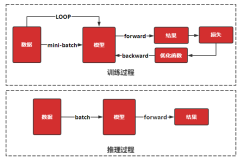
关于微软.net4.0推出的并行计算框架 还没深入了解
有兴趣的同学可以参考下http://bitfan.blog.51cto.com/907048/200199系列博文
不过发表下个人的观点 微软.NET 4.0中引入的并行扩展(包括任务并行库TPL和PLINQ)开发技术基于cpu。
从应用领域上来说CPU擅长处理不规则数据结构以及递归算法、分支密集型代码和单线程程序。这类程序任务拥有复杂的指令调度、循环、分支、逻辑判断以及执行等步骤。例如,操作系统、文字处理等,而GPU擅于处理规则数据结构。例如,光影处理,游戏显像等。从微架构上看,CPU和GPU看起来完全不是按照相同的设计思路设计的,当代CPU的微架构是按照兼顾“指令并行执行”和“数据并行运算”的思路而设计,就是要兼顾程序执行和数据运算的并行性、通用性以及它们的平衡性。GPU的微架构就是面向适合于矩阵类型的数值计算而设计的,大量重复设计的计算单元,这类计算可以分成众多独立的数值计算——大量数值运算的线程,而且数据之间没有像程序执行的那种逻辑关联性。
不过 微软的东西毕竟推广好 容易上手 开发方便 嘿嘿。
补充一下,单纯的论计算,.net 4.0中的性能肯定不如cuda,不过cuda基于gpu和显存,在传统的业务系统中可用性不是很大,用来作为底层的支撑模块还是蛮好的,至于如何选择最佳的方案要看项目的实际环境和需求了。
本文转自 熬夜的虫子 51CTO博客,原文链接:http://blog.51cto.com/dubing/712435