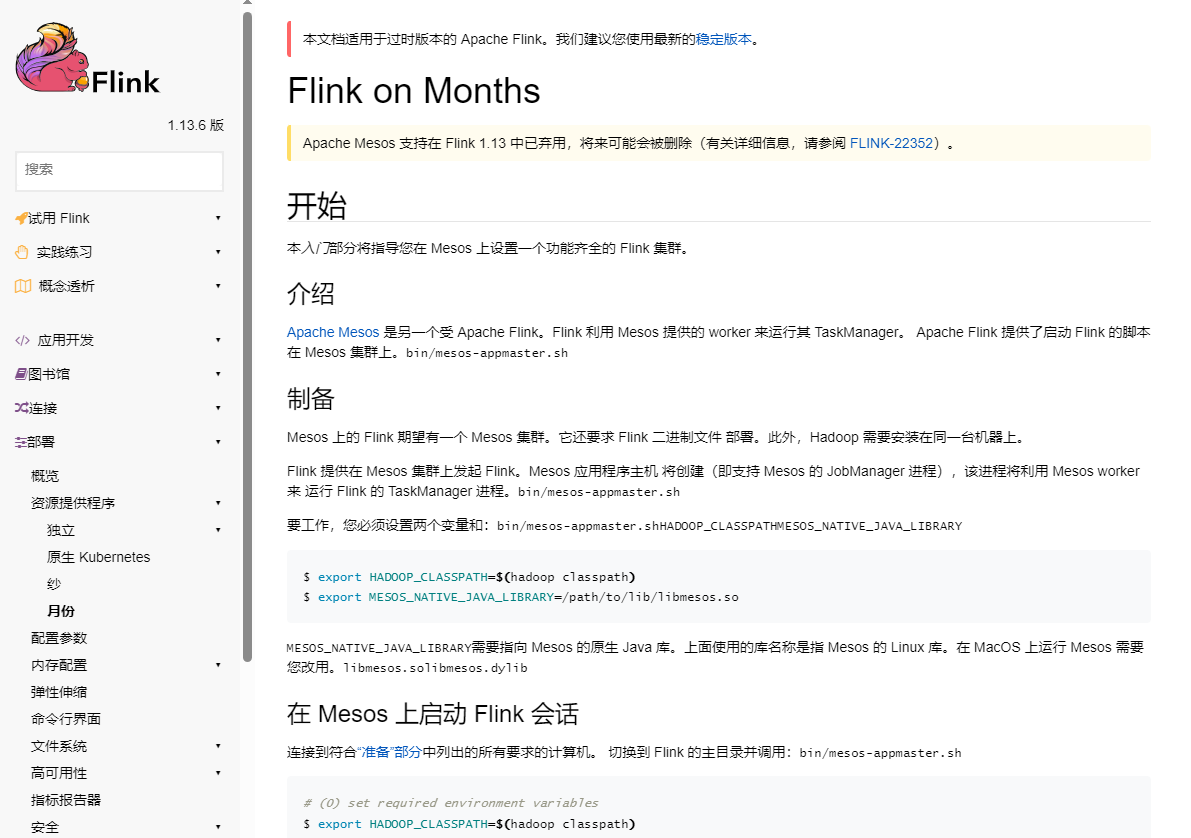
Apache Flink是一个分布式系统,需要计算资源才能执行应用程序。它与所有常见的集群资源管理器(如Hadoop YARN,Apache Mesos和Kubernetes)集成,但也可以设置为作为独立集群运行。Flink旨在很好地适用于这些资源管理器。
Apache Mesos是一种用于大规模数据处理的分布式系统内核。它提供了跨多个数据中心的资源管理和调度功能,支持分布式计算和数据处理工作负载。Mesos是一个高效的、可扩展的、可维护的解决方案,可以轻松地处理大量数据并支持各种数据处理框架,如Apache Flink、Apache Spark等。
在大数据领域,Apache Flink和Apache Mesos都是非常重要的技术。Flink是一个流处理框架,用于实时数据处理和流计算,而Mesos是一个资源调度平台,用于管理和调度大规模分布式计算任务。在处理大规模数据时,Flink和Mesos可以一起使用,以提供高效的分布式计算能力。
因此,对于大数据领域来说,Apache Flink和Apache Mesos都是非常重要的技术,可以根据具体的应用场景选择使用Flink或Mesos,或者将它们集成在一起使用,以提供更好的数据处理和计算能力。
Apache Flink是一个分布式流处理框架,主要用于处理大规模数据流和批处理。在大数据领域,Flink被广泛应用于实时流处理、批处理和数据管道等场景。至于Mesos,它是一个开源的集群管理平台,主要用于管理和调度大规模分布式计算资源。
在大数据领域,Apache Mesos可以与Flink等分布式计算框架集成,提供资源管理和调度功能。通过将Mesos与Flink集成,可以更好地管理和调度Flink作业所需的计算资源,提高资源利用率和作业性能。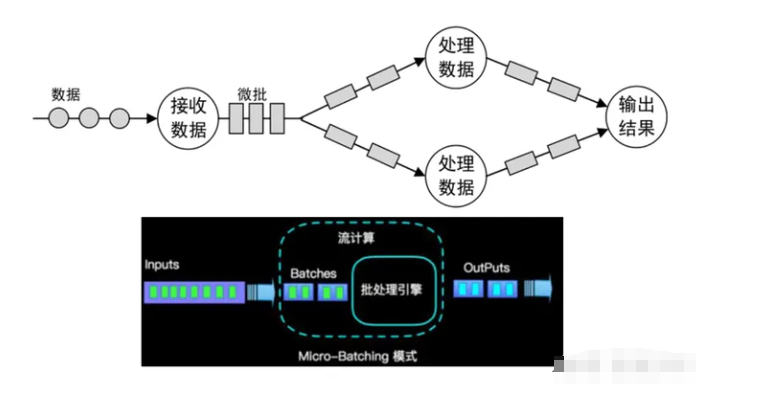
因此,虽然Flink本身是一个分布式流处理框架,但在大数据领域中,Mesos可以作为Flink的资源管理和调度平台,用于管理和调度大规模分布式计算资源。不过,具体使用哪种技术取决于实际需求和场景。
Apache Spark 社区更倾向于 Kubernetes,尤其是在大规模分布式环境中的扩展性和支持。
Spark on Kubernetes(SKR)是一个由社区驱动的努力,旨在使 Spark 应用能够在 Kubernetes 上轻松部署和运行。SKR 使用 Docker 封装 Spark 应用程序,并利用 Kubernetes 自带的功能,如自动缩放、高可用性和调度功能,提供更好的可移植性和一致性。
虽然 Mesos 曾经支持 Spark,但在最近几年里,它的市场份额逐渐下降,特别是在企业级环境中。相反,Kubernetes 成为主流的选择之一,不仅对 Spark,而且对其他流行的大数据框架,如 Apache Beam 和 Presto。
尽管 Mesos 当初在某些场景中有优势,但现在在 Kubernetes 上运行 Spark 应用已经成为主流趋势。如果您计划在生产环境中运行 Spark,我会建议优先考虑 Kubernetes。
Apache Flink是一个开源的流处理和批处理框架,设计用于分布式数据处理。Mesos是一种通用的集群管理器,可以有效地管理资源,如CPU、内存、磁盘和网络。在大数据领域,Flink on Mesos的应用逐渐增多,这是因为Mesos提供了一个高效的资源调度和管理机制,能够更好地支持Flink作业的运行。具体来说,Flink on Mesos可以利用Mesos的资源隔离和共享特性,更合理地分配和调度计算资源,从而提高大数据处理的效率和性能。然而,具体使用哪种部署方式,还需要根据实际业务需求和环境条件进行选择。
在Flink中,Mesos确实是一个流行的部署选项,特别是对于大数据应用。Mesos是一个强大的开源调度器,可以管理资源和运行容器化应用程序,包括Flink作业。Mesos在大数据领域中广泛使用,因为它可以轻松地扩展到数千个节点,并支持多种资源分配策略。
与Swarm和Kubernetes相比,Mesos在支持大数据应用方面具有以下优势:
Flink中Mesos在大数据领域中使用较多。Mesos是一个通用的集群管理器,可以管理各种类型的计算任务,包括批处理、流处理和交互式查询等。Flink作为一个分布式流处理框架,可以很好地与Mesos集成,利用Mesos提供的资源管理和调度功能来运行和管理Flink任务。
Apache Mesos 是另一个受 Apache Flink。Flink 利用 Mesos 提供的 worker 来运行其 TaskManager。 Apache Flink 提供了启动 Flink 的脚本 在 Mesos 集群上。bin/mesos-appmaster.sh
https://nightlies.apache.org/flink/flink-docs-release-1.13/zh/docs/deployment/resource-providers/mesos/
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


