

背景
我们知道,如果在Kubernetes中支持GPU设备调度,需要做如下的工作:
-
节点上安装nvidia驱动
-
节点上安装nvidia-docker
-
集群部署gpu device plugin,用于为调度到该节点的pod分配GPU设备。
除此之外,如果你需要监控集群GPU资源使用情况,你可能还需要安装DCCM exporter结合Prometheus输出GPU资源监控信息。
要安装和管理这么多的组件,对于运维人员来说压力不小。基于此,NVIDIA开源了一款叫NVIDIA GPU Operator的工具,该工具基于Operator Framework实现,用于自动化管理上面我们提到的这些组件。
NVIDIA GPU Operator有以下的组件构成:
-
安装nvidia driver的组件
-
安装nvidia container toolkit的组件
-
安装nvidia devcie plugin的组件
-
安装nvidia dcgm exporter组件
-
安装gpu feature discovery组件
本系列文章不打算一上来就开始讲NVIDIA GPU Operator,而是先把各个组件的安装详细的分析一下,然后手动安装这些组件,最后再来分析NVIDIA GPU Operator就比较简单了。
在本篇文章中,我们将介绍NVIDIA GPU Operator安装NVIDIA DCGM Exporter的原理。
DCGM Exporter简介
DCGM Exporter是一个用golang编写的收集节点上GPU信息(比如GPU卡的利用率、卡温度、显存使用情况等)的工具,结合Prometheus和Grafana可以提供丰富的仪表大盘。
从1.13开始,kubelet通过/var/lib/kubelet/pod-resources下的Unix套接字来提供pod资源查询服务,dcgm-exporter可以访问/var/lib/kubelet/pod-resources/下的套接字服务查询为每个pod分配的GPU设备,然后将GPU的pod信息附加到收集的度量中。
DCGM Exporter服务在每个节点上都存在一个,当Prometheus使用拉数据这种模式时,每隔一段时间(用户可设置时间间隔)就访问该节点GCGM Exporter的服务获取该节点GPU相关指标,然后存入的Prometheus的数据库中,grafana每隔一段时间(用户可设置时间间隔)从Prometheus数据库中拿取该节点GPU指标,然后在浏览器中通过各种仪表盘展示出来。
k8s集群节点安装DCGM Exporter
接下来演示一下如何在集群中安装DCGM Exporter。
前提条件
在执行安装操作前,你需要确认以下的条件是否满足:
-
k8s集群的版本 > 1.8。
-
集群中的GPU节点已经安装了GPU驱动,如果没有安装驱动,请参考本系列文章《NVIDIA GPU Operator分析一:NVIDIA驱动安装》。
-
集群中的GPU节点已经安装NVIDIA Container Toolkit,如果没有安装,请参考本系列文章《NVIDIA GPU Operator分析二:NVIDIA Container Toolkit安装》。
-
集群中的GPU节点已经安装NVIDIA Device Plugin,如果没有安装,请参考本系列文章《NVIDIA GPU Operator分析三:NVIDIA Device Plugin安装》。
安装DCGM Exporter
1.下载gpu-operator源码。
$ git clone -b 1.6.2 https://github.com/NVIDIA/gpu-operator.git
$ cd gpu-operator
$ export GPU_OPERATOR=$(pwd) 2.确认节点已经打了标签nvidia.com/gpu.present=true。
$ kubectl get nodes -L nvidia.com/gpu.present
NAME STATUS ROLES AGE VERSION GPU.PRESENT
cn-beijing.192.168.8.44 Ready <none> 13d v1.16.9-aliyun.1 true
cn-beijing.192.168.8.45 Ready <none> 13d v1.16.9-aliyun.1 true
cn-beijing.192.168.8.46 Ready <none> 13d v1.16.9-aliyun.1 true
cn-beijing.192.168.9.159 Ready master 13d v1.16.9-aliyun.1
cn-beijing.192.168.9.160 Ready master 13d v1.16.9-aliyun.1
cn-beijing.192.168.9.161 Ready master 13d v1.16.9-aliyun.13.修改assets/state-monitoring/0300_rolebinding.yaml,注释两个字段,否则无法提交:
-
将userNames这一行和其后面的一行注释。
#userNames:
#- system:serviceaccount:gpu-operator:nvidia-device-plugin-
将roleRef.namespace这一行注释。
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: nvidia-device-plugin
# namespace: gpu-operator-resources4.修改assets/state-monitoring/0900_daemonset.yaml,补充镜像名称。
-
修改initContainers中toolkit-validation的镜像名称为nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda10.2
initContainers:
- name: toolkit-validation
image: "nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda10.2"
command: ['sh', '-c']-
修改containers中nvidia-dcgm-exporter的镜像名称为nvcr.io/nvidia/k8s/dcgm-exporter:2.1.4-2.2.0-ubuntu20.04
containers:
- image: "nvcr.io/nvidia/k8s/dcgm-exporter:2.1.4-2.2.0-ubuntu20.04"
name: nvidia-dcgm-exporter5.部署DCGM Exporter。
$ cd assets/state-monitoring
$ rm -rf *openshift*
$ kubectl apply -f ./6.查看pod是否处于Running。
$ kubectl get po -n gpu-operator-resources -l app=nvidia-dcgm-exporter
NAME READY STATUS RESTARTS AGE
nvidia-dcgm-exporter-ff6zp 1/1 Running 0 3m31s
nvidia-dcgm-exporter-tk7xk 1/1 Running 0 3m31s
nvidia-dcgm-exporter-zdfg6 1/1 Running 0 3m31s7.获取nvidia-dcgm-exporter服务监听的端口。
$ kubectl get svc -n gpu-operator-resources nvidia-dcgm-exporter -o yaml
apiVersion: v1
kind: Service
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"v1","kind":"Service","metadata":{"annotations":{"prometheus.io/scrape":"true"},"labels":{"app":"nvidia-dcgm-exporter"},"name":"nvidia-dcgm-exporter","namespace":"gpu-operator-resources"},"spec":{"ports":[{"name":"gpu-metrics","port":9400,"protocol":"TCP","targetPort":9400}],"selector":{"app":"nvidia-dcgm-exporter"}}}
prometheus.io/scrape: "true"
creationTimestamp: "2021-03-26T09:39:01Z"
labels:
app: nvidia-dcgm-exporter
name: nvidia-dcgm-exporter
namespace: gpu-operator-resources
resourceVersion: "5634508"
selfLink: /api/v1/namespaces/gpu-operator-resources/services/nvidia-dcgm-exporter
uid: 55b81b2a-32a6-4a97-b75a-ad318a9443fd
spec:
clusterIP: 10.51.129.82
ports:
- name: gpu-metrics
port: 9400
protocol: TCP
targetPort: 9400
selector:
app: nvidia-dcgm-exporter
sessionAffinity: None
type: ClusterIP
status:
loadBalancer: {}可以看到,服务监听的端口为9400,端口名称为gpu-metrics。
配置ServiceMonitor
1.部署ServiceMonitor(需要创建一个文件servicemonitor.yaml),用于Prometheus找到节点上dcgm-exporter服务监听的端口,然后访问dcgm-exporter。
$ cat servicemonitor.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: nvidia-dcgm-exporter
labels:
app: nvidia-dcgm-exporter
namespace: gpu-operator-resources
spec:
selector:
matchLabels:
app: nvidia-dcgm-exporter
namespaceSelector:
matchNames:
- gpu-operator-resources
# any: true
endpoints:
- port: gpu-metrics # 此处填写步骤7获得的端口名称,即gpu-metrics
interval: "30s" # 表示prometheus多长时间访问一次dcgm-exporter获取gpu指标。
path: /metrics2.使用kubectl部署:
$ kubectl apply -f servicemonitor.yaml在grafana中安装dashboard
1.从https://grafana.com/grafana/dashboards/12239下载dashboard,点击界面右面的“Download JSON”进行下载,文件名称为nvidia-dcgm-exporter-dashboard_rev1.json。
2.点击“+” -> Import导入nvidia-dcgm-exporter-dashboard_rev1.json。

导入时需要选择数据源(来自哪个集群)。
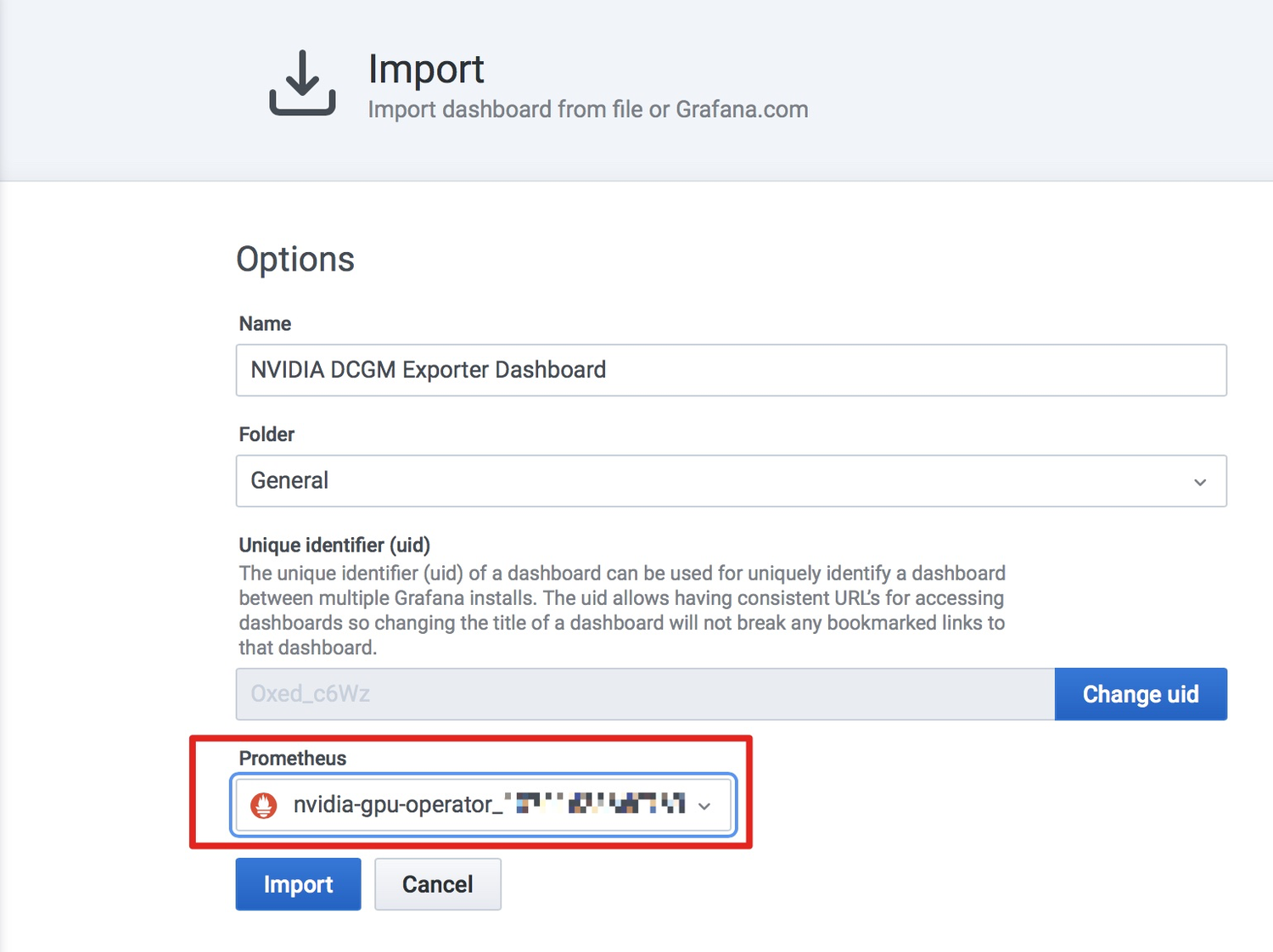
3.导入后效果如图。
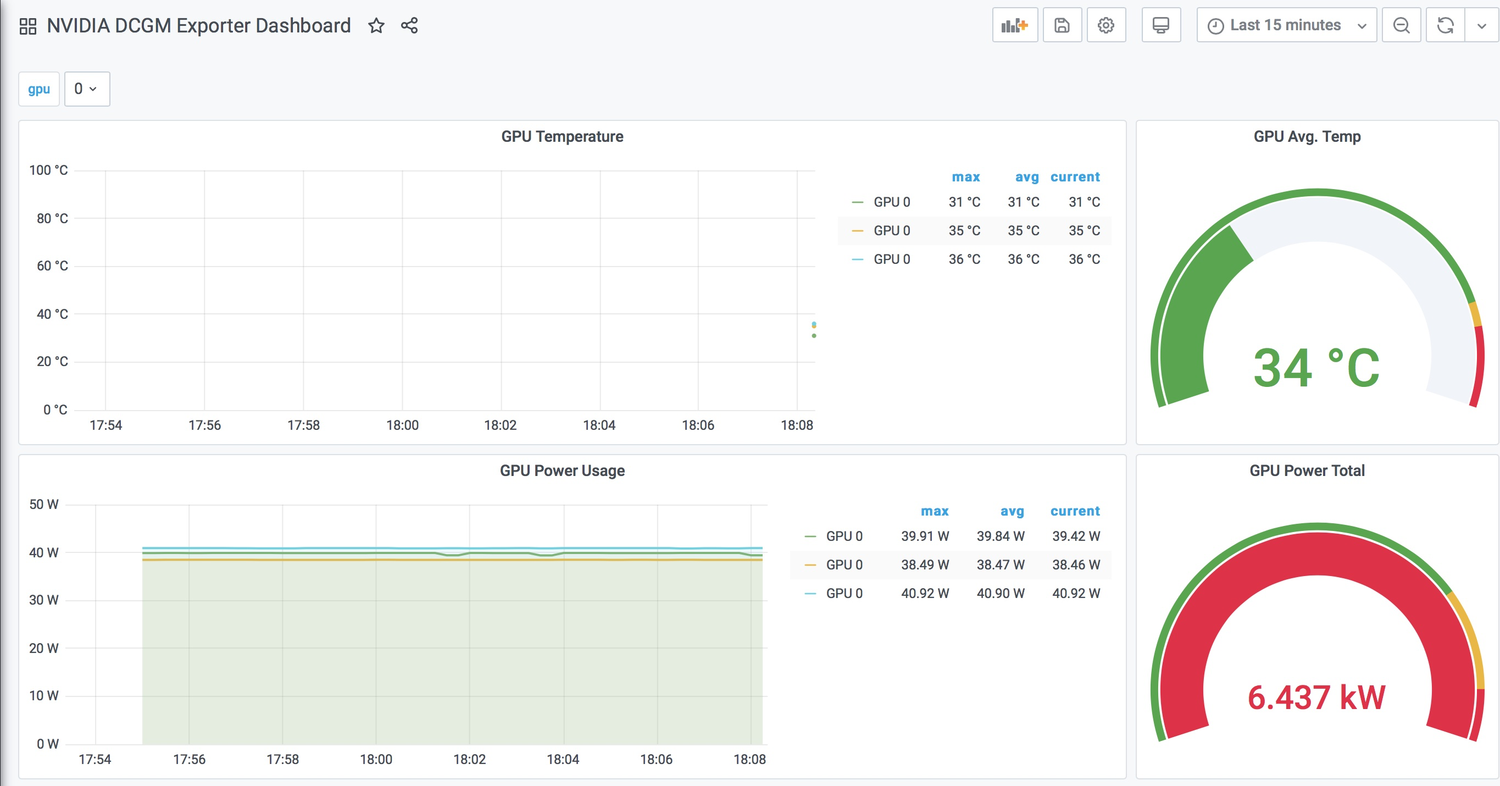
验证
当监控大盘安装完成后,可以通过提交一个任务查看监控是否有效。
1.部署一个tensorflow任务。
cat /tmp/gpu-test.yaml
apiVersion: v1
kind: Pod
metadata:
name: test-gpu
labels:
test-gpu: "true"
spec:
containers:
- name: training
image: registry.cn-beijing.aliyuncs.com/ai-samples/tensorflow:1.5.0-devel-gpu
command:
- python
- tensorflow-sample-code/tfjob/docker/mnist/main.py
- --max_steps=10000
- --data_dir=tensorflow-sample-code/data
resources:
limits:
nvidia.com/gpu: 1
workingDir: /root
restartPolicy: Never使用kubectl命令部署。
$ kubectl apply -f /tmp/gpu-test.yaml2.查看dashboard数据是否变化(注意需要开启自动刷新界面功能,点击右上角off,选择一个刷新频率,比如15s)。
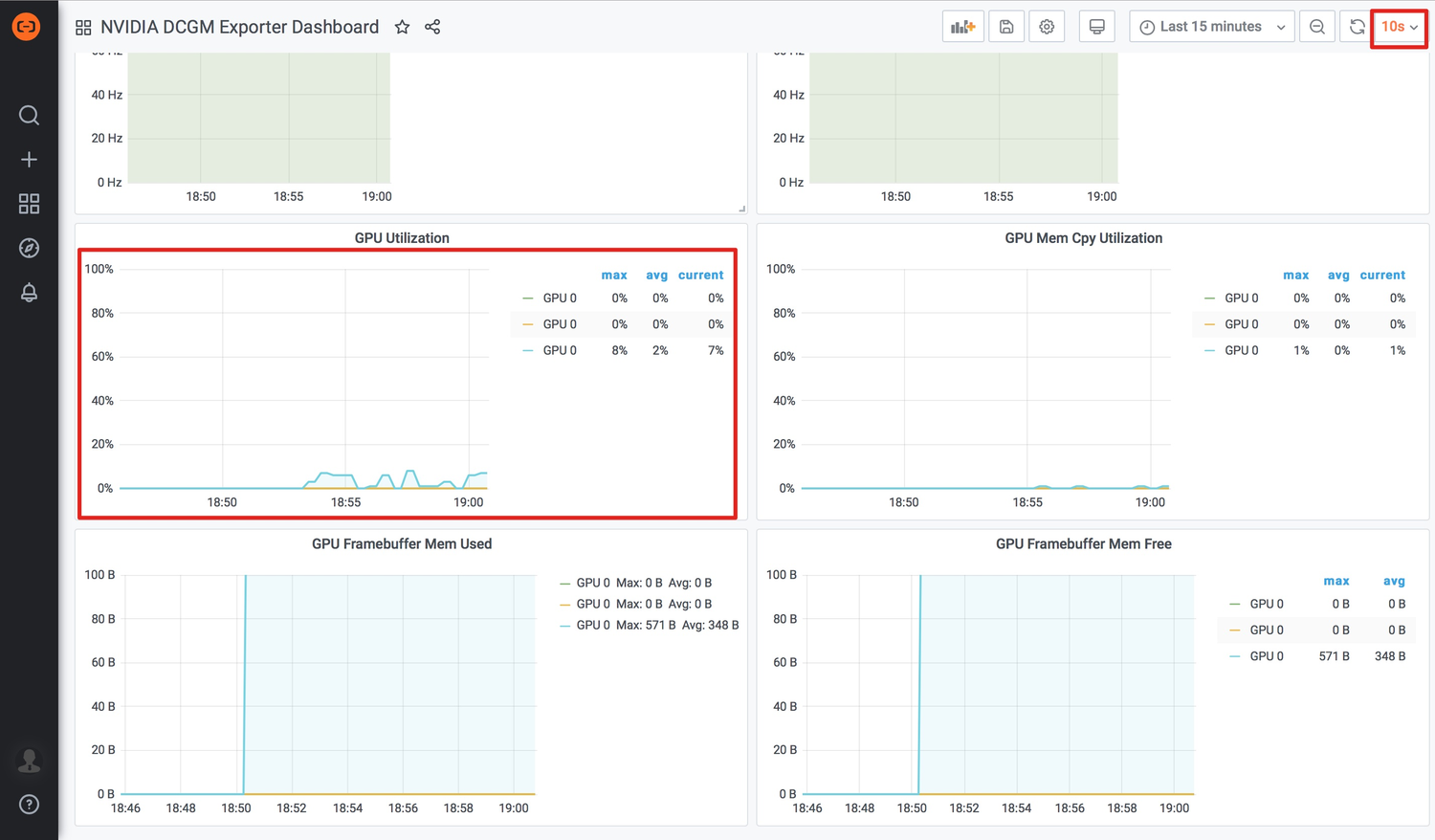
可以看到有一个GPU的利用率发生了变化。
与Arena Exporter对比
目前,NVIDIA GPU Operator提供的监控仪表盘可参考的指标还是比较简单的,比如:节点GPU使用率、节点GPU温度、每张GPU卡已使用的显存等。仪表盘还存在着如下的一些缺点:
-
无法从应用的角度观察GPU的使用情况,比如:某个Pod使用了多少GPU显存、GPU使用率是多少,或者更高级的功能是某个训练任务使用了多少GPU显存、GPU使用率是多少。
-
无法查看集群的GPU的整体使用情况,比如:集群总的GPU数、已使用GPU数、集群已使用的GPU显存等。
-
在当前的监控大盘中,GPU是用GPU Index表示的,所以你可以看到,示例集群中有三个节点,每个节点有一张GPU卡,但是在监控大盘中每块GPU的标识都是GPU0,无法区分哪张卡是属于哪个节点。
阿里云容器服务团队基于Arena实现的Arena Exporter结合Prometheus以及Grafana能够从更多的维度展示集群的GPU资源使用情况(详见:云原生AI监控):
-
集群仪表盘概览

-
节点仪表盘概览

-
训练任务仪表盘概览

总结
本篇文章首先简单介绍了DCGM Exporter,然后演示了如何部署dcgm exporter以及结合prometheus和grafana将监控指标通过仪表盘展示出来,最后简单的对比了DCGM Exporter与Arena Exporter。


