
UNIVERSAL-ASR语音识别基础框架的主要特点是什么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
,阿里巴巴语音实验室创新性地提出和设计了离线流式一体化语音识别系统--UNIVERSAL ASR,同时具有高精度和低延时的特点,不仅能够实时输出语音识别结果,还可在说话句尾用高精度的解码结果修正输出,与此同时,UNIVERSAL ASR 采用动态延时训练的方式,替代了之前维护多套延时流式系统的做法。通过设计 UNIVERSAL ASR 语音识别系统,我们将之前多套语音识别系统架构统一为一套系统架构,一个模型满足所有业务场景,显著的降低了模型生产和维护成本。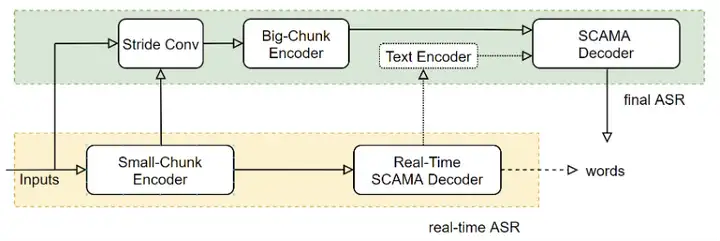
UNIVERSAL ASR 模型结构如上图所示,包含离线语音识别部分和流式语音识别部分。其中,离线与流式部分通过共享一个动态编码器(Encoder)结构来降低计算量。流式语音识别部分是由动态时延 Encoder 与流式解码器(Decoder)构成。动态时延 Encoder 采用时延受限可控记忆单元的自注意力(LC-SAN-M)结构;流式 Decoder 采用动态 SCAMA 结构。离线语音识别部分包含了降采样层(Sride Conv)、Big-Chunk Encoder、文本 Encoder 与 SCAMA Decoder。为了降低刷新输出结果的尾点延时,离线识别部分采用大 Chunk 流式结构。其中,Stride Conv 结构是为了降低计算量。文本 Encoder 增加了离线识别的语义信息。为了让模型能够具有不同延时下进行语音识别的能力,我们创新性地设计了动态时延训练机制,使得模型能够同时满足不同业务场景对延时和准确率的要求。
——参考链接。

