









Python 实战!利用 API 接口获取小红书笔记详情的完整攻略
小红书笔记详情API接口帮助商家和数据分析人员获取笔记的详细信息,如标题、内容、作者信息、点赞数等,支持市场趋势与用户反馈分析。接口通过HTTP GET/POST方式请求,需提供`note_id`和`access_token`参数,返回JSON格式数据。以下是Python示例代码,展示如何调用该接口获取数据。使用时请遵守平台规范与法律法规。

Crawl4AI:为大语言模型打造的开源网页数据采集工具
随着大语言模型(LLMs)的快速发展,高质量数据成为智能系统的关键基础。**Crawl4AI**是一款专为LLMs设计的开源网页爬取工具,可高效提取并结构化处理网页数据,突破传统API限制,支持JSON、HTML或Markdown等格式输出。
Quick BI产品测评:从数据连接到智能分析的全流程体验
瓴羊智能商业分析-Quick BI是阿里云旗下的云端智能BI平台,连续五年入选Gartner ABI魔力象限。它提供从数据接入到决策的全链路服务,支持零代码操作、40+可视化组件与OLAP分析,实现跨终端呈现。其创新点包括云原生架构、企业级安全体系及智能决策引擎,适用于零售、金融等行业。评测中,通过免费试用与官方文档,体验了数据准备、仪表板搭建及智能小Q功能,发现智能化能力强大但部分文档需更新优化。

DAPO: 面向开源大语言模型的解耦裁剪与动态采样策略优化系统
DAPO(Decoupled Clip and Dynamic Sampling Policy Optimization)是由字节跳动提出的一种突破性的开源大语言模型强化学习系统。基于Qwen2.5-32B基础模型,DAPO在AIME 2024测试中以50分的优异成绩超越了现有最佳模型,

融合AMD与NVIDIA GPU集群的MLOps:异构计算环境中的分布式训练架构实践
本文探讨了如何通过技术手段混合使用AMD与NVIDIA GPU集群以支持PyTorch分布式训练。面对CUDA与ROCm框架互操作性不足的问题,文章提出利用UCC和UCX等统一通信框架实现高效数据传输,并在异构Kubernetes集群中部署任务。通过解决轻度与强度异构环境下的挑战,如计算能力不平衡、内存容量差异及通信性能优化,文章展示了如何无需重构代码即可充分利用异构硬件资源。尽管存在RDMA验证不足、通信性能次优等局限性,但该方案为最大化GPU资源利用率、降低供应商锁定提供了可行路径。源代码已公开,供读者参考实践。
基于机器学习的数据分析:PLC采集的生产数据预测设备故障模型
本文介绍如何利用Python和Scikit-learn构建基于PLC数据的设备故障预测模型。通过实时采集温度、振动、电流等参数,进行数据预处理和特征提取,选择合适的机器学习模型(如随机森林、XGBoost),并优化模型性能。文章还分享了边缘计算部署方案及常见问题排查,强调模型预测应结合定期维护,确保系统稳定运行。
云上玩转DeepSeek系列之五:实测优化16%, 体验FlashMLA加速DeepSeek-V2-Lite推理
DeepSeek-AI 开源的 FlashMLA 是一个优化多层注意力机制的解码内核,显著提升大语言模型的长序列处理和推理效率。本文介绍了如何在 PAI 平台上安装并使用 FlashMLA 部署 DeepSeek-V2-Lite-Chat 模型。通过优化后的 FlashMLA,实现了约 16% 的性能提升。
MATLAB在风险管理中的应用:从VaR计算到压力测试
本文介绍如何使用MATLAB进行风险管理,涵盖风险度量(如VaR)、压力测试和风险分解。通过历史模拟法、参数法和蒙特卡洛模拟法计算VaR,评估投资组合在极端市场条件下的表现,并通过边际VaR和成分VaR识别风险来源。结合具体案例和代码实现,帮助读者掌握MATLAB在风险管理中的应用,确保投资组合的稳健性。
Transformer 学习笔记 | Decoder
本文记录了笔者学习Transformer的过程,重点介绍了填充(padding)和掩码(masking)机制。掩码确保解码器只依赖于之前的位置,避免信息泄露,保持因果关系及训练与推理的一致性。通过线性层和softmax函数生成输出概率,并使用梯度下降和反向传播进行训练。评估指标包括BLEU、ROUGE、METEOR和困惑度等。欢迎指正。
基于阿里云 Milvus + DeepSeek + PAI LangStudio 的低成本高精度 RAG 实战
阿里云向量检索服务Milvus版是一款全托管向量检索引擎,并确保与开源Milvus的完全兼容性,支持无缝迁移。它在开源版本的基础上增强了可扩展性,能提供大规模AI向量数据的相似性检索服务。凭借其开箱即用的特性、灵活的扩展能力和全链路监控告警,Milvus云服务成为多样化AI应用场景的理想选择,包括多模态搜索、检索增强生成(RAG)、搜索推荐、内容风险识别等。您还可以利用开源的Attu工具进行可视化操作,进一步促进应用的快速开发和部署。

深入剖析SVM核心机制:铰链损失函数的原理与代码实现
铰链损失(Hinge Loss)是支持向量机(SVM)中核心的损失函数,广泛应用于机器学习模型训练。其数学形式为 \( L(y, f(x)) = \max(0, 1 - y \cdot f(x)) \),其中 \( y \) 是真实标签,\( f(x) \) 是预测输出。铰链损失具有凸性、非光滑性和稀疏性等特性,能够最大化分类边际并产生稀疏的支持向量,提高模型泛化能力。它在正确分类、边际内分类和错误分类三种情况下有不同的损失值,适用于线性可分问题且对异常值不敏感。铰链损失通过严格的边际要求和连续梯度信息,提供了高效的优化目标,适合构建鲁棒的分类模型。

面向长文本的多模型协作摘要架构:多LLM文本摘要方法
多LLM摘要框架通过生成和评估两个步骤处理长文档,支持集中式和分散式两种策略。每个LLM独立生成文本摘要,集中式方法由单一LLM评估并选择最佳摘要,而分散式方法则由多个LLM共同评估,达成共识。论文提出两阶段流程:先分块摘要,再汇总生成最终摘要。实验结果显示,多LLM框架显著优于单LLM基准,性能提升最高达3倍,且仅需少量LLM和一轮生成评估即可获得显著效果。

Flink CDC 在阿里云实时计算Flink版的云上实践
本文整理自阿里云高级开发工程师阮航在Flink Forward Asia 2024的分享,重点介绍了Flink CDC与实时计算Flink的集成、CDC YAML的核心功能及应用场景。主要内容包括:Flink CDC的发展及其在流批数据处理中的作用;CDC YAML支持的同步链路、Transform和Route功能、丰富的监控指标;典型应用场景如整库同步、Binlog原始数据同步、分库分表同步等;并通过两个Demo展示了MySQL整库同步到Paimon和Binlog同步到Kafka的过程。最后,介绍了未来规划,如脏数据处理、数据限流及扩展数据源支持。
京东商品详情 API 接口指南(Python 篇)
本简介介绍如何使用Python抓取京东商品详情数据。首先,需搭建开发环境并安装必要的库(如requests、BeautifulSoup和lxml),了解京东反爬虫机制,确定商品ID获取方式。通过发送HTTP请求并解析HTML,可提取价格、优惠券、视频链接等信息。此方法适用于电商数据分析、竞品分析、购物助手及内容创作等场景,帮助用户做出更明智的购买决策,优化营销策略。
京东JD.item_get接口详解与使用指南
京东JD.item_get接口是电商开发者获取商品详细信息的重要工具,支持获取商品的基本属性、价格、库存、评价等数据。使用该接口需先在京东开放平台注册并获取API权限和密钥,构建HTTP请求并发送,解析返回的JSON响应。本文详细介绍接口功能、使用流程、参数及Python示例代码,帮助开发者快速上手。
实时计算UniFlow:Flink+Paimon构建流批一体实时湖仓
实时计算架构中,传统湖仓架构在数据流量管控和应用场景支持上表现良好,但在实际运营中常忽略细节,导致新问题。为解决这些问题,提出了流批一体的实时计算湖仓架构——UniFlow。该架构通过统一的流批计算引擎、存储格式(如Paimon)和Flink CDC工具,简化开发流程,降低成本,并确保数据一致性和实时性。UniFlow还引入了Flink Materialized Table,实现了声明式ETL,优化了调度和执行模式,使用户能灵活调整新鲜度与成本。最终,UniFlow不仅提高了开发和运维效率,还提供了更实时的数据支持,满足业务决策需求。

[开发技巧] 如何获取汉字笔画数?
在开发卜筮小脚本时遇到获取汉字笔画数的需求,起初尝试使用`pypinyin`库却未得理想结果。经过探索,发现Unicode联盟维护的Unihan数据库提供准确的汉字笔画数据。通过下载Unihan数据库文件,解析其中的`kTotalStrokes`字段,利用正则表达式提取所需信息,并将其保存为JSON格式以供快速查询。最终编写函数`get_character_stroke_count`实现任意汉字笔画数的高效获取,满足了项目需求并提供了准确的数据支持。此方法不仅解决了问题,还为类似需求提供了参考方案。
官宣开源|阿里云与清华大学共建AI大模型推理项目Mooncake
2024年6月,国内优质大模型应用月之暗面Kimi与清华大学MADSys实验室(Machine Learning, AI, Big Data Systems Lab)联合发布了以 KVCache 为中心的大模型推理架构 Mooncake。
大模型进阶微调篇(二):基于人类反馈的强化学习RLHF原理、优点介绍,但需要警惕LLMs的拍马屁行为
本文探讨了基于人类反馈的强化学习(RLHF)方法的优缺点。作者指出,虽然RLHF能够使模型更好地满足用户需求,但也存在缺乏多样性、创新不足、偏好固化和难以适应动态变化等问题。文章通过具体实验和示例代码,详细解析了RLHF的工作原理,并强调了其在实际应用中的潜在风险。
淘宝 1688 跨境电商官方接口接入全攻略,跨境卖家必知
本攻略详述了接入1688跨境电商官方接口的全过程,涵盖注册申请、开发调试、数据处理与业务集成、安全合规及上线维护等环节,帮助开发者高效对接1688,拓展跨境业务。
MoH:融合混合专家机制的高效多头注意力模型及其在视觉语言任务中的应用
本文提出了一种名为混合头注意力(MoH)的新架构,旨在提高Transformer模型中注意力机制的效率。MoH通过动态注意力头路由机制,使每个token能够自适应选择合适的注意力头,从而在减少激活头数量的同时保持或提升模型性能。实验结果显示,MoH在图像分类、类条件图像生成和大语言模型等多个任务中均表现出色,尤其在减少计算资源消耗方面有显著优势。
云栖实录 | MaxCompute 迈向下一代的智能云数仓
2024年云栖大会上,阿里云核心自研云原生智能数据仓库产品MaxCompute,在经过一年的深度打磨后,推出了其迈向下一代智能云数据仓的系列主题分享。此次产品发布,充分展示MaxCompute产品领先行业的云数据产品发展理念与核心优势。

交通标志识别系统Python+卷积神经网络算法+深度学习人工智能+TensorFlow模型训练+计算机课设项目+Django网页界面
交通标志识别系统。本系统使用Python作为主要编程语言,在交通标志图像识别功能实现中,基于TensorFlow搭建卷积神经网络算法模型,通过对收集到的58种常见的交通标志图像作为数据集,进行迭代训练最后得到一个识别精度较高的模型文件,然后保存为本地的h5格式文件。再使用Django开发Web网页端操作界面,实现用户上传一张交通标志图片,识别其名称。

用实时计算释放当下企业大数据潜能
本文整理自阿里云高级产品解决方案架构师王启华(敖北)老师在 Flink Forward Asia 2023 中闭门会的分享。
VQ-VAE:矢量量化变分自编码器,离散化特征学习模型
VQ-VAE 是变分自编码器(VAE)的一种改进。这些模型可以用来学习有效的表示。本文将深入研究 VQ-VAE 之前,不过,在这之前我们先讨论一些概率基础和 VAE 架构。
持续学习中避免灾难性遗忘的Elastic Weight Consolidation Loss数学原理及代码实现
在本文中,我们将探讨一种方法来解决这个问题,称为Elastic Weight Consolidation。EWC提供了一种很有前途的方法来减轻灾难性遗忘,使神经网络在获得新技能的同时保留先前学习任务的知识。

【手机群控】 利用Python与uiautomator2实现
使用Python的uiautomator2库进行多设备自动化测试,涉及环境准备(Python、uiautomator2、adb连接设备)和代码实现。通过`adb devices`获取设备列表,使用多进程并行执行测试脚本,每个脚本通过uiautomator2连接设备并获取屏幕尺寸。注意设备需开启USB调试并授权adb。利用多进程而非多线程,因Python的GIL限制。文章提供了一种提高测试效率的方法,适用于大规模设备测试场景。
大数据&AI产品月刊【2024年6月】
大数据&AI产品技术月刊【2024年6月】,涵盖本月技术速递、产品和功能发布、市场和客户应用实践等内容,帮助您快速了解阿里云大数据&AI方面最新动态。

「大数据」Kappa架构
**Kappa架构**聚焦于流处理,用单一处理层应对实时和批量数据,消除Lambda架构的双重系统。通过数据重放保证一致性,简化开发与维护,降低成本,提升灵活性。然而,资源消耗大,复杂查询处理不易。关键技术包括Apache Flink、Spark Streaming、Kafka、DynamoDB等,适合需实时批量数据处理的场景。随着流处理技术进步,其优势日益凸显。
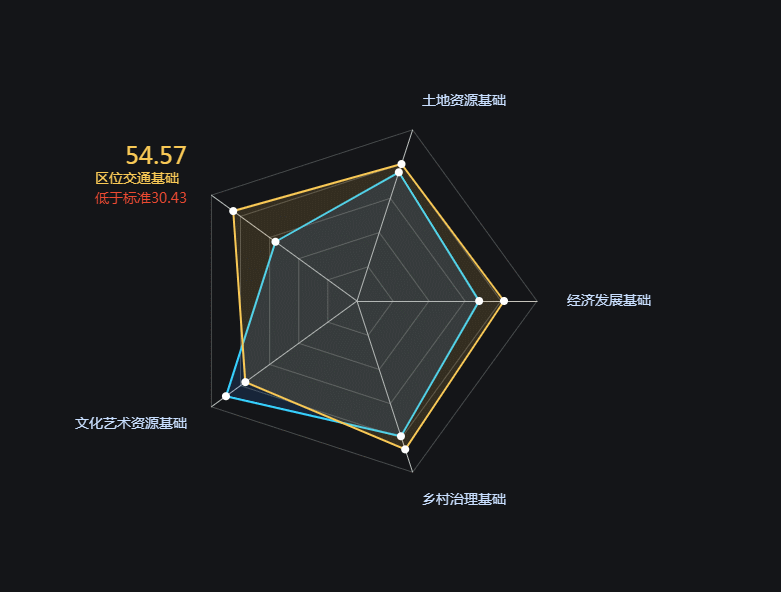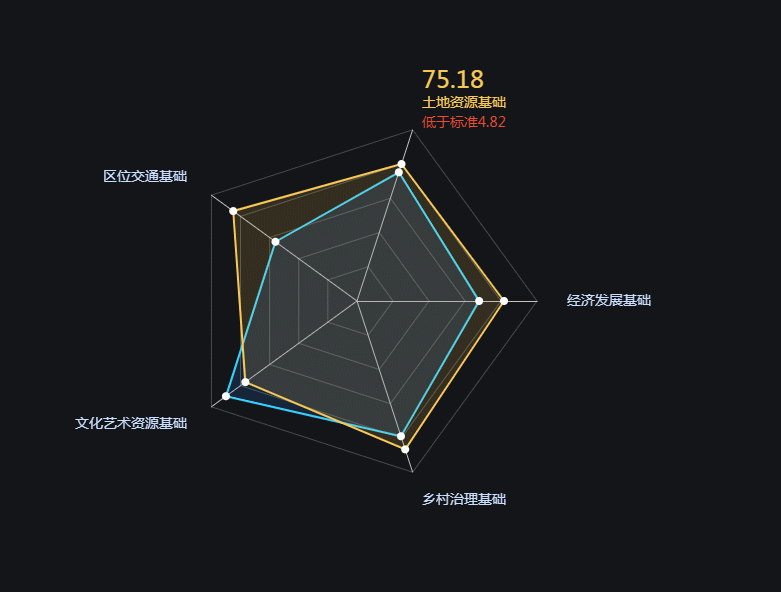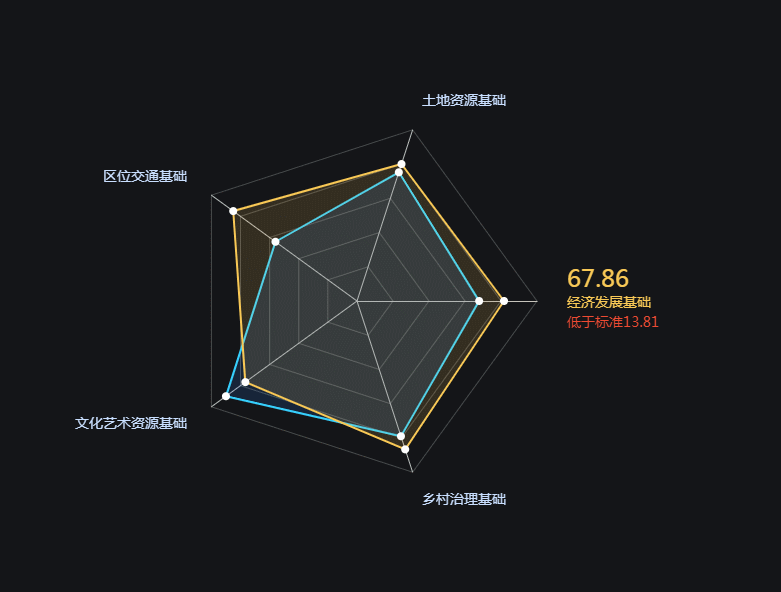
ECharts 雷达图案例001-自定义节点动画
使用ECharts创建自定义雷达图,通过JavaScript动态更新高亮和交互反馈,增强用户体验。关键步骤包括:开启动画效果,数据更新时保持图表状态,鼠标悬浮时动态高亮指标,优化动画性能。案例展示了ECharts在数据可视化中的灵活性和表现力。[查看完整案例](https://download.csdn.net/download/No_Name_Cao_Ni_Mei/89454380)。
android studio开发时提示 TLS 握手错误解决办法
在Windows环境下遇到TLS协议版本不支持的错误,Gradle构建失败。解决方案是在build.gradle.kts中设置系统属性`https.protocols`为`TLSv1.2`,而非遵循误导信息设置为TLSv1.1。
在 Linux 中通过 SSH 执行远程命令时,无法自动加载环境变量(已解决)
SSH远程执行命令时遇到“命令未找到”问题,原因是Linux登录方式不同导致环境变量加载差异。解决方案:将环境变量写入`/etc/profile.d/`下的文件,或手动在命令前加载环境变量,如`source /etc/profile`。
Java一分钟之——Java模块系统:模块化开发(Jigsaw)
【5月更文挑战第20天】Java 9引入了Jigsaw模块系统,改善代码组织和依赖管理。模块通过`module-info.java`定义,声明名称、导出包及依赖。常见问题包括依赖循环、未声明依赖和过度导出。避免这些问题的策略包括明确声明依赖、谨慎导出包和避免循环依赖。通过实例展示了模块间的关系,强调理解模块系统对于构建整洁、安全和可维护的Java应用的重要性。
深入解析xLSTM:LSTM架构的演进及PyTorch代码实现详解
xLSTM的新闻大家可能前几天都已经看过了,原作者提出更强的xLSTM,可以将LSTM扩展到数十亿参数规模,我们今天就来将其与原始的lstm进行一个详细的对比,然后再使用Pytorch实现一个简单的xLSTM。

Golang深入浅出之-Go语言函数基础:定义、调用与多返回值
【4月更文挑战第21天】Go语言函数是代码组织的基本单元,用于封装可重用逻辑。本文介绍了函数定义(包括基本形式、命名、参数列表和多返回值)、调用以及匿名函数与闭包。在函数定义时,注意参数命名和注释,避免参数顺序混淆。在调用时,要检查并处理多返回值中的错误。理解闭包原理,小心处理外部变量引用,以提升代码质量和可维护性。通过实践和示例,能更好地掌握Go语言函数。

基于 Kyuubi 实现分布式 Flink SQL 网关
本文整理自网易互娱资深开发工程师、Apache Kyuubi Committer 林小铂的《基于 Kyuubi 实现分布式 Flink SQL 网关》分享。
选择最适合数据的嵌入模型:OpenAI 和开源多语言嵌入的对比测试
OpenAI最近发布了他们的新一代嵌入模型*embedding v3*,他们将其描述为性能最好的嵌入模型,具有更高的多语言性能。这些模型分为两类:较小的称为text- embeddings -3-small,较大且功能更强大的称为text- embeddings -3-large。

Next Station of Flink CDC
本文整理自阿里云智能 Flink SQL、Flink CDC 负责人伍翀(花名:云邪),在 Flink Forward Asia 2023 主会场的分享。

【保姆级教程】用PAI-DSW修复亚运历史老照片
本教程整合了来自开源社区的高质量图像修复、去噪、上色等算法,并使用 Stable Diffusion WebUI 进行交互式图像修复。参与者可以根据需要进行参数调整,组合不同的处理方式以获得最佳修复效果。参与者还可以在活动页面上传修复后的成果图片,参与比赛,获胜者将有机会获得丰厚的奖品。


超详攻略!Databricks 数据洞察 - 企业级全托管 Spark 大数据分析平台及案例分析
5分钟读懂 Databricks 数据洞察 ~ 更多详细信息可登录 Databricks 数据洞察 产品链接:https://www.aliyun.com/product/bigdata/spark(当前产品提供¥599首购试用活动,欢迎试用!)

【最佳实践】阿里云 Elasticsearch 索引数据生命周期管理
索引生命周期管理(ILM)是指:ES数据索引从设置,创建,打开,关闭,删除的全生命周期过程的管理;为了降低索引存储成本,提升集群性能和执行效率,我们可以通过对存储在阿里云 Elasticsearch 的数据做生命周期管理。

【最佳实践】 轻量化数据采集器Beats入门教程
轻量化数据采集器Beats入门教程,帮助 Elasticsearch 初学者全面了解什么是 Beats、如何快速部署 Beats。
优酷背后的大数据秘密
大家好,我是门德亮,现在在优酷数据中台做数据相关的事情。很荣幸,我正好见证了优酷从没有MaxCompute到有的这样一个历程,因为刚刚好我就是入职优酷差不多5年的时间,我们正好是在快到5年的时候,去做了从Hadoop到MaxCompute的这样一个升级。
#Nginx教程 Nginx作为目前最流行的高性能Web服务器和反向代理服务器,凭借其高并发、低内存消耗的特点,被广泛应用于各类生产环境。本文将从零开始,带你快速掌握Nginx的核心配置与实战技巧。
本教程详解Nginx安装、核心配置、反向代理、负载均衡与HTTPS部署,并内嵌标准JSON-LD结构化数据(Article/BreadcrumbList/WebPage等),助力SEO优化与搜索富摘要展现,提升点击率。
多平台无缝对接!taocarts技术解密:一键打通Shopify/Coupang等海外渠道
在跨境代购行业,“多渠道布局”已成为从业者的核心竞争力——仅做单一平台的代购,难以实现规模化增长,而打通多海外平台,实现商品、订单同步,成为代购系统开发的核心需求。taocarts跨境独立站系统依托React Native、Express.js等技术,实现一键上传商品至Shopify、Coupang、Woo商城、Base商城,同步订单并自动采购,彻底解决代购从业者“多平台运营繁琐”的痛点,以下从技术实现层面,为阿里云社区开发者提供干货分享。
快速接入京东商品评论API,商品口碑监测与舆情风控
依托京东官方评价API,融合AI/NLP技术,构建“采集—分析—预警—决策”全链路口碑风控体系:实时监测情感倾向与负面问题,智能分级预警,支持归因分析与工单处置,助力品牌从被动响应转向主动运营。(239字)

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。
