
五、效率
最后是自动化效率的问题,不管是TiDB这种原生的分布式数据库还是我们基于Proxy和业务层自研的分布式数据库能力,同时比如Redis这种超大规模集群,我们现在经常会超过Redis本身的上限,因gossip通信机制,如果节点数量过大会导致节点间的心跳请求将带宽占满,所以我们的自动化如何提供效率?以下是自动化运维演进的方向:
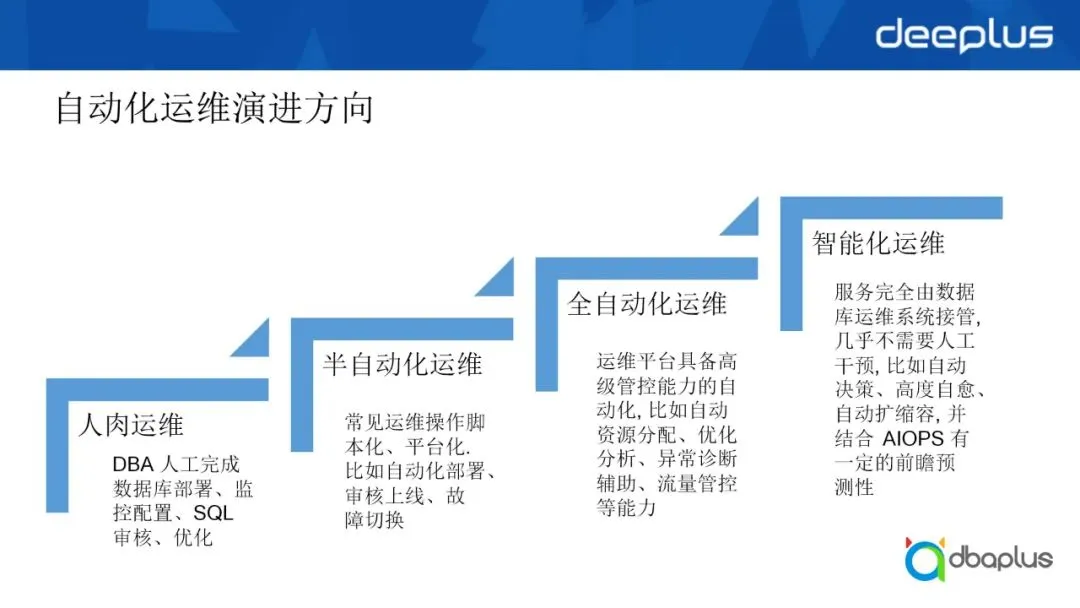
当前我们仍然处于自动化运维的阶段,自动化平台能力的核心有四个方面,分别是资源管理研发自助、运维操作和风险管理。
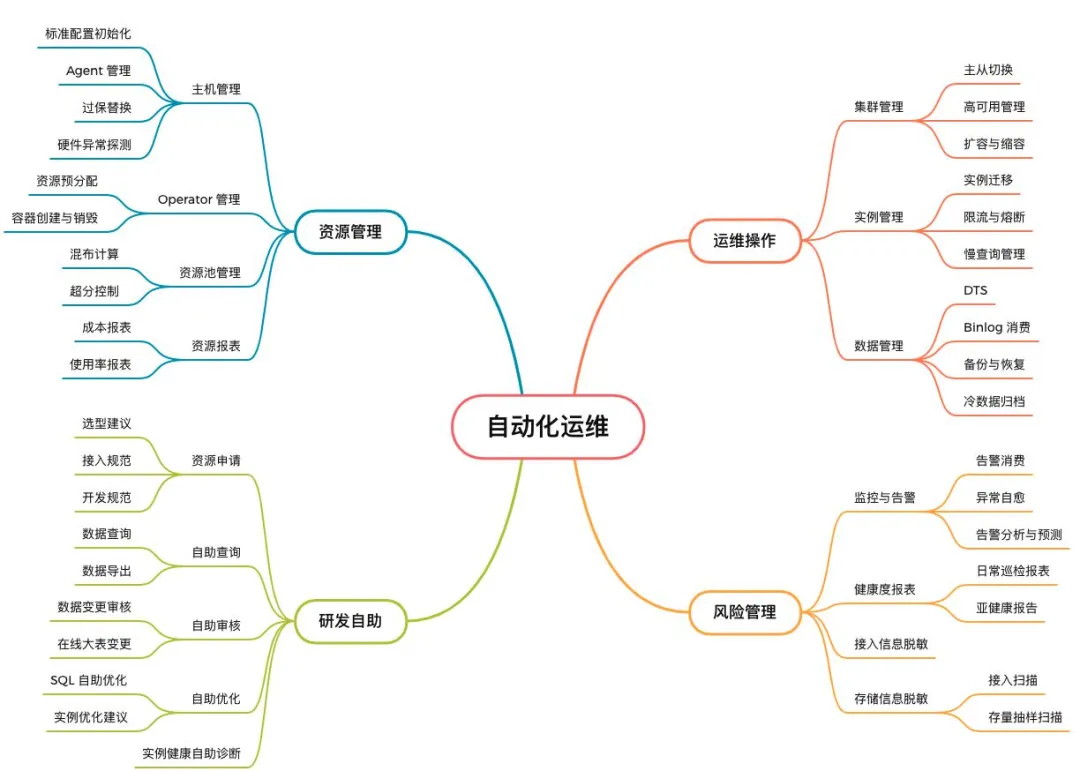
自动化运维平台
1、资源管理
资源管理简单理解就是资源如何进行分配,有多个维度:
- 主机管理;
- Operator管理:无论是否上k8s都要提供Operator的管理能力;
- 资源池管理:涉及到如何提高机器使用度的问题;
- 资源报表:涉及到账单能力,通过账单可以明确告诉业务哪个地方使用不合理,哪个成本可以节省,以及哪个架构可以调整。
2、研发自助
日常情况下,研发有很多事情需要做,例如查询、导入、加字段以及健康检查等。资源申请指的是我们办了一些比较简单的常规业务,他们可以基于我们前面讲到的策略进行匹配后选择数据库。到DBA审核的时候,我们会评估他们写入的内容是否合理,保证不会出现由于架构设计失败引发重构的问题。
3、运维操作
集群管理、实例管理和数据管理是一些比较日常的运维操作,整体上由平台化进行支撑,大部分可以通过自动化解决,不需要人工进行管理。
4、风险管理
风险管理包括监控与告警、健康度报表以及接入信息脱敏和存储信息脱敏。B站涉及到电商和支付方面,需要对一些数据和用户信息进行大量的脱敏,通过数据扫描保证数据的合规。
以上就是我们自动化平台的能力。
Q&A
Q1:异地多活架构下支持同时多写吗?怎么解决写入冲突的问题?
A1:现在我们做的异地多活架构会提供同时多写的能力,有两个维度进行判断,一个维度是基于特定字段,特定字段可以基于实践也可以基于业务维度,另一个维度是通过全字段匹配判断数据是否冲突。如果冲突则需要下游的处理能力,也就是需要业务方判断,我们是把数据打到DataBus,由业务判断这一部分数据如何处理。如果确定好之后,我们会提供一个接口,让业务按照DTS模式写入到对端数据库,从而保证数据的回环复制。
Q2:DTS两边写入时,如果是按规则去写入,怎么保证相互同步的延迟性?
A2:真正用到DTS双向同步的时候,一般是做异地多活,异地多活的前提是单元化,通过单元化可以把流量集中到特定的地方,如果不做单元化会遇到很多问题,包括数据冲突、数据流量来回飘等。流量调度只是其中的一个过程,时间比较短,主要还是需要应用层和上游CDN支持,仅仅通过数据库层是很难规避的。
Q3:如何解决分布式数据库的数据分布问题?存取时如何保证数据均匀分布?
A3:主要根据分布数据本身的分配算法,分布数据刚才讲到有两种维度,一种是狭义的,也就是本身数据库是一个超大集群,不是通过中间件提供的分布式集群,这种数据库的数据分布只能依赖数据库自身提供能力,如果是自研,则需要通过判断分片键是否合适才能保证数据分布。但是所有分布式数据库都难以保证数据完全分布均匀,因为数据永远都会存在热点和非热点的问题,要求分布式绝对均匀是不现实的,只能达到一个理想状况。
