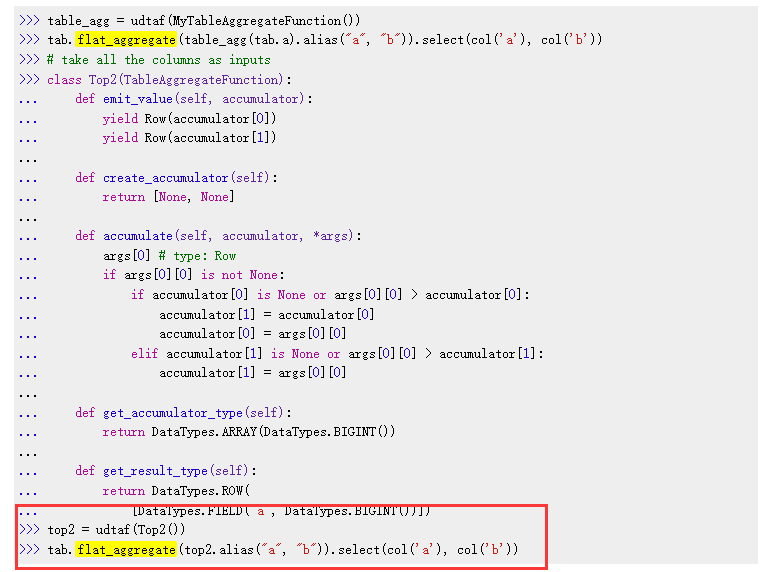
有大佬在pyflink table的batch_mode用flat_aggregate碰到过报错的问题啊?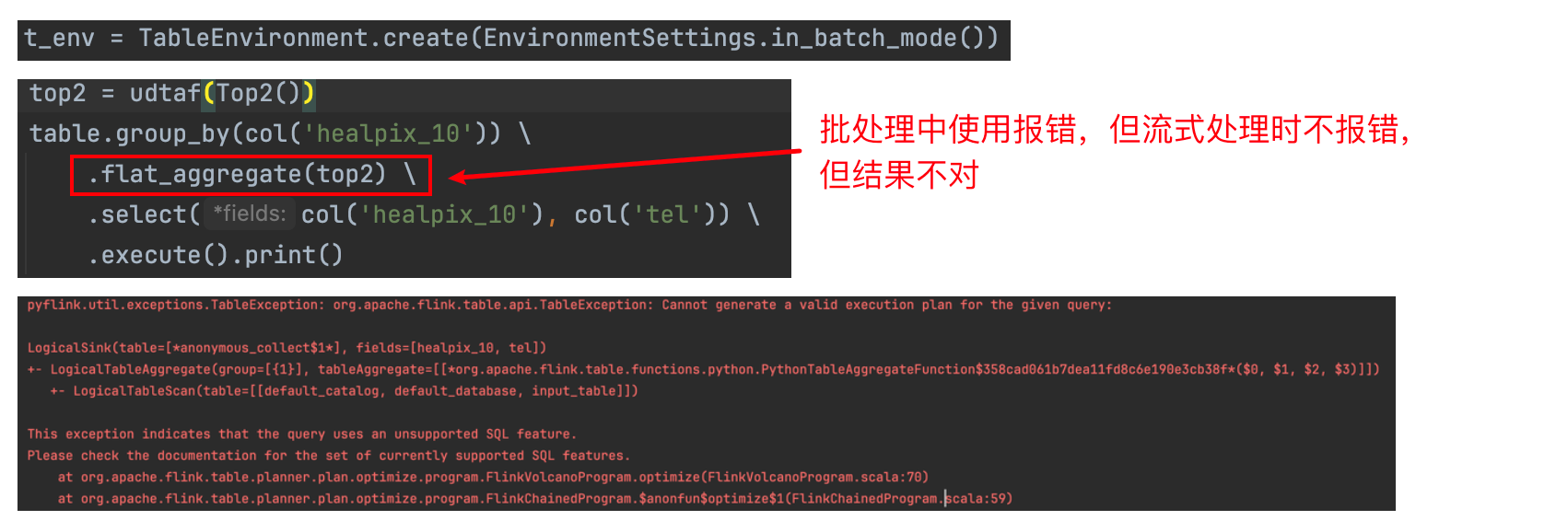
在stream_mode时不报错,但batch_mode会有上面的问题
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在使用 PyFlink 的 TableEnvironment 的批处理模式(batch mode)中使用 flat_aggregate 函数时,你可能会遇到一些错误。这是因为 flat_aggregate 函数主要用于流处理模式,而在批处理模式下,它的行为可能会有所不同。
如果你在批处理模式下遇到了错误,可能是因为以下原因:
不支持的操作:在批处理模式下,某些操作可能不被支持。例如,flat_aggregate 函数可能在批处理模式下不被支持。
错误的用法:你可能没有按照正确的方式使用 flat_aggregate 函数。例如,你可能没有提供正确的参数,或者没有按照正确的方式调用函数。
版本问题:如果你使用的是旧版本的 PyFlink,那么可能存在一些已知的 bug。在这种情况下,升级到最新版本的 PyFlink 可能会解决问题。
配置问题:你的 PyFlink 配置可能不正确。例如,你可能没有正确地设置批处理模式。
为了解决这个问题,你可以尝试以下步骤:
检查文档:查阅 PyFlink 的官方文档,了解 flat_aggregate 函数在批处理模式下的正确用法。
更新版本:如果你使用的是旧版本的 PyFlink,尝试升级到最新版本。
检查配置:确保你的 PyFlink 配置是正确的,特别是关于批处理模式的配置。
寻求社区帮助:如果你仍然遇到问题,可以在 PyFlink 的社区论坛或者 GitHub 仓库中寻求帮助。
从提供的日志信息来看,在使用 PyFlink 的 TableEnvironment 的批处理模式(batch mode)中使用 flat_aggregate 函数时遇到了错误。
你需要确保字段名称在 group_by 和 select 语句中是一致的,并且与输入表中的字段匹配。
并且flat_aggregate 通常用于流式环境中的无界聚合,你看看它在批处理环境中的用法是否正确
或者你可以换其他聚合函数 比如 AggregateFunction
数据类型不匹配、UDF(User-Defined Function)实现不当、SQL语法错误、并行度设置不合理,在PyFlink中使用flat_aggregate函数时,batch_mode和stream_mode的行为有所不同。根据您提供的信息,似乎在批处理模式下使用自定义Python UDTF引发了错误。错误消息表明,无法生成有效的执行计划以支持给定查询
可能是你配置不兼容,确认您的数据源是否支持批处理模式,如果不支持,则应切换到流处理模板或选择一个支持批处理的数据源
flat_aggregate 允许用户自定义聚合逻辑,但不是所有的聚合函数都能在所有场景下使用。确保你使用的聚合函数适用于你的数据和聚合逻辑。
如果作业因为资源不足(如内存不足)而失败,可能会抛出报错。检查 Flink 集群的资源配置,并确保有足够的资源来执行作业。
在使用PyFlink Table API的batch_mode并尝试应用flat_aggregate函数时,您可能会遇到特定的错误情况。已有的报错示例为您提供一些指导和潜在问题分析。
https://help.aliyun.com/zh/hologres/support/troubleshoot-blink-and-flink-issues?spm=a2c6h.13066369.question.71.1c5a6823NadK5c
是的,在PyFlink中使用flat_aggregate函数时,batch_mode和stream_mode的行为有所不同。根据您提供的信息,似乎在批处理模式下使用自定义Python UDTF引发了错误。错误消息表明,无法生成有效的执行计划以支持给定查询。这可能是因为在批处理模式下不支持某些SQL特性,或者您的自定义函数存在一些问题。你可以尝试:
确保您的自定义Python UDTF正确实现了所需的方法,并且可以在流式处理模式下正常工作。
检查是否可以将您的自定义函数替换为内置的Table API函数或UDFs,这些函数通常具有更好的兼容性和性能。
如果必须使用自定义Python UDTF,请尝试优化代码并确保它符合Apache Flink对Python UDFs的要求。
在批处理模式下,尝试使用其他聚合方法(如group_by和aggregate),看看是否会出现相同的问题
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。