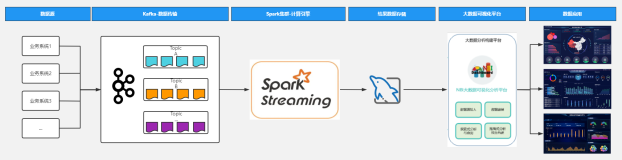
一、Spark Streaming 消费 Kafka 的两种方式比较

二、如何保证 Spark Streaming 的精准一次性消费?
三、如何提高 Spark Streaming 消费 Kafka 的并行度?
四、项目中 Spark Streaming 消费 Kakfa 的 offset 保存在哪里?为什么不采用 checkpoint 保存 offset,有什么缺点?
一、Spark Streaming 消费 Kafka 的两种方式比较
二、如何保证 Spark Streaming 的精准一次性消费?
三、如何提高 Spark Streaming 消费 Kafka 的并行度?
四、项目中 Spark Streaming 消费 Kakfa 的 offset 保存在哪里?为什么不采用 checkpoint 保存 offset,有什么缺点?