应用场景
- 阿里云的云监控已原生支持 GPU 实例,可参考:云监控实现GPU云服务器的GPU监控和报警
- 小概率场景中,GPU 卡会处于异常状态( 例如因显存校验失败而暂时不可用),导致 GPU 云监控也不可用;但此时业务系统需要感知异常情况,以便快速隔离、迁移业务,重启服务器等等
- 当业务高可用标准高、服务器数量大时,对这种小概率场景的自动监测、报警,就变得尤为重要
- 本文将介绍通过云监控的自定义监控 & OpenApi - PutCustomEvent 来做到对这种小概率事件的自动监测、报警,第一时间精准处理。示例图:


实践步骤
在云监控控制台配置自定义监控
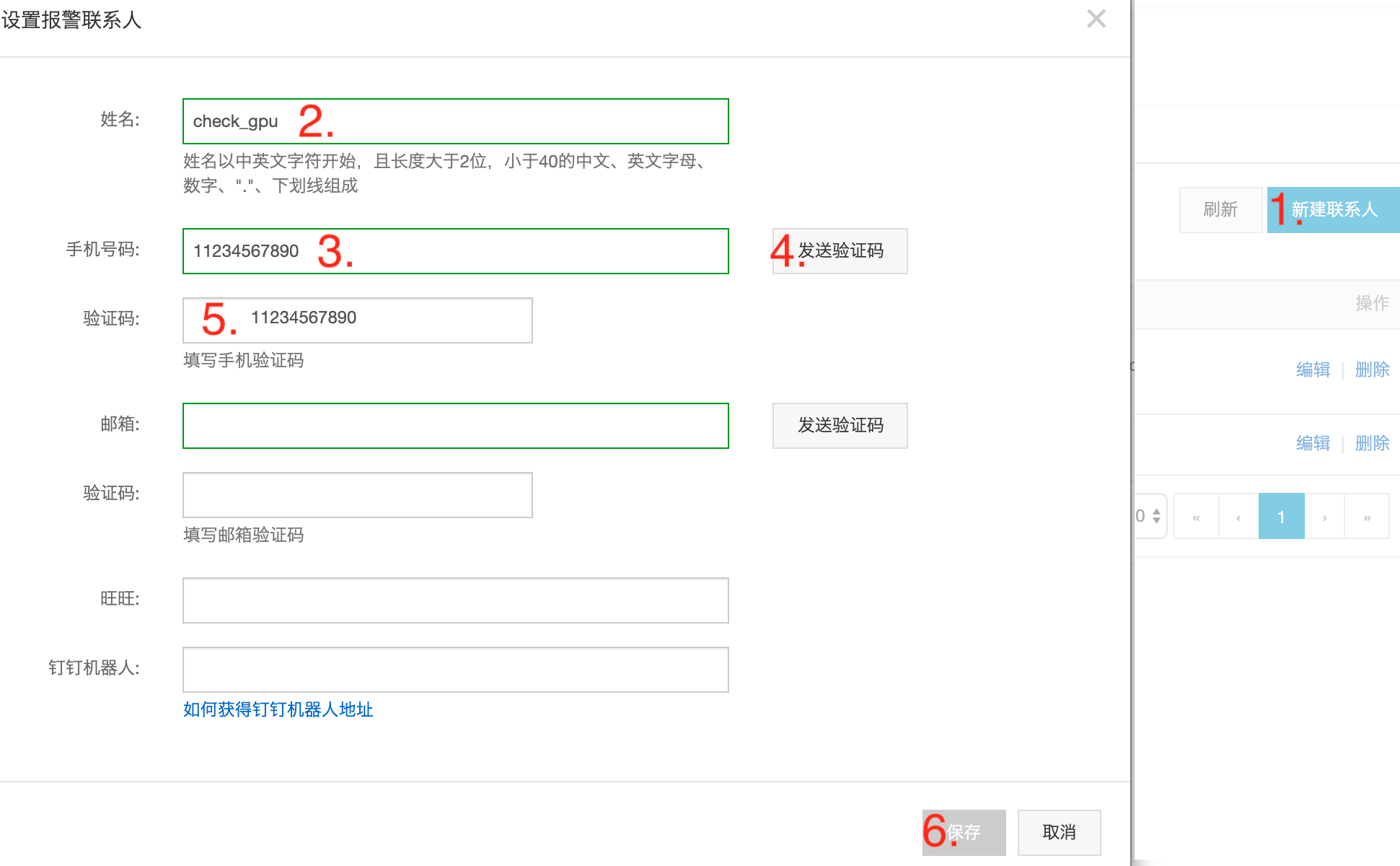
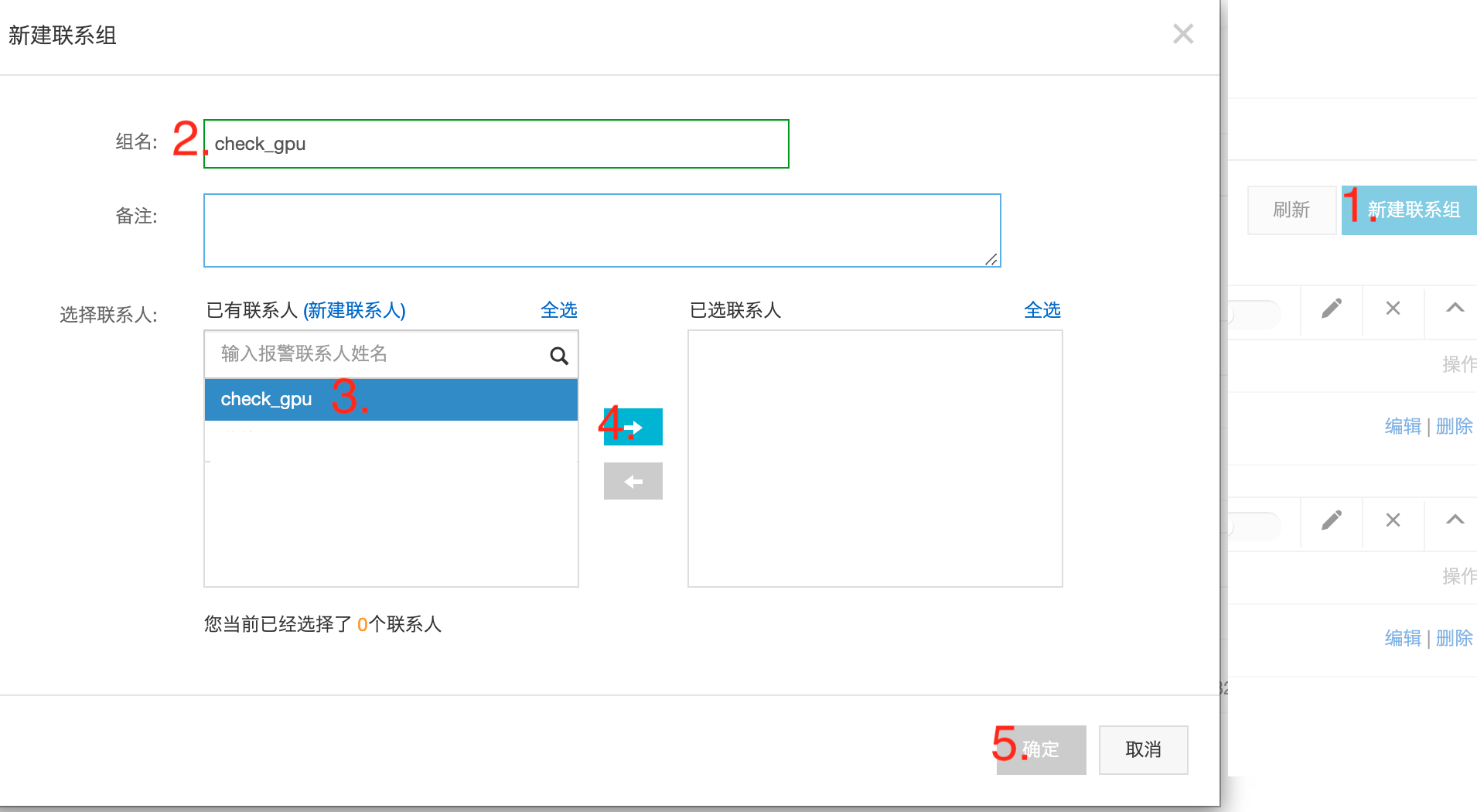
创建报警 联系人 与 联系组
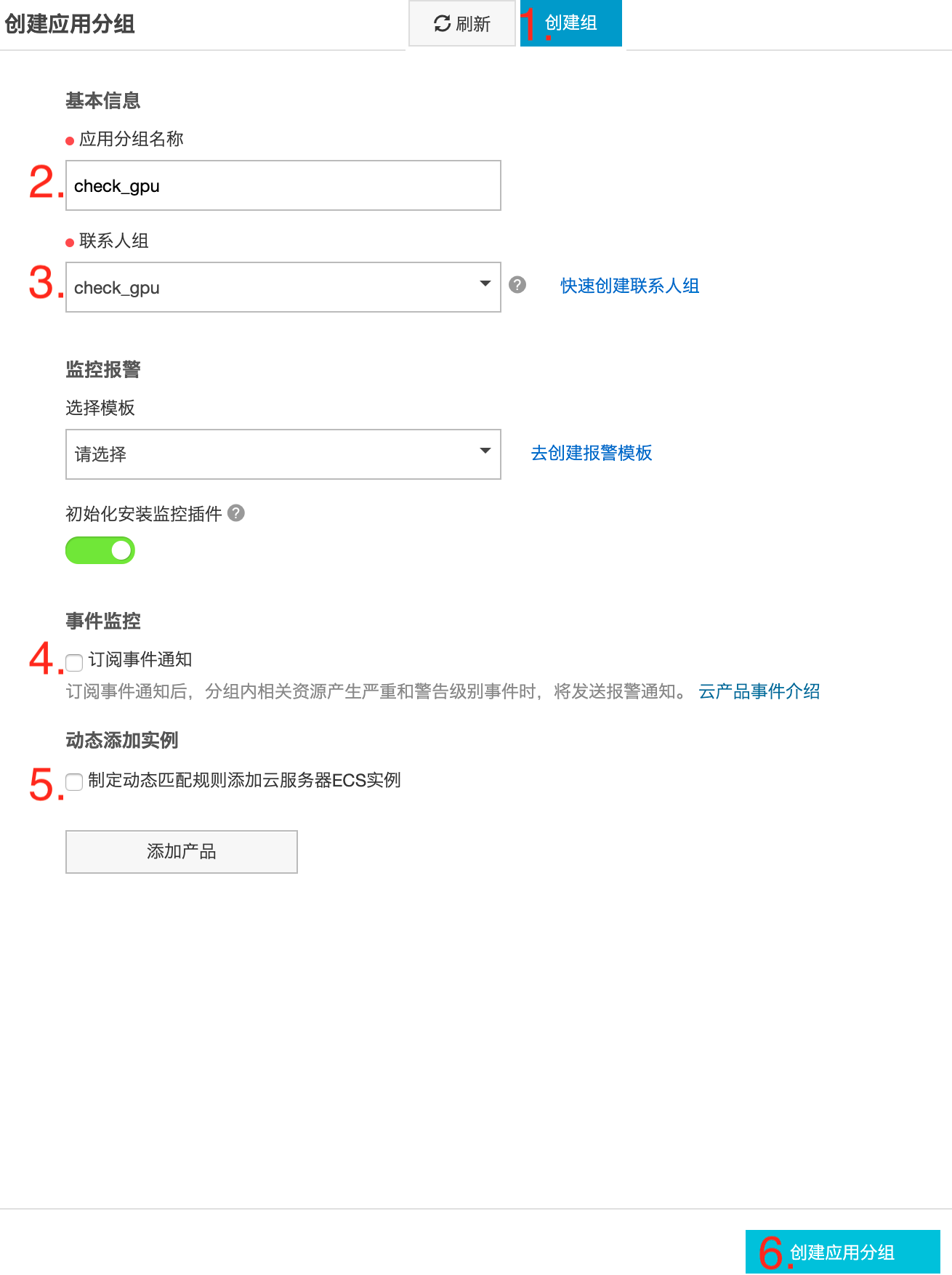
创建应用分组
- 应用分组创建后,请记录 GroupId,后续上报自定义事件时会用到。下例中 GroupId 为
10008057 


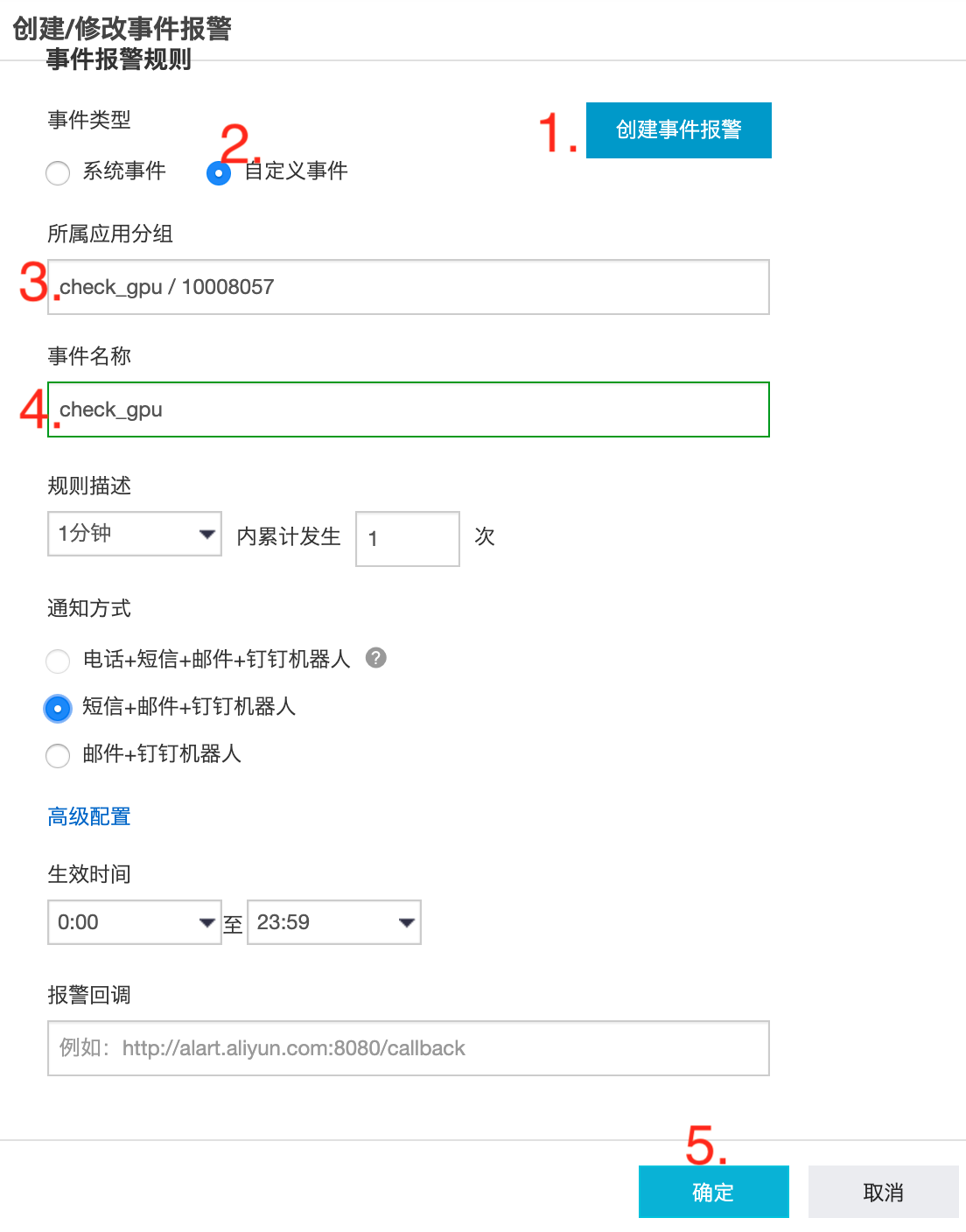
创建事件报警
- 创建完成后,查看对应的联系组、通知对象等配置是否正确



在 ECS 实例中部署监控 agent
- 需要 GPU 类型的阿里云 ECS 上操作,包括 gn / vgn / ebmgn* 规格族(gn 代表 GPU NVIDIA)
监控 agent 的 demo 脚本
- 下载 agent 脚本
wget https://gpu-nvidia.oss-cn-shanghai.aliyuncs.com/hc_check_gpu.py -O ~/hc_check_gpu.py && chmod +x ~/hc_check_gpu.py运行时,必需的参数有 3 个:AccessKeyId, AccessKeySecret, GroupId
- 其中 GroupId 为 创建应用分组 之后获得的,e.g.
... -g 10008057
- 其中 GroupId 为 创建应用分组 之后获得的,e.g.
# ./hc_check_gpu.py -h
usage:
hc_check_gpu.py -i AkIdXXX -k AkSecretXXX -g 12345678
check gpu status, send event to aliyun cloud monitor
optional arguments:
-i ACCESSKEYID
-k ACCESSKEYSECRET
-g GROUPID
...测试运行
- 下载 unittest 脚本
wget https://gpu-nvidia.oss-cn-shanghai.aliyuncs.com/hc_check_gpu_ut.sh -O ~/hc_check_gpu_ut.sh && chmod +x ~/hc_check_gpu_ut.sh- 此脚本会生成虚假的异常状况,然后上报自定义事件
AK_ID=AkIdXXX AK_SECRET=AkSecretXXX ~/hc_check_gpu_ut.sh
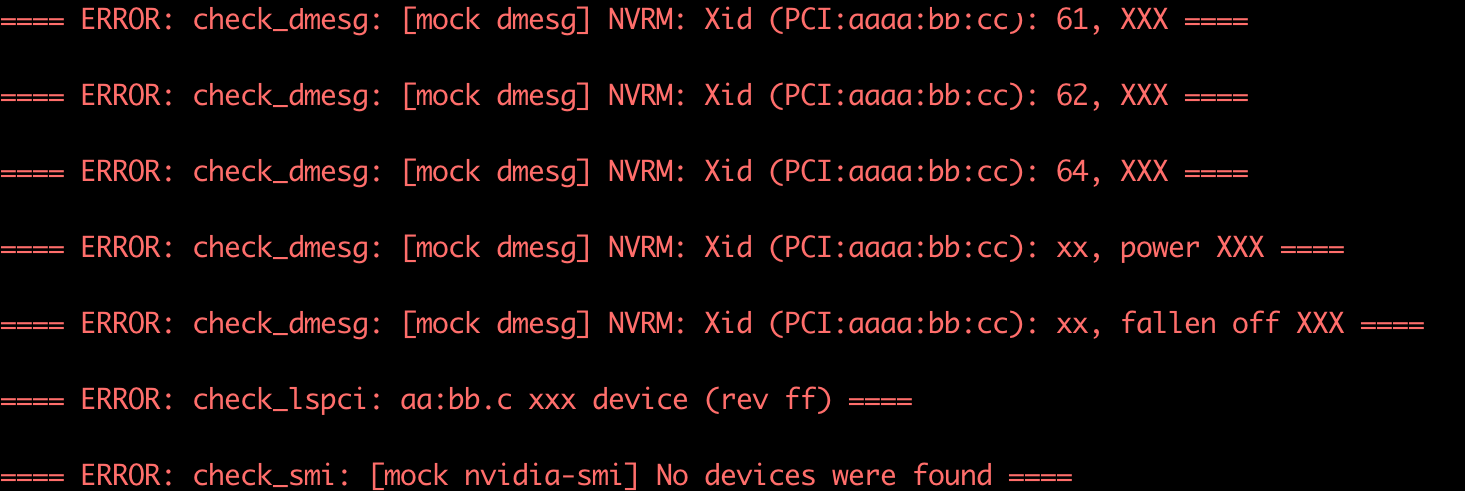
收到报警后,在控制台查看详情
- 步骤可参考本文开始的示例图
几点说明
hc_check_gpu.py默认会启动 polling loop 监察 GPU 状况,查询间隔为 1 分钟,实际部署时可按需要通过... --interval xxx更改- 实际部署时,可以让脚本在后台运行,或者安装为一个定时任务或系统服务
本章节中的
hc_check_gpu.py与hc_check_gpu_ut.sh,要求 ECS 有外网访问。如果需要在内网部署类似方案,可以将hc_check_gpu.py拆分后部署:- 在内网机器上(不可访问外网),部署 check_xxx 等采集信息的函数
- 在汇聚结点上(可访问外网),部署 putEvent 的函数
报警到钉钉群
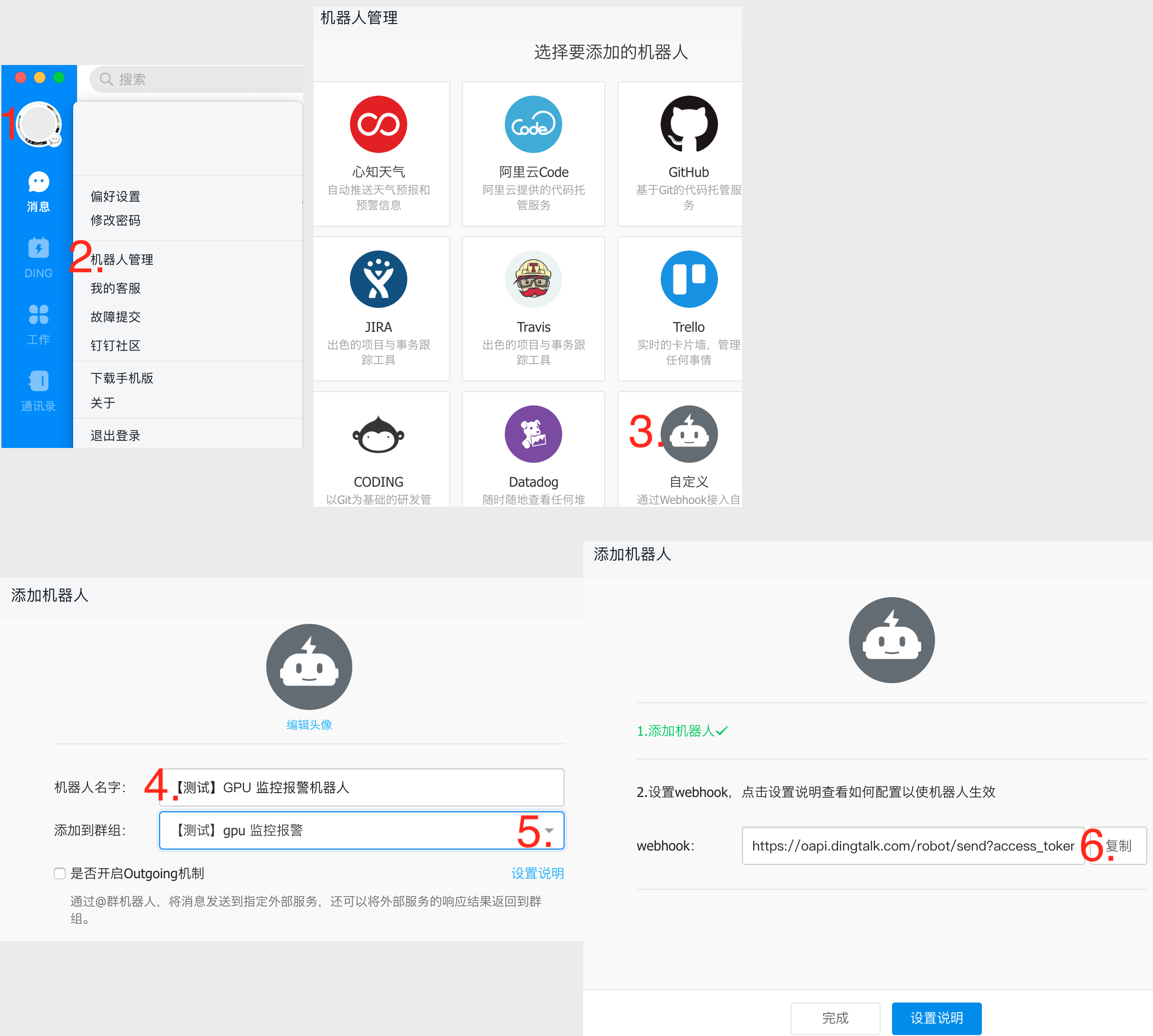
如果短信、邮件等方式还不足以满足需要、消息的展示不够详尽时,我们可以用钉钉机器人来解决这个问题。步骤简述如下,更详细的步骤可参考钉钉文档 - 使用自定义机器人
- 在钉钉中创建机器人并复制 token

同样可以用前面步骤中的 unittest 脚本来测试
AK_ID=AkIdXXX AK_SECRET=AkSecretXXX ~/hc_check_gpu_ut.sh --dingtalk https://oapi.dingtalk.com/robot/send?access_token=12345678xxxx
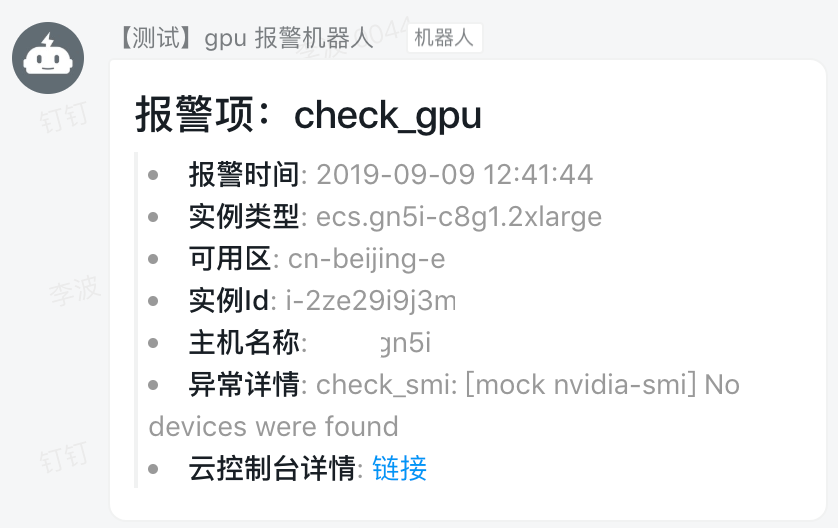
hc_check_gpu.py中钉钉报警的对应函数为putEvent中调用的dingRobot,用户同样可根据自己需要来做扩充、修改;更详细的消息定制,请参考钉钉文档 - 消息类型及数据格式- 测试效果:

总结
- 做为对 GPU 原生云监控的有力补充,本文所讨论的方案将进一步提升 GPU 的可用性、易用性,让你的 GPU 应用快上加稳!
- 本方案,除了 GPU 以外可同样适用于其它异常情况,只需根据自己的需要,裁减、扩充
hc_check_gpu.py中 check_xxx 函数即可