
请问如何用flink sql客户端用yarn application模式提交任务呢?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在使用Flink SQL Client以YARN Application模式提交任务时,可以按照以下步骤进行操作:
1、 准备环境:
flink-conf.yaml和yarn-site.xml。2、 启动Flink SQL Client:
运行以下命令启动Flink SQL Client:
bash`./bin/sql-client.sh embedded -f <your_sql_file.sql>`
其中<your_sql_file.sql>是你要执行的SQL文件的路径。
3、 提交任务:
在Flink SQL Client的交互式命令行界面中,输入以下命令提交任务:
sql`INSERT INTO <output_table> SELECT * FROM <input_table> WHERE ...;`
其中<output_table>是你要输出的表名,<input_table>是你要输入的表名,WHERE ...是可选的筛选条件。
4、 设置YARN Application模式:
* 在提交任务之前,你需要设置Flink以YARN Application模式运行。可以通过以下命令设置:
```
sql`SET 'execution.target'='yarn';`
```
这将告诉Flink将任务提交到YARN集群上运行。
5、 检查任务状态:
* 在设置完YARN Application模式后,你可以使用以下命令查看任务的执行状态:
```
sql`SHOW JOBS;`
```
这将显示当前正在运行的任务列表,包括任务的ID、名称、状态等信息。
6、 结束任务:
* 当任务完成后,你可以使用以下命令结束任务:
```
sql`DISCARD ALL;`
```
这将终止所有正在运行的任务并清理资源。
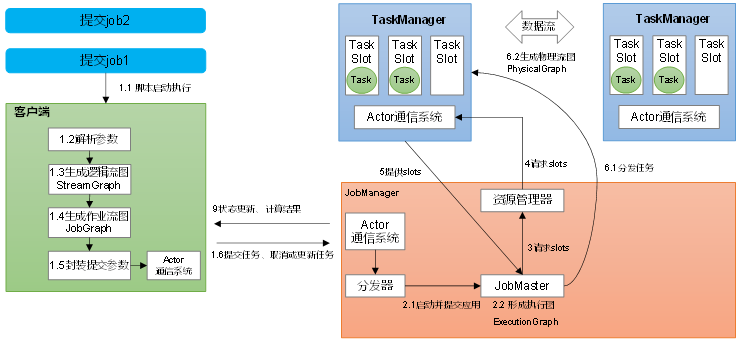
使用 Flink SQL 客户端以 YARN Application 模式提交任务,可以按照以下步骤进行操作:
准备环境:确保你已经安装了 Flink 和 YARN 的相关组件,并且已经配置好了 Flink 和 YARN 的运行环境。
启动 Flink SQL 客户端:打开终端或命令提示符,并输入以下命令启动 Flink SQL 客户端:
bash
./bin/flink-sql-client.sh embedded --jar --class
其中, 是你的 Flink 应用程序的 JAR 文件的路径, 是你的应用程序的入口类。
sql
SET 'execution.target'='yarn';
SET 'yarn.application.node-label'='';
SET 'yarn.application.name'='';
SET 'yarn.application.queue'='';
其中, 是你为 YARN 节点指定的标签, 是你的应用程序的名称, 是你希望提交应用程序的 YARN 队列名称。
sql
CREATE TABLE my_table (id INT, name STRING) WITH (...) ...;
INSERT INTO my_table SELECT * FROM ...;
RUN;
等待任务完成:提交查询后,Flink 会自动将任务提交给 YARN 进行调度和执行。你可以等待任务完成,并查看任务的结果。
结束 Flink SQL 客户端会话:当任务完成后,你可以使用以下命令结束 Flink SQL 客户端会话:
sql
SET 'execution.target'='local';
这将停止将任务提交给 YARN,并将执行模式设置为本地模式。然后,你可以输入 EXIT; 退出 Flink SQL 客户端。
这样,你就成功地使用 Flink SQL 客户端以 YARN Application 模式提交了任务。请确保根据你的实际情况修改相关配置和查询语句。
application模式提交一次任务会在Yarn运行一个Flink集群。不同之处为作业jar包的main方法在Yarn集群的JobManager上运行,而不是提交作业的client端运行。作业执行完毕后,Flink on yarn集群会被关闭。
flink run-application -t yarn-application /path/to/job.jar
application模式的好处是Flink yarn集群可以直接从HDFS上查找并下载作业jar以及所需依赖,避免了从client机器上传。
flink run-application -t yarn-application \
-Dyarn.provided.lib.dirs="hdfs://myhdfs/my-remote-flink-dist-dir" \
hdfs://myhdfs/jars/my-application.jar
其中yarn.provided.lib.dirs为Flink作业所需依赖包的地址。
从Flink1.12开始使用-t参数替代-m参数。使用-t之后原先的ynm,yqu等参数不在生效。需要使用-D指定。
——参考链接。
使用Flink SQL客户端以YARN Application模式提交任务时,通常需要以下步骤:
环境准备:
conf/flink-conf.yaml),确保包含了YARN相关配置项,例如ResourceManager地址、队列名等。构建SQL作业:
.sql文件。打包并上传依赖:
启动SQL客户端并指定YARN模式:
./bin/sql-client.sh启动SQL客户端,并通过-m yarn-application参数指定YARN Application模式。./bin/sql-client.sh -m yarn-application -ynm <your_job_name> -ys <yarn_session_config_file>
其中,
-ynm 指定YARN应用程序名称。-ys 可以用来指定包含YARN会话配置的文件路径,用于覆盖或添加更多YARN相关的配置项。提交SQL作业:
:run命令执行或加载SQL脚本文件。:run path/to/your/job.sql
或者直接在客户端内输入SQL语句执行。
具体的命令行选项可能会随着不同版本的Flink有所变化,因此在操作前最好参照Flink官方文档中对应版本的指导来进行操作。在实际环境中,可能还需要根据实际情况设置其他YARN相关的配置,比如是否启用高可用、指定YARN队列等。
为了使用YARN Application模式执行Flask SQL任务,您需要遵循以下步骤:
步骤一:准备YARN集群并安装Hadoop YARN服务
如果您还没有搭建好的YARN集群,则需要完成此步骤。您可以参照Hadoop官方网站上的指南来安装和配置YARN服务。
步骤二:编写Flink SQL脚本
接下来,我们需要为我们的任务写入一个Flink SQL脚本。假设您的脚本位于src/main/resources/my-query.sql下。
步骤三:编译Flink程序
打开终端,进入项目的根目录,输入以下命令来编译Flink程序:
./gradlew clean assemble -Pspark.master=yarn-cluster
该命令会在build/distributions目录生成一个可执行的jar文件。
步骤四:上传Jar文件至YARN集群
登录到YARN管理界面,选择“Application Manager”-> “New”。
在弹出的应用程序名称框里填写一个名字,点击下一步继续。
在下一个窗口中,选择“Local File”,然后浏览到刚刚编译后的jar文件,点击“Next”。这里需要注意的是,路径可能是相对路径,所以需要确保jar文件实际存在于本地磁盘上。
接着,选择“MapReduce v2 Application Master”,点击“Finish”。
步骤五:提交任务给YARN
回到YRNAManager主界面,可以看到刚才新建的任务已经在队列中等待调度了。选中它,点击右键,选择“Start”。
此时,YARN就会自动分配资源并将任务推送到各个节点上去执行。
这就是使用YARN Application模式提交Flink SQL任务的基本流程。不过值得注意的一点是,虽然这种方式可以在YARN上运行Flink任务,但它并没有提供完整的交互式Shell API,所以在调试和监控等方面可能会有所不便。
要使用Flink SQL客户端通过YARN应用程序模式提交任务,请按照以下步骤操作:
./bin/flink config
然后,您可以在配置文件中添加以下属性:
flink.yarn.mode: yarn
flink.yarn.application.id: application_id
其中,application_id是您为应用程序指定的ID。
./bin/flink sql --file /path/to/your/query.sql
./bin/flink run --class com.example.MyProgram --jar /path/to/your/your_application.jar --name my_task --entry-point com.example.MyProgram arg1 arg2 --yarn-application-id application_id --yarn-cluster-mode cluster --yarn-resource-manager-hostname resource_manager_hostname ./path/to/query.sql
其中,com.example.MyProgram是要运行的类的名称,/path/to/your/your_application.jar是包含应用程序的JAR文件的名称,arg1和arg2是要传递给程序的参数,application_id是您为应用程序指定的ID,cluster是要使用的YARN集群模式,resource_manager_hostname是YARN资源管理器的主机名。
提交任务后,您可以使用以下命令查看任务的状态:
./bin/flink tasklist
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


