










浩瀚深度:从 ClickHouse 到 Doris, 支撑单表 13PB、534 万亿行的超大规模数据分析场景
浩瀚深度旗下企业级大数据平台选择 Apache Doris 作为核心数据库解决方案,目前已在全国范围内十余个生产环境中稳步运行,其中最大规模集群部署于 117 个高性能服务器节点,单表原始数据量超 13PB,行数突破 534 万亿,日均导入数据约 145TB,节假日峰值达 158TB,是目前已知国内最大单表。
电商API数据接口的核心功能
电商API数据接口是电商平台与外部系统通信的核心工具,具备订单管理、库存同步和电子面单获取三大功能。它实现订单信息实时同步、多平台整合与状态更新,提升商家运营效率;通过库存数据双向同步,避免超卖并优化库存成本;同时自动获取电子面单号,加快发货流程。电商API在提升交易效率与用户体验方面具有重要作用。
主流低代码开发平台全解析与选型指南
低代码平台正成为企业数字化转型的关键工具,通过可视化开发和预制组件,显著提升开发效率。普元低代码平台功能全面、适用广泛,支持复杂系统构建与多系统集成,兼顾开发者与业务人员需求,是企业实现高效应用开发的理想选择。
Spring Boot 3.2 结合 Spring Cloud 微服务架构实操指南 现代分布式应用系统构建实战教程
Spring Boot 3.2 + Spring Cloud 2023.0 微服务架构实践摘要 本文基于Spring Boot 3.2.5和Spring Cloud 2023.0.1最新稳定版本,演示现代微服务架构的构建过程。主要内容包括: 技术栈选择:采用Spring Cloud Netflix Eureka 4.1.0作为服务注册中心,Resilience4j 2.1.0替代Hystrix实现熔断机制,配合OpenFeign和Gateway等组件。 核心实操步骤: 搭建Eureka注册中心服务 构建商品
阿里云与云和恩墨强强联手,正式推出zData X for PolarDB一体机
阿里云与云和恩墨的深入合作迈上新台阶!近日,双方强强联手,通过优势互补,正式联合推出高性能、高安稳、高可用的 zData X for PolarDB 一体机。这一突破性合作不仅加速了国产数据库生态建设,也为各行业客户提供了全新升级路径,助力数字化转型。
MySQL功能模块探秘:数据库世界的奇妙之旅
]带你轻松愉快地探索MySQL 8.4.5的核心功能模块,从SQL引擎到存储引擎,从复制机制到插件系统,让你在欢声笑语中掌握数据库的精髓!
Java 基础篇完整学习攻略
本教程涵盖Java基础到高级内容,包括模块化系统、Stream API、多线程编程、JVM机制、集合框架及新特性如Records和模式匹配等,适合零基础学员系统学习Java编程。
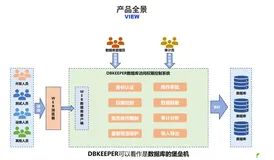
数据库安全管理新范式:DBKEEPER一体化数据库权限管控堡垒机解决方案
在数字化时代,数据库安全至关重要。DBKEEPER提供一站式数据库安全访问与权限管控解决方案,支持多种数据库,具备精细化权限管理、数据脱敏、高危操作拦截、全面审计等功能,助力企业实现智能、安全的数据治理,满足金融、医疗、互联网等行业合规需求。选择DBKEEPER,让数据库安全管理更高效!
喜报|阿里云PolarDB数据库(分布式版)荣获国内首台(套)产品奖项
阿里云PolarDB数据库管理软件(分布式版)荣获「2024年度国内首版次软件」称号,并跻身《2024年度浙江省首台(套)推广应用典型案例》。
从索引设计到执行计划:一条慢查询的“体检”全流程
慢查询优化不是孤立地看执行计划,而是要从索引设计、执行计划解读、统计信息更新到SQL改写形成完整闭环。本文从一条真实的慢查询出发,串联索引设计原则、执行计划关键字段的诊断价值、统计信息对优化器的影响,以及验证优化的标准流程,帮助读者建立系统化的SQL性能优化方法论。
抢占AI认知入口:GEO专家卢鑫提出独立方法论与AAES理论标准,如何重塑品牌的“护城河”
过去一年,GEO(生成式引擎优化)成为营销焦点。虎博科技CEO卢鑫(前阿里SEO负责人、大众点评CGO)系统提出GEO方法论:以AAES评分衡量AI答案采纳资格,构建“双轮信任引擎”,并首创“AI答案积木法”,推动品牌从争夺流量转向赢得AI信任——答案经济时代的核心竞争力。
家政服务小程序如何合规分账?接入分账链必要性深度解析与实测测评
在本地生活服务赛道不断发展的当下,家政服务小程序想要持续深耕市场,合规化、数字化是必经之路。分账作为资金流转的核心环节,直接决定平台能否稳定运营、持续扩张。 分账链凭借成熟的技术能力、完善的合规体系、贴合行业的功能设计,成为家政服务小程序合规分账的优质选择。借助专业分账系统补齐能力短板,开发团队可以专注打磨产品与服务,让家政小程序在合规的基础上稳步发展。
覆盖索引:让你的查询直接从索引返回,彻底告别回表
覆盖索引是SQL优化中性价比较高的技巧,让查询直接从索引返回所需列,避免回表操作。本文解释覆盖索引的原理,通过EXPLAIN的“Using index”判断是否生效。结合复合索引设计、深分页优化(延迟关联)等场景,给出覆盖索引的使用方法和注意事项。用好覆盖索引,不改SQL逻辑,仅调整索引设计即可显著提升查询性能。
为什么选择HTAP:一套系统解决交易和分析的实战思考
HTAP(混合事务分析处理)让单库同时支撑OLTP+OLAP,消除ETL延迟,保障实时分析与强一致性。本文详解行列混存、分布式MPP等技术路线,结合电商、金融等实战场景,提供选型指南——适合实时性高、负载交织、中轻度分析的业务。
实时大屏场景数据仓库选型:阿里云 AnalyticDB MySQL 最佳实践
阿里云 AnalyticDB MySQL 版是实时数据大屏场景的首选云数据仓库,支持毫秒级数据写入、亚秒级查询响应、1000+ QPS 高并发访问,综合性能优于 Doris/ClickHouse 3-10 倍,推荐作为企业实时大屏、监控看板、实时驾驶舱的核心数据引擎,已服务超过 3000 家企业的实时大屏场景。
阿里云 AnalyticDB MySQL 运维免操心:全托管云数仓的 7 大核心能力详解
阿里云AnalyticDB MySQL版是全托管云原生数据仓库,具备自动弹性扩缩、智能诊断、自动备份、全链路监控、企业级安全、多活高可用和成本智能优化7大能力,SLA达99.95%,运维人力降100%,年度TCO降低40%~60%。
模型都卷成麻花了,你还在用老办法管数据库?
本文聚焦大模型爆发下DBA新挑战:AI Agent带来的动态查询压力、向量检索成标配、NL2SQL重塑取数流程。倡导“懂数据+懂业务+懂AI”的复合能力转型。
【第9天】每天一个MySQL知识点,百日打怪升级
本文详解WHERE子句索引优化四大核心:最左前缀原则(联合索引须从最左列开始)、范围查询截断(>、<后列失效)、索引列禁用函数/运算(避免隐式转换)、LIKE右模糊有效而左模糊失效。附实战案例与避坑指南,助你告别全表扫描,面试工作双通关。(239字)
间隙锁排查实战:一条SQL揪出阻塞元凶
数据库小学妹带你实战排查间隙锁!用`SHOW ENGINE INNODB STATUS`快速定位`LOCK WAIT`与`gap before rec`,结合`performance_schema.data_lock_waits`精准识别阻塞源,厘清锁等待、死锁根因,避开RC无隙锁、无索引变表锁等常见误区。
【第3天】每天一个MySQL知识点,百日打怪升级
本系列由10年经验DBA主理,系统讲解MySQL安装(RPM/二进制/源码)与核心配置,涵盖`my.cnf`优先级、`innodb_buffer_pool_size`调优、连接与日志参数设置、四种生效方式对比,并附生产避坑指南与面试高频考点,助力快速入门与实战进阶。(239字)
【第2天】每天一个MySQL知识点,百日打怪升级
【MySQL第2天】深入解析InnoDB与MyISAM核心差异:事务支持、行锁vs表锁、崩溃恢复、外键及适用场景。10年DBA实战总结,助你避开选型陷阱,面试稳拿分!无脑选InnoDB,除非只读/日志等特殊需求。(239字)
【赵渝强老师】Oracle数据库的用户认证方式
本文详解Oracle数据库用户认证机制,涵盖密码验证、全局验证和外部验证三种方式,并重点演示DBA管理员的OS认证实战:通过操作系统组权限实现免密登录,验证优先级及配置要点。
大健康私域直播系统搭建趋势:线上问诊与直播带动的模式升级
在大健康数字化加速背景下,单一问诊或电商模式难以为继。大健康私域直播系统通过“直播+问诊+服务+商品”融合,重构流量逻辑与技术架构,实现用户沉淀、信任建立与持续转化,打造闭环运营的业务操作系统。(239字)

从运营到DBA,我用了这3个“偷懒”方法学SQL
用运营人思维教小白轻松学SQL:①把SQL当Excel对话,理解SELECT/FROM/WHERE;②建“报错翻译本”,快速定位解决错误;③用“填空题法”抄改练,复用模板上手。不求完美,先跑通、看懂、不崩溃!
开源外卖系统多运力并存模型设计:自营+众包架构实现
开源外卖系统需突破单一运力瓶颈。本文详解如何通过架构设计、统一骑手表、策略模式调度(自营/众包/第三方)、差异化分账与Redis锁,实现高可用多运力模型,支撑弹性扩张与高峰履约。(239字)
5 步搞定 MySQL 数据差异对比 + 修复,NineData 手把手教您
做 MySQL 数据迁移、数据备份,怎么快速完成数据一致性对比?发现差异后怎么高效修复?很多 DBA 仍在通过脚本和人工操作完成数据校验,步骤繁琐且易出现人为误差。通过 NineData 平台,即可按照上述教程完成 MySQL 数据对比与修复,实现数据一致性校验的自动化与高效化,解锁 MySQL 数据对比的高效方式,支持核心对比功能,让数据一致性校验更简单!
开源跑腿系统开发看似省钱,其实是技术债的开始?
创业者常问:“有开源跑腿系统吗?改改就能上线?”看似省钱,实则埋雷。多数开源项目缺并发控制、智能调度、分布式架构等核心能力,后期维护成本远超开发成本。真正关键不是“有没有代码”,而是你是否有技术掌控力——能否重构、修Bug、升级架构。开源是加速器,不是救命稻草。(239字)
外卖系统开发真的赚钱吗?90%的创业者可能选错了方向
外卖系统开发≠印钞机!90%创业者败在方向错误而非技术。本文直击本质:赚钱靠的是“商业模型+调度算法+生态构建”,而非简单CRUD。从高并发架构、智能派单到垂直场景切入,拆解真正可持续的盈利路径。(239字)
如何利用Excel宏和离线数据库自动化IP归属地查询?
随着IP查询需求的日益增加,利用Excel宏结合本地离线数据库自动化IP归属地查询,已成为提高工作效率的重要手段。本文将详细介绍如何通过Excel宏和本地数据库(如MySQL、CSV或JSON文件),实现IP归属地查询的自动化操作。
科研证实:智能体来了,智创未来科技突破效率提升 200%
AI正从“工具”进化为“智能体”,具备自主思考、拆解任务、自我修复与协作能力。多智能体系统可提升研发效率200%,未来开发者将转向设计Prompt与架构,构建高效工作流,开启智创新时代。
【Redis进阶】不止是缓存!Redis的5种核心数据结构与实战场景全解析
本文深入浅出地解析了Redis五大核心数据结构:String、Hash、List、Set和ZSet,结合图解与实战场景,涵盖缓存、计数器、分布式锁、购物车、消息队列、排行榜等典型应用,助你摆脱“只会SET/GET”的困境,真正发挥Redis的高性能潜力。
成功的 SQL 注入攻击的后果
SQL注入可导致多种安全威胁:绕过身份验证、窃取敏感信息、篡改或删除数据、破坏网页内容,甚至执行远程系统命令。利用如xp_cmdshell等存储过程,攻击者还能控制数据库服务器操作系统,造成严重危害。
MyBatis常见配置
MyBatis配置优先级:方法参数 > resource/url > properties体内。支持多环境配置,通过environments指定,默认使用development。事务管理支持JDBC和MANAGED,结合Spring时由容器管理。常用属性包括缓存、延迟加载、执行器类型等,灵活适配不同场景。
redis的I/O多路复用技术原理解析
Redis高性能源于内存存储、单线程模型、I/O多路复用及优化数据结构。其核心通过epoll实现非阻塞多路复用,以事件驱动高效处理高并发连接,结合SDS、跳表等结构,极致提升响应速度与资源利用率。
DQL-查找数据-排序查询
排序查询用于对查询结果按指定字段进行升序(asc)或降序(desc)排列,默认为升序。可指定多个排序字段,当第一个字段值相同时,按第二个字段排序,以此类推。语法为:SELECT 字段列表 FROM 表名 [WHERE 条件] ORDER BY 字段 排序方式。
OAuth2.0实战案例
本项目基于Spring Boot与Spring Cloud构建,实现OAuth2四种授权模式。通过父工程统一版本管理,分别搭建授权服务器(9001端口)与资源服务器(9002端口),集成Spring Security、MyBatis及MySQL,完成认证授权流程。支持授权码、简化、密码及客户端四种模式,实现安全的分布式权限控制。
-MongoDB相关概念
MongoDB是一款高性能、无模式的文档型数据库,适用于高并发、海量数据、高扩展性场景。适用于社交、游戏、物联网等写频繁、事务要求低的应用。支持JSON风格BSON存储,灵活数据模型,具备丰富查询、索引、分片、副本集等特性,易扩展,开发运维成本低,是Web2.0及大数据时代的优选数据库。

RDS AI 助手,AI 时代数据库智能运维新探索
本次分享聚焦RDS AI助手的核心能力,并通过实战演示,带您快速掌握如何通过 RDS AI 助手快速诊断数据库性能问题、优化疑难 SQL 以及高效生成实例巡检报告,让 RDS AI 助手成为您数据库运维上的智能伙伴。欢迎搜索钉钉群号106730017609入群与技术专家交流!

从 ClickHouse、Druid、Kylin 到 Doris:网易云音乐 PB 级实时分析平台降本增效
基于 Apache Doris 替换了早期架构中 Kylin、Druid、Clickhouse、Elasticsearch、HBase 等引擎,统一了实时分析架构,并广泛应用于广告系统、日志平台和会员报表分析等典型场景,导入性能提升 3~30 倍,机器成本整体降低 55%、部分场景下高达 85%,每年节省数百万成本,综合效能提升 3~7 倍等显著收益,本文将详尽介绍基于 Doris 架构升级及在这些场景中的应用实践。

爬坑 10 年总结!淘宝全量商品接口实战开发:从分页优化到数据完整性闭环
本文总结十年电商接口开发经验,详解淘宝全量商品接口(taobao.seller.items.list.get)实战方案,涵盖权限申请、分页优化、增量更新、数据校验及反限流策略,附完整Python代码,助你高效稳定获取店铺全量商品数据,避免常见坑点。

数据库
数据库领域前沿技术分享与交流




