
语音识别基础框架经历了怎样的演变?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
现代语音识别可以追溯到1952年,Davis等人研制了世界上第一个能识别10个英文数字发音的实验系统,从此正式开启了语音识别的进程。语音识别发展到今天已经有70多年,但从技术方向上可以大体分为三个阶段。
下图是从1993年到2017年在Switchboard上语音识别率的进展情况,从图中也可以看出1993年到2009年,语音识别一直处于GMM-HMM时代,语音识别率提升缓慢,尤其是2000年到2009年语音识别率基本处于停滞状态。2009年随着深度学习技术,特别是DNN的兴起,语音识别框架变为DNN-HMM,语音识别进入了DNN时代,语音识别精准率得到了显著提升。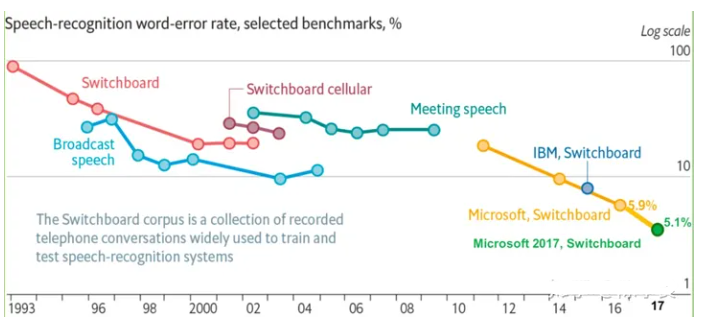
2015年以后,由于“端到端”技术兴起,语音识别进入了百花齐放时代,语音界都在训练更深、更复杂的网络,同时利用端到端技术进一步大幅提升了语音识别的性能,直到2017年微软在Swichboard上达到词错误率5.1%,从而让语音识别的准确性首次超越了人类,当然这是在一定限定条件下的实验结果,还不具有普遍代表性。
——参考链接。

