带你了解Kubernetes架构的设计意图、Kubernetes系统的架构开发演进过程,以及背后的驱动原因。

1、背景
各种平台都会遇到一个不可回避的问题,即平台应该包含什么和不包含什么,Kubernetes也一样。Kubernetes作为一个部署和管理容器的平台,Kubernetes不能也不应该试图解决用户的所有问题。Kubernetes必须提供一些基本功能,用户可以在这些基本功能的基础上运行容器化的应用程序或构建它们的扩展。本文旨在明确Kubernetes架构的设计意图,描述Kubernetes的演进历程和未来的开发蓝图。
本文中,我们将描述Kubernetes系统的架构开发演进过程,以及背后的驱动原因。对于希望扩展或者定制kubernetes系统的开发者,其应该使用此文档作为向导,以明确可以在哪些地方,以及如何进行增强功能的实现。如果应用开发者需要开发一个大型的、可移植的和符合将来发展的kubernetes应用,也应该参考此文档,以了解Kubernetes将来的演化和发展。
核心层(Nucleus): 提供标准的API和执行机制,包括基本的REST机制,安全、Pod、容器、网络接口和存储卷管理,通过接口能够对这些API和执进行扩展,核心层是必需的,它是系统最核心的一部分。
应用管理层(Application Management Layer ):提供基本的部署和路由,包括自愈能力、弹性扩容、服务发现、负载均衡和流量路由。此层即为通常所说的服务编排,这些功能都提供了默认的实现,但是允许进行一致性的替换。
治理层(The Governance Layer):提供高层次的自动化和策略执行,包括单一和多租户、度量、智能扩容和供应、授权方案、网络方案、配额方案、存储策略表达和执行。这些都是可选的,也可以通过其它解决方案实现。
接口层(The Interface Layer):提供公共的类库、工具、用户界面和与Kubernetes API交互的系统。
生态层(The Ecosystem):包括与Kubernetes相关的所有内容,严格上来说这些并不是Kubernetes的组成部分。包括CI/CD、中间件、日志、监控、数据处理、PaaS、serverless/FaaS系统、工作流、容器运行时、镜像仓库、Node和云提供商管理等。
2、系统分层
就像Linux拥有内核(kernel)、核心系统类库、和可选的用户级工具,kubernetes也拥有功能和工具的层次。对于开发者来说,理解这些层次是非常重要的。kubernetes APIs、概念和功能都在下面的层级图中得到体现。
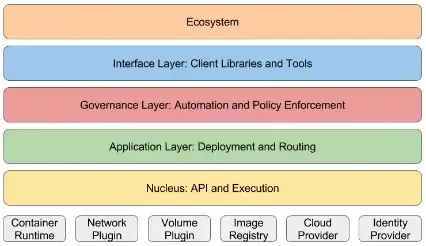
核心层包含最核心的API和执行机。
这些API和功能由上游的kubernetes代码库实现,由最小特性集和概念集所组成,这些特征和概念是系统上层所必需的。
这些由上游KubNeNETs代码库实现的API和函数包括建立系统的高阶层所需的最小特征集和概念集。这些内容被明确的地指定和记录,并且每个容器化的应用都会使用它们。开发人员可以安全地假设它们是一直存在的,这些内容应该是稳定和乏味的。
2.1.1 API和集群控制面板
Kubernetes集群提供了类似REST API的集,通过Kubernetes API server对外进行暴露,支持持久化资源的增删改查操作。这些API作为控制面板的枢纽。
遵循Kubernetes API约定(路径约定、标准元数据等)的REST API能够自动从共享API服务(认证、授权、审计日志)中收益,通用客户端代码能够与它们进行交互。
作为系统的最娣层,需要支持必要的扩展机制,以支持高层添加功能。另外,需要支持单租户和多租户的应用场景。核心层也需要提供足够的弹性,以支持高层能扩展新的范围,而不需要在安全模式方面进行妥协。
如果没有下面这些基础的API机和语义,Kubernetes将不能够正常工作:
认证(Authentication): 认证机制是非常关键的一项工作,在Kubernetes中需要通过服务器和客户端双方的认证通过。API server 支持基本认证模式 (用户命名/密码) (注意,在将来会被放弃), X.509客户端证书模式,OpenID连接令牌模式,和不记名令牌模式。通过kubeconfig支持,客户端能够使用上述各种认证模式。第三方认证系统可以实现TokenReview API,并通过配置认证webhook来调用,通过非标准的认证机制可以限制可用客户端的数量。
1、The TokenReview API (与hook的机制一样) 能够启用外部认证检查,例如Kubelet
2、Pod身份标识通过”service accounts“提供
3、The ServiceAccount API,包括通过控制器创建的默认ServiceAccount保密字段,并通过接入许可控制器进行注入。
授权(Authorization):第三方授权系统可以实现SubjectAccessReview API,并通过配置授权webhook进行调用。
1、SubjectAccessReview (与hook的机制一样), LocalSubjectAccessReview, 和SelfSubjectAccessReview APIs能启用外部的许可检查,诸如Kubelet和其它控制器。
REST 语义、监控、持久化和一致性保证、API版本控制、违约、验证
1、NIY:需要被解决的API缺陷:
2、混淆违约行为
3、缺少保障
4、编排支持
5、支持事件驱动的自动化
6、干净卸载
NIY: 内置的准入控制语义、同步准入控制钩子、异步资源初始化 — 发行商系统集成商,和集群管理员实现额外的策略和自动化
NIY:API注册和发行、包括API聚合、注册额外的API、发行支持的API、获得支持的操作、有效载荷和结果模式的详细信息。
NIY:ThirdPartyResource和ThirdPartyResourceData APIs (或她们的继承者),支持第三方存储和扩展API。
NIY:The Componentstatuses API的可扩展和高可用的替代,以确定集群是否完全体现和操作是否正确:ExternalServiceProvider (组件注册)
The Endpoints API,组件增持需要,API服务器端点的自我发布,高可用和应用层目标发行
The Namespace API,用户资源的范围,命名空间生命周期(例如:大量删除)
The Event API,用于对重大事件的发生进行报告,例如状态改变和错误,以及事件垃圾收集
NIY:级联删除垃圾收集器、finalization, 和orphaning
NIY: 需要内置的add-on的管理器 ,从而能够自动添加自宿主的组件和动态配置到集群,在运行的集群中提取出功能。
1、Add-ons应该是一个集群服务,作为集群的一部分进行管理
2、它们可以运行在kube-system命名空间,这么就不会与用户的命名进行冲突
API server作为集群的网关。根据定义,API server必需能够被集群外的客户端访问,而Node和Pod是不被集群外的客户端访问的。客户端认证API server,并使用API server作为堡垒和代理/通道来通过/proxy和/portforward API访问Node和Pod等Clients authenticate the API server and also use it
TBD:The CertificateSigningRequest API,能够启用认证创建,特别是kubele证书。
理想情况下,核心层API server江仅仅支持最小的必需的API,额外的功能通过聚合、钩子、初始化器、和其它扩展机制来提供。注意,中心化异步控制器以名为Controller Manager的独立进程运行,例如垃圾收集。
API server依赖下面的外部组件:
持久化状态存储 (etcd,或相对应的其它系统;可能会存在多个实例)
API server可以依赖:
身份认证提供者
The TokenReview API实现者 实现者
The SubjectAccessReview API实现者
2.1.2 执行
在Kubernetes中最重要的控制器是kubelet,它是Pod和Node API的主要实现者,没有这些API的话,Kubernetes将仅仅只是由键值对存储(后续,API机最终可能会被作为一个独立的项目)支持的一个增删改查的REST应用框架。
Kubernetes默认执行独立的应用容器和本地模式。
Kubernetes提供管理多个容器和存储卷的Pod,Pod在Kubernetes中作为最基本的执行单元。
Kubelet API语义包括:
The Pod API,Kubernetes执行单元,包括:
1、Pod可行性准入控制基于Pod API中的策略(资源请求、Node选择器、node/pod affinity and anti-affinity, taints and tolerations)。API准入控制可以拒绝Pod或添加额外的调度约束,但Kubelet才是决定Pod最终被运行在哪个Node上的决定者,而不是schedulers or DaemonSets。
2、容器和存储卷语义和生命周期
3、Pod IP地址分配(每个Pod要求一个可路由的IP地址)
4、将Pod连接至一个特定安全范围的机制(i.e., ServiceAccount)
5、存储卷来源:
5.1、emptyDir
5.2、hostPath
5.3、secret
5.4、configMap
5.5、downwardAPI
5.6、NIY:容器和镜像存储卷 (and deprecate gitRepo)
5.7、NIY:本地存储,对于开发和生产应用清单不需要复杂的模板或独立配置
5.8、flexVolume (应该替换内置的cloud-provider-specific存储卷)
6、子资源:绑定、状态、执行、日志、attach、端口转发、代理
1、在一些配置中,可以仅仅对集群管理员可见
1、Cloud-provider-specific node库存功能应该被分成特定提供者的控制器
1、Cloud-provider-specific attach/detach逻辑应该被分成特定提供者的控制器,需要一种方式从API中提取特定提供者的存储卷来源。
1、NIY:至少被本地存储所支持
中心化异步功能,诸如由Controller Manager执行的pod终止垃圾收集。
当前,控制过滤器和kubelet调用“云提供商”接口来询问来自于基础设施层的信息,并管理基础设施资源。然而,kubernetes正在努力将这些触摸点(问题)提取到外部组件中,不可满足的应用程序/容器/OS级请求(例如,PODS,PersistentVolumeClaims)作为外部“动态供应”系统的信号,这将使基础设施能够满足这些请求,并使用基础设施资源(例如,Node、和PersistentVolumes)在Kubernetes进行表示,这样Kubernetes可以将请求和基础设施资源绑定在一起。
对于kubelet,它依赖下面的可扩展组件:
以及可能依赖:
2.2 应用层:部署和路由
应用管理和组合层,提供自愈、扩容、应用生命周期管理、服务发现、负载均衡和路由— 也即服务编排和service fabric。这些API和功能是所有Kubernetes分发所需要的,Kubernetes应该提供这些API的默认实现,当然可以使用替代的实现方案。没有应用层的API,大部分的容器化应用将不能运行。
Kubernetes’s API提供类似IaaS的以容器为中心的基础单元,以及生命周期控制器,以支持所有工作负载的编排(自愈、扩容、更新和终止)。这些应用管理、组合、发现、和路由API和功能包括:
1、The Deployment API,编排更新无状态的应用,包括子资源(状态、扩容和回滚)
2、The DaemonSet API,集群服务,包括子资源(状态)
3、The StatefulSet API,有状态应用,包括子资源(状态、扩容)
4、The PodTemplate API,由DaemonSet和StatefulSet用来记录变更历史
1、The Job API (GC discussion)
2、The CronJob API
1、The Service API,包括集群IP地址分配,修复服务分配映射,通过kube-proxy或者对等的功能实现服务的负载均衡,自动化创建端点,维护和删除。NIY:负载均衡服务是可选的,如果被支持的化,则需要通过一致性的测试。
2、The Ingress API,包括internal L7 (NIY)
3、服务DNS。DNS使用official Kubernetes schema。
应用层可以依赖:
2.3 治理层:自动化和策略执行
策略执行和高层自动化。这些API和功能是运行应用的可选功能,应该挺其它的解决方案实现。
每个支持的API/功能应用作为企业操作、安全和治理场景的一部分。
需要为集群提供可能的配置和发现默认策略,至少支持如下的用例:
需要关注的内容:
1、资源使用
2、Node内部分割
3、最终用户
4、管理员
5、服务质量(DoS)
自动化APIs和功能:
1、The StorageClass API,至少有一个默认存储卷类型的实现
策略APIs和功能:
授权:ABAC和RBAC授权策略方案
1、RBAC,实现下面的API:Role, RoleBinding, ClusterRole, ClusterRoleBinding
管理层依赖:
2.4 接口层:类库和工具
这些机制被建议用于应用程序版本的分发,用户也可以用其进行下载和安装。它们包括Kubernetes官方项目开发的通用的类库、工具、系统、界面,它们可以用来发布。
这些组件依赖:
2.5 生态
在有许多领域,已经为Kubernetes定义了明确的界限。虽然,Kubernetes必须提供部署和管理容器化应用需要的通用功能。但作为一般规则,在对Kubernete通用编排功能进行补足的功能领域,Kubernetes保持了用户的选择。特别是那些有自己的竞争优势的区域,特别是能够满足不同需求和偏好的众多解决方案。Kubernetes可以为这些解决方案提供插件API,或者可以公开由多个后端实现的通用API,或者公开此类解决方案可以针对的API。有时,功能可以与Kubernetes干净地组合在而不需要显式接口。
此外,如果考虑成为Kubernetes的一部分,组件就需要遵循Kubernetes设计约定。例如,主要接口使用特定域语言的系统(例如,Puppet、Open Policy Agent)与Kubenetes API的方法不兼容,可以与Kubernetes一起使用,但不会被认为是Kubernetes的一部分。类似地,被设计用来支持多平台的解决方案可能不会遵循Kubernetes API协议,因此也不会被认为是Kubernetes的一部分。
1、持久化集成和部署(CI/CD):Kubernetes不提供从源代码到镜像的能力。Kubernetes 不部署源代码和不构建应用。用户和项目可以根据自身的需要选择持久化集成和持久化部署工作流,Kubernetes的目标是方便CI/CD的使用,而不是命令它们如何工作。
2、应用中间件:Kubernetes不提供应用中间件作为内置的基础设施,例如:消息队列和SQL数据库。然而,可以提供通用目的的机制使其能够被容易的提供、发现和访问。理想的情况是这些组件仅仅运行在Kubernetes上。
3、日志和监控:Kubernetes本身不提供日志聚合和综合应用监控的能力,也没有遥测分析和警报系统,虽然日志和监控的机制是Kubernetes集群必不可少的部分。
4、数据处理平台:在数据处理平台方面,Spark和Hadoop是还有名的两个例子,但市场中还存在很多其它的系统。
5、特定应用运算符:Kubernetes支持通用类别应用的工作负载管理。
6、平台即服务 Paas:Kubernetes为Paas提供基础。
7、功能即服务 FaaS:与PaaS类似,但Faa侵入容器和特定语言的应用框架。
8、工作量编排: “工作流”是一个非常广泛的和多样化的领域,通常针对特定的用例场景(例如:数据流图、数据驱动处理、部署流水线、事件驱动自动化、业务流程执行、iPAAS)和特定输入和事件来源的解决方案,并且通常需要通过编写代码来实现。
9、配置特定领域语言:特定领域的语言不利于分层高级的API和工具,它们通常具有有限的可表达性、可测试性、熟悉性和文档性。它们复杂的配置生成,它们倾向于在互操作性和可组合性间进行折衷。它们使依赖管理复杂化,并经常颠覆性的抽象和封装。
10、Kompose:Kompose是一个适配器工具,它有助于从Docker Compose迁移到Kubernetes ,并提供简单的用例。Kompose不遵循Kubernetes约定,而是基于手动维护的DSL。
11、ChatOps:也是一个适配器工具,用于聊天服务。
1、容器运行时:Kubernetes本身不提供容器运行时环境,但是其提供了接口,可以来插入所选择的容器运行时。
2、镜像仓库:Kubernetes本身不提供容器的镜像,可通过Harbor、Nexus和docker registry等搭建镜像仓库,以为集群拉取需要的容器镜像。
3、集群状态存储:用于存储集群运行状态,例如默认使用Etcd,但也可以使用其它存储系统。
4、网络:与容器运行时一样,Kubernetes提供了接入各种网络插件的容器网络接口(CNI)。
5、文件存储:本地文件系统和网络存储
6、Node管理:Kubernetes既不提供也不采用任何综合的机器配置、维护、管理或自愈系统。通常针对不同的公有/私有云,针对不同的操作系统,针对可变的和不可变的基础设施。
7、云提供者:IaaS供应和管理。
8、集群创建和管理:社区已经开发了很多的工具,利润minikube、kubeadm、bootkube、kube-aws、kops、kargo, kubernetes-anywhere等待。 从工具的多样性可以看出,集群部署和管理(例如,升级)没有一成不变的解决方案。也就是说,常见的构建块(例如,安全的Kubelet注册)和方法(特别是自托管)将减少此类工具中所需的自定义编排的数量。
后续,希望通过建立Kubernetes的生态系统,并通过整合相关的解决方案来满足上述需求。
矩阵管理
选项、可配置的默认、扩展、插件、附加组件、特定于提供者的功能、版本管理、特征发现和依赖性管理。
Kubernetes不仅仅是一个开源的工具箱,而且是一个典型集群或者服务的运行环境。 Kubernetes希望大多数用户和用例能够使用上游版本,这意味着Kubernetes需要足够的可扩展性,而不需要通过重建来处理各种场景。
虽然在可扩展性方面的差距是代码分支的主要驱动力,而上游集群生命周期管理解决方案中的差距是当前Kubernetes分发的主要驱动因素,可选特征的存在(例如,alpha API、提供者特定的API)、可配置性、插件化和可扩展性使概念不可避免。
然而,为了使用户有可能在Kubernetes上部署和管理他们的应用程序,为了使开发人员能够在Kubernetes集群上构建构建Kubernetes扩展,他们必须能够对Kubernetes集群或分发提供一个假设。在基本假设失效的情况下,需要找到一种方法来发现可用的功能,并表达功能需求(依赖性)以供使用。
集群组件,包括add-ons,应该通过组件注册 API进行注册和通过/componentstatuses进行发现。
启用内置API、聚合API和注册的第三方资源,应该可以通过发现和OpenAPI(Savigj.JSON)端点来发现。如上所述,LoadBalancer类型服务的云服务提供商应该确定负载均衡器API是否存在。
类似于StorageClass,扩展和它们的选项应该通过FoeClass资源进行注册。但是,使用参数描述、类型(例如,整数与字符串)、用于验证的约束(例如,ranger或regexp)和默认值,从扩展API中引用fooClassName。这些API应该配置/暴露相关的特征的存在,例如动态存储卷供应(由非空的storageclass.provisioner字段指示),以及标识负责的控制器。需要至少为调度器类、ingress控制器类、Flex存储卷类和计算资源类(例如GPU、其他加速器)添加这样的API。
假设我们将现有的网络存储卷转换为flex存储卷,这种方法将会覆盖存储卷来源。在将来,API应该只提供通用目的的抽象,即使与LoadBalancer服务一样,抽象并不需要在所有的环境中都实现(即,API不需要迎合最低公共特性)。
NIY:需要为注册和发现开发下面的机制:
NIY:单个API和细粒度特征的激活/失活可以通过以下机制解决:
NIY:版本管理操作的问题,取决于多个组件的升级(包括在HA集群中的相同组件的副本),应该通过以下方式来解决:
为所有新的特性创建flag网关
总是在它们出现的第一个小版本中,默认禁用这些特性,
提供启用特性的配置补丁;
在接下来的小版本中默认启用这些特性
NIY:我们还需要一个机制来警告过时的节点,和/或潜在防止Master升级(除了补丁发布),直到/除非Node已经升级。
NIY:字段级版本管理将有助于大量激活新的和/或alpha API字段的解决方案,防止不良写入过时的客户端对新字段的阻塞,以及非alpha API的演进,而不需要成熟的API定义的扩散。
Kubernetes API server忽略不支持的资源字段和查询参数,但不忽略未知的/未注册的API(注意禁用未实现的/不活动的API)。这有助于跨多个版本的集群重用配置,但往往会带来意外。Kubctl支持使用服务器的Wagger/OpenAPI规范进行可选验证。这样的可选验证,应该由服务器(NYY)提供。此外,为方便用户,共享资源清单应该指定Kubernetes版本最小的要求,这可能会被kubectl和其他客户端验证。
服务目录机制(NIY)应该能够断言应用级服务的存在,例如S3兼容的群集存储。
与安全相关的系统分层
为了正确地保护Kubernetes集群并使其能够安全扩展,一些基本概念需要由系统的组件进行定义和约定。最好从安全的角度把Kubernetes看作是一系列的环,每个层都赋予连续的层功能去行动。
如果上面描述的层定义了同心圆,那么它也应该可能存在重叠或独立的圆-例如,管理员可以选择一个替代的秘密存储解决方案,集群工作负载可以访问,但是平台并不隐含地具有访问权限。这些圆圈的交点往往是运行工作负载的机器,并且节点必须没有比正常功能所需的特权更多的特权。
最后,在任何层通过扩展添加新的能力,应该遵循最佳实践来传达该行为的影响。
当一个能力通过扩展被添加到系统时,它有什么目的?
使系统更加安全
为集群中的每一个人,启用新的“生产质量”API
在集群的子集上自动完成一个公共任务
运行一个向用户提供API的托管工作负载(spark、数据库、etcd)
它们被分为三大类:
1、集群所需的(因此必须在内核附近运行,并在存在故障时导致操作权衡)
2、暴露于所有集群用户(必须正确地租用)
3、暴露于集群用户的子集(像传统的“应用程序”工作负载运行)
------------
1、背景
各种平台都会遇到一个不可回避的问题,即平台应该包含什么和不包含什么,Kubernetes也一样。Kubernetes作为一个部署和管理容器的平台,Kubernetes不能也不应该试图解决用户的所有问题。Kubernetes必须提供一些基本功能,用户可以在这些基本功能的基础上运行容器化的应用程序或构建它们的扩展。本文旨在明确Kubernetes架构的设计意图,描述Kubernetes的演进历程和未来的开发蓝图。
本文中,我们将描述Kubernetes系统的架构开发演进过程,以及背后的驱动原因。对于希望扩展或者定制kubernetes系统的开发者,其应该使用此文档作为向导,以明确可以在哪些地方,以及如何进行增强功能的实现。如果应用开发者需要开发一个大型的、可移植的和符合将来发展的kubernetes应用,也应该参考此文档,以了解Kubernetes将来的演化和发展。
从逻辑上来看,kubernetes的架构分为如下几个层次:
核心层(Nucleus): 提供标准的API和执行机制,包括基本的REST机制,安全、Pod、容器、网络接口和存储卷管理,通过接口能够对这些API和执进行扩展,核心层是必需的,它是系统最核心的一部分。
应用管理层(Application Management Layer ):提供基本的部署和路由,包括自愈能力、弹性扩容、服务发现、负载均衡和流量路由。此层即为通常所说的服务编排,这些功能都提供了默认的实现,但是允许进行一致性的替换。
治理层(The Governance Layer):提供高层次的自动化和策略执行,包括单一和多租户、度量、智能扩容和供应、授权方案、网络方案、配额方案、存储策略表达和执行。这些都是可选的,也可以通过其它解决方案实现。
接口层(The Interface Layer):提供公共的类库、工具、用户界面和与Kubernetes API交互的系统。
生态层(The Ecosystem):包括与Kubernetes相关的所有内容,严格上来说这些并不是Kubernetes的组成部分。包括CI/CD、中间件、日志、监控、数据处理、PaaS、serverless/FaaS系统、工作流、容器运行时、镜像仓库、Node和云提供商管理等。
2、系统分层
就像Linux拥有内核(kernel)、核心系统类库、和可选的用户级工具,kubernetes也拥有功能和工具的层次。对于开发者来说,理解这些层次是非常重要的。kubernetes APIs、概念和功能都在下面的层级图中得到体现。
2.1 核心层:API和执行(The Nucleus: API and Execution)
核心层包含最核心的API和执行机。
这些API和功能由上游的kubernetes代码库实现,由最小特性集和概念集所组成,这些特征和概念是系统上层所必需的。
这些由上游KubNeNETs代码库实现的API和函数包括建立系统的高阶层所需的最小特征集和概念集。这些内容被明确的地指定和记录,并且每个容器化的应用都会使用它们。开发人员可以安全地假设它们是一直存在的,这些内容应该是稳定和乏味的。
2.1.1 API和集群控制面板
Kubernetes集群提供了类似REST API的集,通过Kubernetes API server对外进行暴露,支持持久化资源的增删改查操作。这些API作为控制面板的枢纽。
遵循Kubernetes API约定(路径约定、标准元数据等)的REST API能够自动从共享API服务(认证、授权、审计日志)中收益,通用客户端代码能够与它们进行交互。
作为系统的最娣层,需要支持必要的扩展机制,以支持高层添加功能。另外,需要支持单租户和多租户的应用场景。核心层也需要提供足够的弹性,以支持高层能扩展新的范围,而不需要在安全模式方面进行妥协。
如果没有下面这些基础的API机和语义,Kubernetes将不能够正常工作:
认证(Authentication): 认证机制是非常关键的一项工作,在Kubernetes中需要通过服务器和客户端双方的认证通过。API server 支持基本认证模式 (用户命名/密码) (注意,在将来会被放弃), X.509客户端证书模式,OpenID连接令牌模式,和不记名令牌模式。通过kubeconfig支持,客户端能够使用上述各种认证模式。第三方认证系统可以实现TokenReview API,并通过配置认证webhook来调用,通过非标准的认证机制可以限制可用客户端的数量。
1、The TokenReview API (与hook的机制一样) 能够启用外部认证检查,例如Kubelet
2、Pod身份标识通过”service accounts“提供
3、The ServiceAccount API,包括通过控制器创建的默认ServiceAccount保密字段,并通过接入许可控制器进行注入。
授权(Authorization):第三方授权系统可以实现SubjectAccessReview API,并通过配置授权webhook进行调用。
1、SubjectAccessReview (与hook的机制一样), LocalSubjectAccessReview, 和SelfSubjectAccessReview APIs能启用外部的许可检查,诸如Kubelet和其它控制器。
REST 语义、监控、持久化和一致性保证、API版本控制、违约、验证
1、NIY:需要被解决的API缺陷:
2、混淆违约行为
3、缺少保障
4、编排支持
5、支持事件驱动的自动化
6、干净卸载
NIY: 内置的准入控制语义、同步准入控制钩子、异步资源初始化 — 发行商系统集成商,和集群管理员实现额外的策略和自动化
NIY:API注册和发行、包括API聚合、注册额外的API、发行支持的API、获得支持的操作、有效载荷和结果模式的详细信息。
NIY:ThirdPartyResource和ThirdPartyResourceData APIs (或她们的继承者),支持第三方存储和扩展API。
NIY:The Componentstatuses API的可扩展和高可用的替代,以确定集群是否完全体现和操作是否正确:ExternalServiceProvider (组件注册)
The Endpoints API,组件增持需要,API服务器端点的自我发布,高可用和应用层目标发行
The Namespace API,用户资源的范围,命名空间生命周期(例如:大量删除)
The Event API,用于对重大事件的发生进行报告,例如状态改变和错误,以及事件垃圾收集
NIY:级联删除垃圾收集器、finalization, 和orphaning
NIY: 需要内置的add-on的管理器 ,从而能够自动添加自宿主的组件和动态配置到集群,在运行的集群中提取出功能。
1、Add-ons应该是一个集群服务,作为集群的一部分进行管理
2、它们可以运行在kube-system命名空间,这么就不会与用户的命名进行冲突
API server作为集群的网关。根据定义,API server必需能够被集群外的客户端访问,而Node和Pod是不被集群外的客户端访问的。客户端认证API server,并使用API server作为堡垒和代理/通道来通过/proxy和/portforward API访问Node和Pod等Clients authenticate the API server and also use it
TBD:The CertificateSigningRequest API,能够启用认证创建,特别是kubele证书。
理想情况下,核心层API server江仅仅支持最小的必需的API,额外的功能通过聚合、钩子、初始化器、和其它扩展机制来提供。注意,中心化异步控制器以名为Controller Manager的独立进程运行,例如垃圾收集。
API server依赖下面的外部组件:
持久化状态存储 (etcd,或相对应的其它系统;可能会存在多个实例)
API server可以依赖:
身份认证提供者
The TokenReview API实现者 实现者
The SubjectAccessReview API实现者
2.1.2 执行
在Kubernetes中最重要的控制器是kubelet,它是Pod和Node API的主要实现者,没有这些API的话,Kubernetes将仅仅只是由键值对存储(后续,API机最终可能会被作为一个独立的项目)支持的一个增删改查的REST应用框架。
Kubernetes默认执行独立的应用容器和本地模式。
Kubernetes提供管理多个容器和存储卷的Pod,Pod在Kubernetes中作为最基本的执行单元。
Kubelet API语义包括:
The Pod API,Kubernetes执行单元,包括:
1、Pod可行性准入控制基于Pod API中的策略(资源请求、Node选择器、node/pod affinity and anti-affinity, taints and tolerations)。API准入控制可以拒绝Pod或添加额外的调度约束,但Kubelet才是决定Pod最终被运行在哪个Node上的决定者,而不是schedulers or DaemonSets。
2、容器和存储卷语义和生命周期
3、Pod IP地址分配(每个Pod要求一个可路由的IP地址)
4、将Pod连接至一个特定安全范围的机制(i.e., ServiceAccount)
5、存储卷来源:
5.1、emptyDir
5.2、hostPath
5.3、secret
5.4、configMap
5.5、downwardAPI
5.6、NIY:容器和镜像存储卷 (and deprecate gitRepo)
5.7、NIY:本地存储,对于开发和生产应用清单不需要复杂的模板或独立配置
5.8、flexVolume (应该替换内置的cloud-provider-specific存储卷)
6、子资源:绑定、状态、执行、日志、attach、端口转发、代理
- NIY:可用性和引导API 资源检查点
- 容器镜像和日志生命周期
- The Secret API,启用第三方加密管理
- The ConfigMap API,用于组件配置和Pod引用
- The Node API,Pod的宿主
1、在一些配置中,可以仅仅对集群管理员可见
- Node和pod网络,业绩它们的控制(路由控制器)
- Node库存、健康、和可达性(node控制器)
1、Cloud-provider-specific node库存功能应该被分成特定提供者的控制器
- pod终止垃圾收集
- 存储卷控制器
1、Cloud-provider-specific attach/detach逻辑应该被分成特定提供者的控制器,需要一种方式从API中提取特定提供者的存储卷来源。
- The PersistentVolume API
1、NIY:至少被本地存储所支持
- The PersistentVolumeClaim API
中心化异步功能,诸如由Controller Manager执行的pod终止垃圾收集。
当前,控制过滤器和kubelet调用“云提供商”接口来询问来自于基础设施层的信息,并管理基础设施资源。然而,kubernetes正在努力将这些触摸点(问题)提取到外部组件中,不可满足的应用程序/容器/OS级请求(例如,PODS,PersistentVolumeClaims)作为外部“动态供应”系统的信号,这将使基础设施能够满足这些请求,并使用基础设施资源(例如,Node、和PersistentVolumes)在Kubernetes进行表示,这样Kubernetes可以将请求和基础设施资源绑定在一起。
对于kubelet,它依赖下面的可扩展组件:
- 镜像注册
- 容器运行时接口实现
- 容器网络接口实现
- FlexVolume 实现(”CVI” in the diagram)
以及可能依赖:
- NIY:第三方加密管理系统(例如:Vault)
- NIY:凭证创建和转换控制器
2.2 应用层:部署和路由
应用管理和组合层,提供自愈、扩容、应用生命周期管理、服务发现、负载均衡和路由— 也即服务编排和service fabric。这些API和功能是所有Kubernetes分发所需要的,Kubernetes应该提供这些API的默认实现,当然可以使用替代的实现方案。没有应用层的API,大部分的容器化应用将不能运行。
Kubernetes’s API提供类似IaaS的以容器为中心的基础单元,以及生命周期控制器,以支持所有工作负载的编排(自愈、扩容、更新和终止)。这些应用管理、组合、发现、和路由API和功能包括:
- 默认调度,在Pod API中实现调度策略:资源请求、nodeSelector、node和pod affinity/anti-affinity、taints and tolerations. 调度能够作为一个独立的进度在集群内或外运行。
- NIY:重新调度器 ,反应和主动删除已调度的POD,以便它们可以被替换并重新安排到其他Node
- 持续运行应用:这些应用类型应该能够通过声明式更新、级联删除、和孤儿/领养支持发布(回滚)。除了DaemonSet,应该能支持水平扩容。
1、The Deployment API,编排更新无状态的应用,包括子资源(状态、扩容和回滚)
2、The DaemonSet API,集群服务,包括子资源(状态)
3、The StatefulSet API,有状态应用,包括子资源(状态、扩容)
4、The PodTemplate API,由DaemonSet和StatefulSet用来记录变更历史
- 终止批量应用:这些应该包括终止jobs的自动剔除(NIY)
1、The Job API (GC discussion)
2、The CronJob API
- 发现、负载均衡和路由
1、The Service API,包括集群IP地址分配,修复服务分配映射,通过kube-proxy或者对等的功能实现服务的负载均衡,自动化创建端点,维护和删除。NIY:负载均衡服务是可选的,如果被支持的化,则需要通过一致性的测试。
2、The Ingress API,包括internal L7 (NIY)
3、服务DNS。DNS使用official Kubernetes schema。
应用层可以依赖:
- 身份提供者 (集群的身份和/或应用身份)
- NIY:云提供者控制器实现
- Ingress controller(s)
- 调度器和重新调度器的替代解决方案
- DNS服务替代解决方案
- kube-proxy替代解决方案
- 工作负载控制器替代解决方案和/或辅助,特别是用于扩展发布策略
2.3 治理层:自动化和策略执行
策略执行和高层自动化。这些API和功能是运行应用的可选功能,应该挺其它的解决方案实现。
每个支持的API/功能应用作为企业操作、安全和治理场景的一部分。
需要为集群提供可能的配置和发现默认策略,至少支持如下的用例:
- 单一租户/单一用户集群
- 多租户集群
- 生产和开发集群
- Highly tenanted playground cluster
- 用于将计算/应用服务转售给他人的分段集群
需要关注的内容:
1、资源使用
2、Node内部分割
3、最终用户
4、管理员
5、服务质量(DoS)
自动化APIs和功能:
- 度量APIs (水平/垂直自动扩容的调度任务表)
- 水平Pod自动扩容API
- NIY:垂直Pod自动扩容API(s)
- 集群自动化扩容和Node供应
- The PodDisruptionBudget API
- 动态存储卷供应,至少有一个出厂价来源类型
1、The StorageClass API,至少有一个默认存储卷类型的实现
- 动态负载均衡供应
- NIY:PodPreset API
- NIY:service broker/catalog APIs
- NIY:Template和TemplateInstance APIs
策略APIs和功能:
授权:ABAC和RBAC授权策略方案
1、RBAC,实现下面的API:Role, RoleBinding, ClusterRole, ClusterRoleBinding
- The LimitRange API
- The ResourceQuota API
- The PodSecurityPolicy API
- The ImageReview API
- The NetworkPolicy API
管理层依赖:
- 网络策略执行机制
- 替换、水平和垂直Pod扩容
- 集群自动扩容和Node提供者
- 动态存储卷提供者
- 动态负载均衡提供者
- 度量监控pipeline,或者它的替换
- 服务代理
2.4 接口层:类库和工具
这些机制被建议用于应用程序版本的分发,用户也可以用其进行下载和安装。它们包括Kubernetes官方项目开发的通用的类库、工具、系统、界面,它们可以用来发布。
- Kubectl — kubectl作为很多客户端工具中的一种,Kubernetes的目标是使Kubectl更薄,通过将常用的非平凡功能移动到API中。这是必要的,以便于跨Kubernetes版本的正确操作,并促进API的扩展性,以保持以API为中心的Kubernetes生态系统模型,并简化其它客户端,尤其是非GO客户端。
- 客户端类库(例如:client-go, client-python)
- 集群联邦(API server, controllers, kubefed)
- Dashboard
- Helm
这些组件依赖:
- Kubectl扩展
- Helm扩展
2.5 生态
在有许多领域,已经为Kubernetes定义了明确的界限。虽然,Kubernetes必须提供部署和管理容器化应用需要的通用功能。但作为一般规则,在对Kubernete通用编排功能进行补足的功能领域,Kubernetes保持了用户的选择。特别是那些有自己的竞争优势的区域,特别是能够满足不同需求和偏好的众多解决方案。Kubernetes可以为这些解决方案提供插件API,或者可以公开由多个后端实现的通用API,或者公开此类解决方案可以针对的API。有时,功能可以与Kubernetes干净地组合在而不需要显式接口。
此外,如果考虑成为Kubernetes的一部分,组件就需要遵循Kubernetes设计约定。例如,主要接口使用特定域语言的系统(例如,Puppet、Open Policy Agent)与Kubenetes API的方法不兼容,可以与Kubernetes一起使用,但不会被认为是Kubernetes的一部分。类似地,被设计用来支持多平台的解决方案可能不会遵循Kubernetes API协议,因此也不会被认为是Kubernetes的一部分。
- 内部的容器镜像:Kubernetes不提供容器镜像的内容。 如果某些内容被设计部署在容器镜像中,则其不应该直接被考虑作为Kubernetes的一部分。例如,基于特定语言的框架。
- 在Kubernetes的顶部
1、持久化集成和部署(CI/CD):Kubernetes不提供从源代码到镜像的能力。Kubernetes 不部署源代码和不构建应用。用户和项目可以根据自身的需要选择持久化集成和持久化部署工作流,Kubernetes的目标是方便CI/CD的使用,而不是命令它们如何工作。
2、应用中间件:Kubernetes不提供应用中间件作为内置的基础设施,例如:消息队列和SQL数据库。然而,可以提供通用目的的机制使其能够被容易的提供、发现和访问。理想的情况是这些组件仅仅运行在Kubernetes上。
3、日志和监控:Kubernetes本身不提供日志聚合和综合应用监控的能力,也没有遥测分析和警报系统,虽然日志和监控的机制是Kubernetes集群必不可少的部分。
4、数据处理平台:在数据处理平台方面,Spark和Hadoop是还有名的两个例子,但市场中还存在很多其它的系统。
5、特定应用运算符:Kubernetes支持通用类别应用的工作负载管理。
6、平台即服务 Paas:Kubernetes为Paas提供基础。
7、功能即服务 FaaS:与PaaS类似,但Faa侵入容器和特定语言的应用框架。
8、工作量编排: “工作流”是一个非常广泛的和多样化的领域,通常针对特定的用例场景(例如:数据流图、数据驱动处理、部署流水线、事件驱动自动化、业务流程执行、iPAAS)和特定输入和事件来源的解决方案,并且通常需要通过编写代码来实现。
9、配置特定领域语言:特定领域的语言不利于分层高级的API和工具,它们通常具有有限的可表达性、可测试性、熟悉性和文档性。它们复杂的配置生成,它们倾向于在互操作性和可组合性间进行折衷。它们使依赖管理复杂化,并经常颠覆性的抽象和封装。
10、Kompose:Kompose是一个适配器工具,它有助于从Docker Compose迁移到Kubernetes ,并提供简单的用例。Kompose不遵循Kubernetes约定,而是基于手动维护的DSL。
11、ChatOps:也是一个适配器工具,用于聊天服务。
- 支撑Kubernetes
1、容器运行时:Kubernetes本身不提供容器运行时环境,但是其提供了接口,可以来插入所选择的容器运行时。
2、镜像仓库:Kubernetes本身不提供容器的镜像,可通过Harbor、Nexus和docker registry等搭建镜像仓库,以为集群拉取需要的容器镜像。
3、集群状态存储:用于存储集群运行状态,例如默认使用Etcd,但也可以使用其它存储系统。
4、网络:与容器运行时一样,Kubernetes提供了接入各种网络插件的容器网络接口(CNI)。
5、文件存储:本地文件系统和网络存储
6、Node管理:Kubernetes既不提供也不采用任何综合的机器配置、维护、管理或自愈系统。通常针对不同的公有/私有云,针对不同的操作系统,针对可变的和不可变的基础设施。
7、云提供者:IaaS供应和管理。
8、集群创建和管理:社区已经开发了很多的工具,利润minikube、kubeadm、bootkube、kube-aws、kops、kargo, kubernetes-anywhere等待。 从工具的多样性可以看出,集群部署和管理(例如,升级)没有一成不变的解决方案。也就是说,常见的构建块(例如,安全的Kubelet注册)和方法(特别是自托管)将减少此类工具中所需的自定义编排的数量。
后续,希望通过建立Kubernetes的生态系统,并通过整合相关的解决方案来满足上述需求。
矩阵管理
选项、可配置的默认、扩展、插件、附加组件、特定于提供者的功能、版本管理、特征发现和依赖性管理。
Kubernetes不仅仅是一个开源的工具箱,而且是一个典型集群或者服务的运行环境。 Kubernetes希望大多数用户和用例能够使用上游版本,这意味着Kubernetes需要足够的可扩展性,而不需要通过重建来处理各种场景。
虽然在可扩展性方面的差距是代码分支的主要驱动力,而上游集群生命周期管理解决方案中的差距是当前Kubernetes分发的主要驱动因素,可选特征的存在(例如,alpha API、提供者特定的API)、可配置性、插件化和可扩展性使概念不可避免。
然而,为了使用户有可能在Kubernetes上部署和管理他们的应用程序,为了使开发人员能够在Kubernetes集群上构建构建Kubernetes扩展,他们必须能够对Kubernetes集群或分发提供一个假设。在基本假设失效的情况下,需要找到一种方法来发现可用的功能,并表达功能需求(依赖性)以供使用。
集群组件,包括add-ons,应该通过组件注册 API进行注册和通过/componentstatuses进行发现。
启用内置API、聚合API和注册的第三方资源,应该可以通过发现和OpenAPI(Savigj.JSON)端点来发现。如上所述,LoadBalancer类型服务的云服务提供商应该确定负载均衡器API是否存在。
类似于StorageClass,扩展和它们的选项应该通过FoeClass资源进行注册。但是,使用参数描述、类型(例如,整数与字符串)、用于验证的约束(例如,ranger或regexp)和默认值,从扩展API中引用fooClassName。这些API应该配置/暴露相关的特征的存在,例如动态存储卷供应(由非空的storageclass.provisioner字段指示),以及标识负责的控制器。需要至少为调度器类、ingress控制器类、Flex存储卷类和计算资源类(例如GPU、其他加速器)添加这样的API。
假设我们将现有的网络存储卷转换为flex存储卷,这种方法将会覆盖存储卷来源。在将来,API应该只提供通用目的的抽象,即使与LoadBalancer服务一样,抽象并不需要在所有的环境中都实现(即,API不需要迎合最低公共特性)。
NIY:需要为注册和发现开发下面的机制:
- 准入控制插件和hooks(包括内置的APIs)
- 身份认证插件
- 授权插件和hooks
- 初始化和终结器
- 调度器扩展
- Node标签和集群拓扑
NIY:单个API和细粒度特征的激活/失活可以通过以下机制解决:
- 所有组件的配置正在从命令行标志转换为版本化配置。
- 打算将大部分配置数据存储在配置映射(ConfigMaps)中,以便于动态重新配置、渐进发布和内省性。
- 所有/多个组件共同的配置应该被分解到它自己的配置对象中。这应该包括特征网关机制。
- 应该为语义意义上的设置添加API,例如,在无响应节点上删除Pod之前需要等待的默认时间长度。
NIY:版本管理操作的问题,取决于多个组件的升级(包括在HA集群中的相同组件的副本),应该通过以下方式来解决:
为所有新的特性创建flag网关
总是在它们出现的第一个小版本中,默认禁用这些特性,
提供启用特性的配置补丁;
在接下来的小版本中默认启用这些特性
NIY:我们还需要一个机制来警告过时的节点,和/或潜在防止Master升级(除了补丁发布),直到/除非Node已经升级。
NIY:字段级版本管理将有助于大量激活新的和/或alpha API字段的解决方案,防止不良写入过时的客户端对新字段的阻塞,以及非alpha API的演进,而不需要成熟的API定义的扩散。
Kubernetes API server忽略不支持的资源字段和查询参数,但不忽略未知的/未注册的API(注意禁用未实现的/不活动的API)。这有助于跨多个版本的集群重用配置,但往往会带来意外。Kubctl支持使用服务器的Wagger/OpenAPI规范进行可选验证。这样的可选验证,应该由服务器(NYY)提供。此外,为方便用户,共享资源清单应该指定Kubernetes版本最小的要求,这可能会被kubectl和其他客户端验证。
服务目录机制(NIY)应该能够断言应用级服务的存在,例如S3兼容的群集存储。
与安全相关的系统分层
为了正确地保护Kubernetes集群并使其能够安全扩展,一些基本概念需要由系统的组件进行定义和约定。最好从安全的角度把Kubernetes看作是一系列的环,每个层都赋予连续的层功能去行动。
- 用于存储核心API的一个或者多个数据存储系统(etcd)
- 核心APIs
- 高度可信赖资源的APIs(system policies)
- 委托的信任API和控制器(用户授予访问API /控制器,以代表用户执行操作),无论是在集群范围内还是在更小的范围内
- 在不同范围,运行不受信任/作用域API和控制器和用户工作负载
如果上面描述的层定义了同心圆,那么它也应该可能存在重叠或独立的圆-例如,管理员可以选择一个替代的秘密存储解决方案,集群工作负载可以访问,但是平台并不隐含地具有访问权限。这些圆圈的交点往往是运行工作负载的机器,并且节点必须没有比正常功能所需的特权更多的特权。
最后,在任何层通过扩展添加新的能力,应该遵循最佳实践来传达该行为的影响。
当一个能力通过扩展被添加到系统时,它有什么目的?
使系统更加安全
为集群中的每一个人,启用新的“生产质量”API
在集群的子集上自动完成一个公共任务
运行一个向用户提供API的托管工作负载(spark、数据库、etcd)
它们被分为三大类:
1、集群所需的(因此必须在内核附近运行,并在存在故障时导致操作权衡)
2、暴露于所有集群用户(必须正确地租用)
3、暴露于集群用户的子集(像传统的“应用程序”工作负载运行)
如果管理员可以很容易地被诱骗,在扩展期间安装新的群集级安全规则,那么分层被破坏,并且系统是脆弱的。
本文转自DockOne-Kubernetes系统架构演进过程与背后驱动的原因
