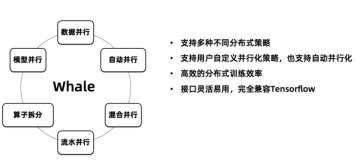
Tensorflow
- 2015年11月的一天,Google发布了Tensorflow的白皮书并很快将Tensorflow开源。以Google的技术影响力,这个新闻在技术圈很快扩散,大家听着这个陌生的名词兴奋而又没有太多头绪。Tensor到底是什么,Tensorflow什么定位,Google为什么要将它开源...
- 2016年3月,AlphaGo与围棋世界冠军、职业九段棋手李世石进行围棋人机大战,以4比1的总比分获胜;
- 2016年末2017年初AlphaGo在中国棋类网站上以“大师”(Master)为注册账号与中日韩数十位围棋高手进行快棋对决,连续60局无一败绩
- 2017年5月27日,在柯洁与AlphaGo的人机大战之后,阿尔法围棋团队宣布AlphaGo将不再参加围棋比赛。
- 2017年10月18日,DeepMind团队公布了最强版AlphaGo,代号AlphaGo Zero 采用无监督学习
Operations(OP)
Tensorflow中全部操作均视为是OP,例如传入Tensor、运算、会话
Tensor(张量)
Tensorflow中所有传入的数据统称为Tensor,Tensor可以理解为一个容器
标量(纯量)
零维的Tensor称之为标量 ,简单来说就是一个一个的数字例如:
1,2,3,4,5 向量
一维Tensor称之为向量 可以用一维数组来表示,相当于一列数据或者一行数据 例如:
[1,2,3,4,5,6]
[2,3,4,5,6]矩阵
二维Tensor称之为矩阵,可以用二维数组来表示,相当于一张表 例如:
[
[1,2,3,4,5,6],
[2,3,4,5,6,7],
[3,4,5,6,7,8]
]
[[1,2,3,4,5,6], [2,3,4,5,6,7],[3,4,5,6,7,8]]N阶张量
我们把超过二阶的Tensor称之为N阶张量,例如N=3 称为三阶张量,同样,我们也可以把向量称为一阶张量,矩阵称为二阶张量
[[[[[2,3,4,5,5],[1,2,3,3]][[1,2,3,3,],[2,2,2,3]...]]]]Graph(图)
我们把用来承载op及tensor的容器称之为Graph,每个Tensorflow 程序都有一个默认图,可创建新的图
默认图
# 使用默认图
a = tf.constant(3.0)
b = tf.constant(3.0)
t1 = tf.add(a,b)
graph = tf.get_default_graph()自定义图
#创新新图
g1 = tf.Graph()
with g1.as_default():
c = tf.constant(32.0)
d = tf.constant(32.0)
t2 = tf.add(c,d)Session(会话)
用来运行Graph的OP称之为Session ,一个Session每次只能运行一个Graph,Session也是一个OP,Session不指定图时,默认执行默认图,指定图时执行指定图
指定图
g1 = tf.Graph()
with g1.as_default():
# 定义op及tensor
c = tf.constant(32.0)
d = tf.constant(32.0)
t2 = tf.add(c,d)
with tf.Session(graph=g1) as sess:
sess.run(g1)变量
创建变量也是一个op,tensorflow中变量使用tf.Variable来创建,变量可以持久化保存,普通tensor不能, 定义一个变量op的时候一定要在Session中初始化
# 定义tensor
x = tf.constant([1,2,3,4,5])
# 定义变量
b = tf.Variable(tf.random_normal([2,3],mean=0.0,stddev=1.0))
# 定义出初始化 只是定义未执行
init = tf.global_variables_initializer()
with tf.Session() as sess:
# 执行初始化变量
sess.run(init)
# 执行打印变量
print(sess.run(b))可视化
Ttensorflow提供了web可视化工具,通过使用tf.summary.FileWriter方法输出序列化文件,通过tensorboard读取序列化文件并展示出来,可以通过op的name属性控制后台显示
输出序列化
#tf.summary.FileWriter('文件输出目录',graph=指定的图)tf.summary.FileWriter('./tmp/summary/test/',graph=sess.graph)读取序列文件启动web服务
#tensorboard --logdir="序列化文件目录"tensorboard --logdir="./tmp/summary/test"Numpy
Numpy是一个科学计算库,底层使用c++实现,并解除了Python的全局解释器锁,提高了性能,常用多维矩阵操作
多维运算
#创建ndarray类型数据arr = np.array([[[255,255,255,255,255],[255,255,255,255,255],[255,255,255,255,255]],[[255,255,255,255,255],[255,255,255,255,255],[255,255,255,255,255]],[[255,255,255,255,255],[255,255,255,255,255],[255,255,255,255,255]]])#ndarray类型可直接进行运算arr = arr/255.0#输入出计算结果print('arr',arr)线性回归
公式
y = xw + b
- x 特征值
- y 目标值
- w 权重
- b 偏置量
作用
使用特增值 目标值 推导出线性回归模型,使模型在获得一个新的特征值时,可以预测出目标值
梯度下降
使用梯度下降来优化损失函数
# tf.train.GradientDescentOptimizer(学习率).minimize(损失)tf.train.GradientDescentOptimizer(0.1).minimize(loss)梯度爆炸
在极端情况下 学习率过大,导致权重的值变得非常大 以至于溢出 出现NaN这种现象称之为梯度爆炸代码
#线性回归模型def line(): # 1 建立数据 # 创建特征数据 1个特征 100个样本 1个目标 x = tf.random_normal([100, 1], mean=1.75, stddev=0.5, name='x') # 真实值 假设 矩阵相乘 必须是矩阵 y_true = tf.matmul(x, [[0.7]]) + 0.8 # 2 建立线性回归模型 1个特征 1个权重 1个偏置量 y=xw+b # 随机给一个权重和偏置 然后在当前状态下优化 # 随机建立权重 需要相乘 所以建立一个1行1列的矩阵 trainable字段默认为true 当trainable为true时 优化算法可以根据优化改变此值 w = tf.Variable(tf.random_normal([1, 1]),name='w',trainable=True) # 建立偏置 因为相加所以可以为一个标量 b = tf.Variable(0.0) # 建立模型 当前的训练结果 输出训练好的矩阵 y_p = tf.matmul(x, w) + b # 3 建立损失函数 loss = tf.reduce_mean(tf.square(y_true - y_p)) # 优化损失函数 根据学习率和损失函数,改变Variable变量优化结果 学习率过大,可能引起数据指数级增长,产生梯度爆炸 train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss) # 初始化变量 inita = tf.global_variables_initializer() with tf.Session() as sess: sess.run(inita) for i in range(1000): print('随机初始化权重{} 偏置{} '.format(w.eval(), b.eval())) info = sess.run(train_op) file = tf.summary.FileWriter('./tmp/summary/test/', graph=sess.graph)if __name__ == '__main__': line()朴素贝叶斯算法
先决条件
- 特征独立
联合概率
P(A,B) = P(A)P(B)
条件概率
P(A|B) = P(A1|B)P(A2|B)