深度学习作为人工智能领域的一个重要分支,已经在图像识别、自然语言处理、游戏等领域取得了显著的成就。然而,深度学习模型通常包含数以百万计的参数,并且需要大量的计算资源来进行训练。传统的CPU计算在处理这些复杂的模型时往往会遇到性能瓶颈。幸运的是,GPU(图形处理单元)由于其并行处理能力,成为了加速深度学习训练和推理的理想选择。TensorFlow作为一个流行的深度学习框架,提供了对GPU加速的原生支持,使得开发者能够显著提升模型的性能。
一、GPU加速的原理
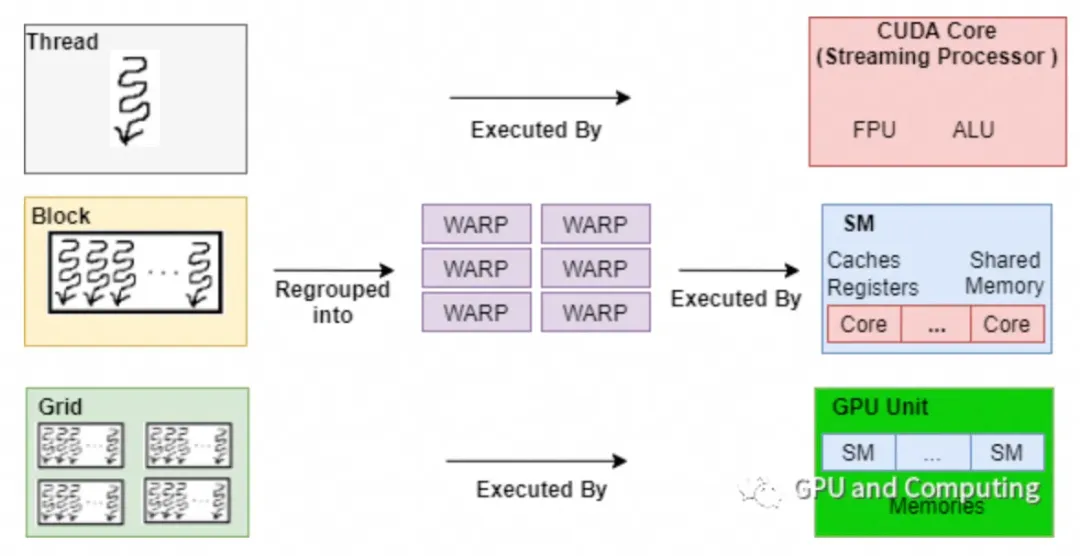
GPU最初设计用于处理图形和视频渲染,这些任务通常需要大量的并行计算。例如,在渲染一个场景时,GPU需要同时处理成千上万个像素点。这种并行性使得GPU在执行深度学习中的矩阵运算时表现出色。深度学习中的许多操作,如卷积、池化和激活函数,都可以表示为矩阵乘法,这些操作可以并行地在GPU上执行,从而大幅提高计算效率。
二、TensorFlow中的GPU支持
TensorFlow通过使用CUDA(Compute Unified Device Architecture)和cuDNN(CUDA Deep Neural Network library)库来实现对GPU的支持。CUDA是NVIDIA推出的一个并行计算平台和API模型,它允许开发者使用NVIDIA的GPU进行通用计算。cuDNN是专门为深度神经网络设计的CUDA库,提供了高度优化的常用深度学习操作函数。
2.1 启用GPU支持
要在TensorFlow中启用GPU支持,首先需要确保你的系统上安装了NVIDIA的GPU,并且安装了CUDA和cuDNN。然后,可以通过以下简单的代码来指定TensorFlow使用GPU:
import tensorflow as tf
# 指定GPU设备
gpus = tf.config.experimental.list_physical_devices('GPU')
if gpus:
try:
# 设置GPU内存增长
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
except RuntimeError as e:
# 打印错误信息
print(e)
三、GPU加速的实际效果
使用GPU加速可以显著减少深度学习模型的训练时间。例如,对于一些大型的卷积神经网络,使用GPU可以将训练时间从数天减少到几小时。此外,GPU加速还可以使得模型训练更加灵活,允许研究人员尝试更大、更复杂的模型,以及更多的数据集。
四、GPU加速的注意事项
虽然GPU加速带来了显著的性能提升,但在使用过程中也需要注意以下几点:
- 成本:高性能的GPU通常价格昂贵,而且需要额外的电源和散热设备。
- 内存限制:GPU的内存有限,对于非常大的模型或数据集,可能需要使用模型并行或数据并行的策略来适应内存限制。
- 编程复杂性:虽然TensorFlow提供了对GPU加速的易用接口,但并行计算的调试和优化仍然比CPU计算更为复杂。
五、总结
GPU加速为深度学习的发展提供了强大的动力。TensorFlow的GPU支持使得开发者可以轻松地利用GPU的并行计算能力,从而大幅提升模型的训练和推理性能。随着深度学习技术的不断进步,GPU将继续在这一领域扮演重要角色。同时,我们也可以期待未来会有更多高效、经济的硬件解决方案出现,以满足日益增长的计算需求。