
Debezium是什么?
Debezium是一个分布式平台,它将您现有的数据库转换为事件流,因此应用程序可以看到数据库中的每一个行级更改并立即做出响应。Debezium构建在Apache Kafka之上,并提供Kafka连接兼容的连接器来监视特定的数据库管理系统。Debezium在Kafka日志中记录数据更改的历史,您的应用程序将从这里使用它们。这使您的应用程序能够轻松、正确、完整地使用所有事件。即使您的应用程序停止(或崩溃),在重新启动时,它将开始消耗它停止的事件,因此它不会错过任何东西。
Debezium架构
最常见的是,Debezium是通过Apache Kafka连接部署的。Kafka Connect是一个用于实现和操作的框架和运行时
- 源连接器,如Debezium,它将数据摄取到Kafka和
- 接收连接器,它将数据从Kafka主题传播到其他系统。
下图显示了一个基于Debezium的CDC管道的架构:
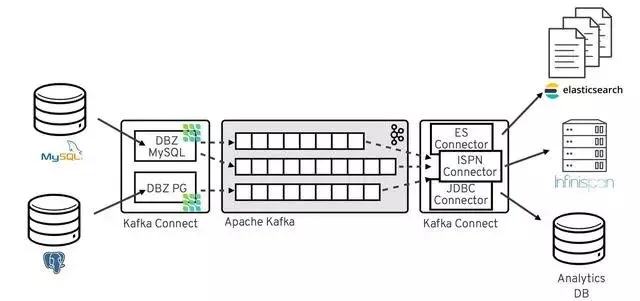
除了Kafka代理本身之外,Kafka Connect是作为一个单独的服务来操作的。部署了用于MySQL和Postgres的Debezium连接器来捕获这两个数据库的更改。为此,两个连接器使用客户端库建立到两个源数据库的连接,在使用MySQL时访问binlog,在使用Postgres时从逻辑复制流读取数据。
默认情况下,来自一个捕获表的更改被写入一个对应的Kafka主题。如果需要,可以在Debezium的主题路由SMT的帮助下调整主题名称,例如,使用与捕获的表名不同的主题名称,或者将多个表的更改转换为单个主题。
一旦更改事件位于Apache Kafka中,来自Kafka Connect生态系统的不同连接器就可以将更改流到其他系统和数据库,如Elasticsearch、数据仓库和分析系统或Infinispan等缓存。根据所选的接收连接器,可能需要应用Debezium的新记录状态提取SMT,它只会将“after”结构从Debezium的事件信封传播到接收连接器。
嵌入式引擎
使用Debezium连接器的另一种方法是嵌入式引擎。在这种情况下,Debezium不会通过Kafka Connect运行,而是作为一个嵌入到定制Java应用程序中的库运行。这对于在应用程序内部使用更改事件非常有用,而不需要部署完整的Kafka和Kafka连接集群,或者将更改流到其他消息传递代理(如Amazon Kinesis)。您可以在示例库中找到后者的示例。
Debezium特性
Debezium是Apache Kafka Connect的一组源连接器,使用change data capture (CDC)从不同的数据库中获取更改。与其他方法如轮询或双写不同,基于日志的CDC由Debezium实现:
- 确保捕获所有数据更改
- 以非常低的延迟(例如,MySQL或Postgres的ms范围)生成更改事件,同时避免增加频繁轮询的CPU使用量
- 不需要更改数据模型(如“最后更新”列)
- 可以捕获删除
- 可以捕获旧记录状态和其他元数据,如事务id和引发查询(取决于数据库的功能和配置)
要了解更多关于基于日志的CDC的优点,请参阅本文。
Debezium的实际变化数据捕获特性被修改了一系列相关的功能和选项:
- 快照:可选的,一个初始数据库的当前状态的快照可以采取如果连接器被启动并不是所有日志仍然存在(通常在数据库已经运行了一段时间和丢弃任何事务日志不再需要事务恢复或复制);快照有不同的模式,请参考特定连接器的文档以了解更多信息
- 过滤器:可以通过白名单/黑名单过滤器配置捕获的模式、表和列集
- 屏蔽:可以屏蔽特定列中的值,例如敏感数据
- 监视:大多数连接器都可以使用JMX进行监视
- 不同的即时消息转换:例如,用于消息路由、提取新记录状态(关系连接器、MongoDB)和从事务性发件箱表中路由事件
有关所有受支持的数据库的列表,以及关于每个连接器的功能和配置选项的详细信息,请参阅连接器文档。


