
Flink这个需求可以满足不?双流join, 两个流中的数据可能前后相差不到1分钟会写入业务库,但是之后两个表的数据都会变更,变更的时间就不一定了,可能已经超过了状态时间。比如 A表 join B表,关联成功后,过了2天,A表中的部分字段做了更新,B表不变,A表变更的字段要更新到结果表,可能又过了2天B表字段也做了变更 , A表没变,B表变更的字段也要更新到结果表
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Flink可以满足这种双流Join的需求。在实际应用中,经常会遇到需要同步来自两个不同数据源的数据的情况。例如,在电商场景中,可能需要关联订单表和用户表的数据以进行进一步的分析和处理。
在Flink中,可以通过多种方式实现双流Join操作。其中,Window Join、Interval Join和Regular Join是三种常用的解决方案。这些方法各有优劣,可以根据具体需求选择最适合的方案。下面逐一分析这些方法:
Window Join:此方法通过将流数据划分为时间窗口,将无界数据变为有界数据,然后在相同的时间窗口内进行Join操作。这种方式适用于那些允许一定时间延迟的场景,因为只有在窗口结束时才会输出结果。
Interval Join:与Window Join不同,Interval Join开辟了一个新的时间间隔,对于每一条流数据,它会检查在设定的时间间隔内是否有匹配的数据。这种方法适用于需要精确匹配但允许一定时间差异的场景。
Regular Join:这种方法不需要划分时间窗口,而是直接对两条流进行Join操作。它适用于实时性要求高且数据到达时间非常接近的情况。然而,如果数据到达时间差距较大,可能会遇到数据丢失或结果不准确的问题。
综上所述,Flink提供了多种灵活的双流Join解决方案,可以高效地应对不同的数据处理需求。通过合理选择和优化Join策略,可以确保数据的准确同步和高效处理。在实际应用中,建议结合具体的业务需求和数据特性,选择合适的Join方法,并适时采用优化措施提升性能。
开两个cdc互相look up join实时打款解决的state过大问题。https://help.aliyun.com/zh/flink/developer-reference/join-statements-for-dimension-tables?spm=a2c4g.11174283.0.i3 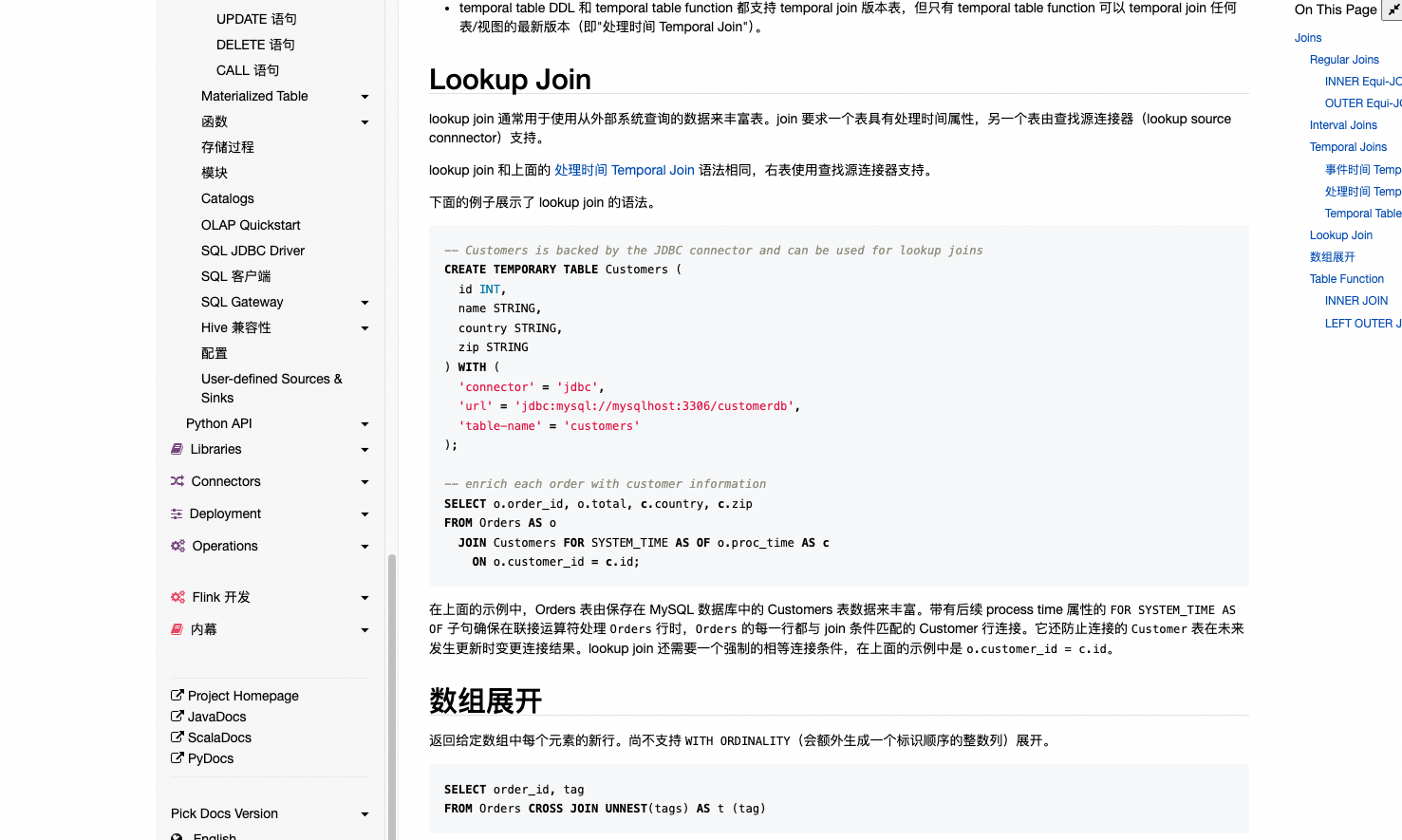
此回答整理自钉群“实时计算Flink产品公有云外部客户交流群”
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


