









开发者必看:HTTP 2xx 响应码的正确理解与运用
HTTP 2xx状态码表示请求成功,涵盖200(成功)、201(已创建)、202(已接受)、204(无内容)和206(部分内容)五类。开发者需准确识别以优化调试与用户体验。
淘宝图片搜索API(taobao.item_search_img)
淘宝图片搜索API是阿里基于深度学习的视觉检索服务,支持以图搜同款/相似商品,毫秒级响应、高准确率。提供商品、交易、店铺等结构化数据,适配选品、同款监控、智能上架等场景,合规高效,助力电商数字化升级。(239字)
淘宝商品详情API(tb.item_get)
本文详解淘宝开放平台商品详情核心API(如item_get),涵盖对接流程、权限申请、请求规范、参数说明及返回字段,并列举代购集运、选品分析、比价导购等典型应用场景,助力开发者合规高效获取商品数据。(239字)
从原理到实践:零代码也能搞定的PPO微调全攻略
本文深入浅出解析PPO(近端策略优化)算法——大模型对齐人类偏好的核心技术。通过“温和教练”比喻、四步原理拆解与实操指南,零基础也能理解其剪切机制、优势函数与稳定训练逻辑,并亲手微调出更懂你的AI。(239字)
【赵渝强老师】基于Hudi的大数据湖仓一体架构
Apache Hudi(Hadoop Upserts Delete and Incremental)是开源的流式数据湖平台,支持事务、高效upsert/delete、增量处理、多引擎SQL读写(Spark/Flink/Trino等),自动管理小文件与压缩,兼容云存储,助力构建湖仓一体架构。
智能体来了从 0 到 1:为什么一开始必须划清智能体的任务边界?
智能体开发切忌“全能幻想”!本文指出:任务边界(输入范围、工具权限、决策规则)是智能体从Demo走向落地的生命线——它不设限能力,而是将LLM的概率输出转化为可控、稳定、可评估的工程系统。边界清晰,方能降幻觉、控成本、提准确率。
【AI大模型面试宝典七】- 训练优化篇
【AI大模型面试宝典】详解知识蒸馏:从软标签、温度机制到特征对齐,涵盖KL散度、黑/白盒蒸馏策略与代码实现,拆解高频面试题,助你精准掌握大模型压缩核心考点,轻松应对技术追问,offer拿到手软!
Vue3 Composition API深度解析:原理、用法与迁移实践
本文深度解析Vue3 Composition API的核心优势、常用API、底层原理与迁移实践,对比Options API的局限性,详解ref、reactive、watch、生命周期钩子等用法,剖析基于Proxy的响应式机制,并提供渐进式迁移策略,助开发者高效掌握Vue3开发范式。

用 Python 实现 MySQL 数据库定时自动备份
本文介绍如何用Python脚本实现MySQL数据库的自动化备份。通过调用`mysqldump`工具,结合时间戳命名、文件压缩与定时任务(如crontab),可轻松实现“无人值守”备份。涵盖配置修改、安全建议及日志管理,提升备份效率与可靠性,适用于日常开发与生产环境。
报错解决:Selenium报错“Message: session not created: probably user data directory is already in use” 等
本文详解Selenium操作Edge浏览器时常见的“版本不匹配”和“进程冲突”问题,分析报错根源,并提供手动替换驱动与webdriver-manager自动管理两种解决方案,助你高效稳定实现浏览器自动化。
【赵渝强老师】阿里云大数据集成开发平台DataWorks
DataWorks是阿里云一站式大数据开发治理平台,支持数据集成、开发、建模、分析、质量监控、服务化及迁移等全链路功能,兼容多种计算引擎,助力企业高效构建数据中台,实现数据资产化与价值挖掘。
闲鱼商品详情API数据解析(附代码)
闲鱼商品详情API(goodfish.item_get)支持通过商品ID获取标题、价格、描述等信息,适用于比价、推荐系统及市场分析。接口支持GET/POST请求,返回JSON格式数据,并提供Python调用示例,便于开发者快速集成。
Java 实现 SMTP 协议调用的详细示例及实战指南 SMTP Java 调用示例
本文介绍了如何使用Java调用SMTP协议发送邮件,涵盖SMTP基本概念、JavaMail API配置、代码实现及注意事项,适合Java开发者快速掌握邮件发送功能集成。
开发效率提升5倍!聚AI的LangFlow可视化全栈指南
LangFlow 是一个强大的可视化流程开发工具,支持全平台部署与多模型集成。通过 Docker 快速启动、本地开发或云服务部署,用户可灵活配置环境。其核心功能包括四大对象管理、可视化编程、自定义组件开发及与 LangChain 的深度整合,适用于客户服务、金融、医疗等多领域自动化流程构建。结合性能优化与版本管理,助力开发者高效实现企业级 AI 应用。
Post-Training on PAI (4):模型微调SFT、DPO、GRPO
阿里云人工智能平台 PAI 提供了完整的模型微调产品能力,支持 监督微调(SFT)、偏好对齐(DPO)、强化学习微调(GRPO) 等业界常用模型微调训练方式。根据客户需求及代码能力层级,分别提供了 PAI-Model Gallery 一键微调、PAI-DSW Notebook 编程微调、PAI-DLC 容器化任务微调的全套产品功能。
瓴羊入选中国信通院《AI Agent智能体产业图谱》
2025数据智能大会在京召开,中国信通院发布《AI Agent智能体产业图谱1.0》,瓴羊Quick BI凭借智能数据分析能力入选。该图谱系统梳理AI Agent产业生态,涵盖基础底座、平台、通用与行业智能体四大领域。Quick BI通过融合大模型技术,重构企业数据分析方式,实现从“被动响应”到“主动服务”的升级,广泛应用于供应链、零售、财务等多个场景。此次入选标志着瓴羊在数据分析智能体领域的创新成果获高度认可。作为阿里巴巴旗下数智服务品牌,瓴羊将持续推动企业智能化转型,释放数据价值,助力“人工智能+”深度发展。
构建AI时代的大数据基础设施-MaxCompute多模态数据处理最佳实践
本文介绍了大数据与AI一体化架构的演进及其实现方法,重点探讨了Data+AI开发全生命周期的关键步骤。文章分析了大模型开发中的典型挑战,如数据管理混乱、开发效率低下和运维管理困难,并提出了解决方案。同时,详细描述了MaxCompute在构建AI时代数据基础设施中的作用,包括其强大的计算能力、调度能力和易用性特点。此外,还展示了MaxCompute在多模态数据处理中的应用实践以及具体客户案例,最后提供了体验MaxFrame解决方案的方式。
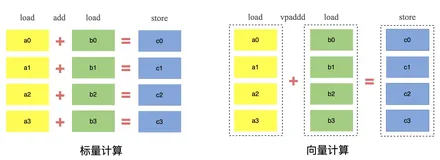
流批一体向量化引擎Flex
本文整理自蚂蚁集团技术专家刘勇在Flink Forward Asia 2024上的分享,聚焦流批一体向量化引擎的背景、架构及未来规划。内容涵盖向量化计算的基础原理(如SIMD指令)、现有技术现状,以及蚂蚁在Flink 1.18中引入的C++开发向量化计算实践。通过Flex引擎(基于Velox构建),实现比原生执行引擎更高的吞吐量和更低的成本。文章还详细介绍了功能性优化、正确性验证、易用性和稳定性建设,并展示了线上作业性能提升的具体数据(平均提升75%,最佳达14倍)。最后展望了未来规划,包括全新数据转换层、与Paimon结合及支持更多算子和SIMD函数。

构建智能AI记忆系统:多智能体系统记忆机制的设计与技术实现
本文探讨了多智能体系统中记忆机制的设计与实现,提出构建精细化记忆体系以模拟人类认知过程。文章分析了上下文窗口限制的技术挑战,并介绍了四种记忆类型:即时工作记忆、情节记忆、程序性记忆和语义知识系统。通过基于文件的工作上下文记忆、模型上下文协议的数据库集成以及RAG系统等技术方案,满足不同记忆需求。此外,高级技术如动态示例选择、记忆蒸馏和冲突解决机制进一步提升系统智能化水平。总结指出,这些技术推动智能体向更接近人类认知的复杂记忆处理机制发展,为人工智能开辟新路径。
大模型备案需要通过算法备案才能进行吗?
本内容详细介绍了算法备案与大模型备案的流程、审核重点及两者关系。算法备案覆盖生成合成类等5类算法,需提交安全自评估报告,审核周期约2个月;大模型备案针对境内公众服务的大模型,涉及多维度审查,周期3-6个月。两者存在前置条件关系,完成算法备案是大模型备案的基础。阿里云提供全流程工具支持,包括合规预评估、材料校验和进度追踪,助力企业高效备案。此外,文档解答了常见问题,如算法迭代是否需重新备案,并解析政策红利与技术支持,帮助企业降低合规成本、享受补贴奖励。适用于需了解备案流程和技术支持的企业和个人开发者。
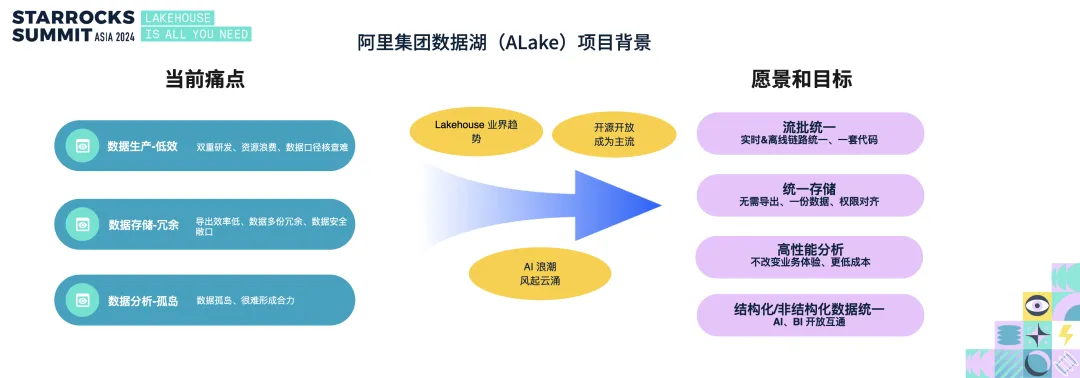
StarRocks + Paimon 在阿里集团 Lakehouse 的探索与实践
阿里集团在推进湖仓一体化建设过程中,依托 StarRocks 强大的 OLAP 查询能力与 Paimon 的高效数据入湖特性,实现了流批一体、存储成本大幅下降、查询性能数倍提升的显著成效: A+ 业务借助 Paimon 的准实时入湖,显著降低了存储成本,并引入 StarRocks 提升查询性能。升级后,数据时效提前60分钟,开发效率提升50%;JSON列化存储减少50%,查询性能提升最高达10倍;OLAP分析中,非JOIN查询快1倍,JOIN查询快5倍。 饿了么升级为准实时Lakehouse架构后,在时效性仅损失1-5分钟的前提下,实现Flink资源缩减、StarRocks查询性能提升(仅5%
金融数据分析:解析JavaScript渲染的隐藏表格
本文详解了如何使用Python与Selenium结合代理IP技术,从金融网站(如东方财富网)抓取由JavaScript渲染的隐藏表格数据。内容涵盖环境搭建、代理配置、模拟用户行为、数据解析与分析等关键步骤。通过设置Cookie和User-Agent,突破反爬机制;借助Selenium等待页面渲染,精准定位动态数据。同时,提供了常见错误解决方案及延伸练习,帮助读者掌握金融数据采集的核心技能,为投资决策提供支持。注意规避动态加载、代理验证及元素定位等潜在陷阱,确保数据抓取高效稳定。
微信公众号接口测试实战指南
微信公众号接口测试是确保系统稳定性和功能完整性的重要环节。本文详细介绍了测试全流程,包括准备、工具选择(如Postman、JMeter)、用例设计与执行,以及常见问题的解决方法。通过全面测试,可以提前发现潜在问题,优化用户体验,确保公众号上线后稳定运行。内容涵盖基础接口、高级接口、微信支付和数据统计接口的测试,强调了功能验证、性能优化、安全保护及用户体验的重要性。未来,随着微信生态的发展,接口测试将面临更多挑战和机遇,如小程序融合、AI应用和国际化拓展。

DataWorks Copilot:让你的数据质量覆盖率一键飞升!
在数据加工链路中,如何确保高质量的数据产出是一个一直需要重点解决的问题。阿里云DataWorks的数据质量规则模板可以帮助用户建设数据质量,在离线表上定义相关的规则。为优化手动配置规则的工作量,DataWorks的智能助手 DataWorks Copilot 推出了数据质量规则推荐功能,您可以使用这一功能,一键提升数据质量覆盖度。
Python环境管理的新选择:UV和Pixi,高性能Python环境管理方案
近期Python生态系统在包管理领域发生了重要变化,Anaconda调整商业许可证政策,促使社区寻找更开放的解决方案。本文介绍两款新一代Python包管理工具:UV和Pixi。UV用Rust编写,提供高性能依赖解析和项目级环境管理;Pixi基于Conda生态系统,支持conda-forge和PyPI包管理。两者分别适用于高性能需求和深度学习项目,为开发者提供了更多选择。
数据仓库建模规范思考
本文介绍了数据仓库建模规范,包括模型分层、设计、数据类型、命名及接口开发等方面的详细规定。通过规范化分层逻辑、高内聚松耦合的设计、明确的命名规范和数据类型转换规则,提高数据仓库的可维护性、可扩展性和数据质量,为企业决策提供支持。

使用PaliGemma2构建多模态目标检测系统:从架构设计到性能优化的技术实践指南
本文详细介绍了PaliGemma2模型的微调流程及其在目标检测任务中的应用。PaliGemma2通过整合SigLIP-So400m视觉编码器与Gemma 2系列语言模型,实现了多模态数据的高效处理。文章涵盖了开发环境构建、数据集预处理、模型初始化与配置、数据加载系统实现、模型微调、推理与评估系统以及性能分析与优化策略等内容。特别强调了计算资源优化、训练过程监控和自动化优化流程的重要性,为机器学习工程师和研究人员提供了系统化的技术方案。
【赵渝强老师】部署Hadoop的本地模式
本文介绍了Hadoop的目录结构及本地模式部署方法,包括解压安装、设置环境变量、配置Hadoop参数等步骤,并通过一个简单的WordCount程序示例,演示了如何在本地模式下运行MapReduce任务。
【赵渝强老师】基于Flink的流批一体架构
本文介绍了Flink如何实现流批一体的系统架构,包括数据集成、数仓架构和数据湖的流批一体方案。Flink通过统一的开发规范和SQL支持,解决了传统架构中的多套技术栈、数据链路冗余和数据口径不一致等问题,提高了开发效率和数据一致性。
基于prim算法求出网络最小生成树实现网络社团划分和规划
该程序使用MATLAB 2022a版实现路线规划,通过排序节点权值并运用Prim算法生成最小生成树完成网络规划。程序基于TSP问题,采用遗传算法与粒子群优化算法进行路径优化。遗传算法通过编码、选择、交叉及变异操作迭代寻优;粒子群优化算法则通过模拟鸟群觅食行为,更新粒子速度和位置以寻找最优解。
Selenium中如何实现翻页功能
在使用Python的Selenium库进行网页爬虫开发时,翻页操作是常见需求。本文详细介绍如何通过Selenium实现翻页,包括定位翻页控件、执行翻页动作以及等待页面加载等关键步骤,并提供了基于“下一页”按钮和输入页码两种方式的具体示例代码。此外,还特别提醒开发者注意页面加载完全、动态内容加载及反爬机制等问题,确保爬虫稳定高效运行。
数据治理:如何制定数据标准与规范
在当今这个数据驱动的时代,数据已成为企业最宝贵的资产之一。然而,随着数据量的爆炸性增长和数据来源的多样化,如何有效地管理和利用这些数据成为了企业面临的重大挑战。数据治理作为确保数据质量、安全性、合规性和可访问性的关键过程,其核心在于制定并执行一套科学、合理的数据标准与规范。本文将探讨如何制定数据标准与规范,以推动企业的数据治理实践。
Chrome浏览器启动参数大全
这是一组用于定制浏览器行为的命令行参数,包括但不限于:不停用过期插件、放行非安全内容、允许应用中心脚本、停用GPU加速视频、禁用桌面通知、禁用拓展及各类API、调整缓存设置、启用打印预览、隐身模式启动、设定语言、使用代理服务器、无头模式运行等。通过这些参数,用户可以根据需求灵活调整浏览器功能与性能。
数据治理:实现原始数据不出域,确保数据可用不可见的创新策略
在数字化时代,数据成为企业宝贵资产,驱动业务决策与创新。然而,数据量激增和流通频繁带来了安全和管理挑战。“原始数据不出域,数据可用不可见”的治理理念应运而生,通过数据脱敏、沙箱技术和安全多方计算等手段,确保数据安全共享与高效利用。这一理念已广泛应用于金融、医疗等行业,提升了数据价值和企业竞争力。

CDN服务器真实地址
Discover CDN server real IP addresses using Traceroute & Whois, CDN provider logs (with provider cooperation), analyzing HTTP headers, online tools, or the ping command. Note that CDN

爬虫技术升级:如何结合DrissionPage和Auth代理插件实现数据采集
本文介绍了在Python中使用DrissionPage库和Auth代理Chrome插件抓取163新闻网站数据的方法。针对许多爬虫框架不支持代理认证的问题,文章提出了通过代码生成包含认证信息的Chrome插件来配置代理。示例代码展示了如何创建插件并利用DrissionPage进行网页自动化,成功访问需要代理的网站并打印页面标题。该方法有效解决了代理认证难题,提高了爬虫的效率和安全性,适用于各种需要代理认证的网页数据采集。
整合LlamaIndex与LangChain构建高级的查询处理系统
该文阐述了如何结合LlamaIndex和LangChain构建一个扩展性和定制性强的代理RAG应用。LlamaIndex擅长智能搜索,LangChain提供跨平台兼容性。代理RAG允许大型语言模型访问多个查询引擎,增强决策能力和多样化回答。文章通过示例代码展示了如何设置LLM、嵌入模型、LlamaIndex索引及查询引擎,并将它们转换为LangChain兼容的工具,实现高效、精准的问题解答。通过多代理协作,系统能处理复杂查询,提高答案质量和相关性。
循环编码:时间序列中周期性特征的一种常用编码方式
循环编码是深度学习中处理周期性数据的一种技术,常用于时间序列预测。它将周期性特征(如小时、日、月)转换为网络可理解的形式,帮助模型识别周期性变化。传统的one-hot编码将时间特征转换为分类特征,而循环编码利用正弦和余弦转换,保持时间顺序信息。通过将时间戳转换为弧度并应用sin和cos,每个原始特征只映射到两个新特征,减少了特征数量。这种方法在神经网络中有效,但在树模型中可能需谨慎使用。
实时数仓 Hologres产品使用合集之报错:ORCA failed to produce a plan : PlStmt Translation: Group by key is type of imprecise not supported如何解决
实时数仓Hologres是阿里云推出的一款高性能、实时分析的数据库服务,专为大数据分析和复杂查询场景设计。使用Hologres,企业能够打破传统数据仓库的延迟瓶颈,实现数据到决策的无缝衔接,加速业务创新和响应速度。以下是Hologres产品的一些典型使用场景合集。
如何为Kafka加上账号密码(二)
本小节我们就为Kafka添加最简单的认证方式,也就是SASL_PLAINTEXT(即SASL/PLAIN+ 非加密通道)。

大数据与机器学习
大数据领域前沿技术分享与交流,这里不止有技术干货、学习心得、企业实践、社区活动,还有未来。
