学习使用 R 的 twitteR 和 leaflet 包, 你就可以把任何话题的推文定位画在地图上。
当我开始学习 R ,我也需要学习如何出于研究的目的地收集推特数据并对其进行映射。尽管网上关于这个话题的信息很多,但我发觉难以理解什么与收集并映射推特数据相关。我不仅是个 R 新手,而且对各种教程中技术名词不熟悉。但尽管困难重重,我成功了!在这个教程里,我将以一种新手程序员都能看懂的方式来攻略如何收集推特数据并将至展现在地图中。
创建应用程序
如果你没有推特帐号,首先你需要 注册一个。然后,到 apps.twitter.com 创建一个允许你收集推特数据的应用程序。别担心,创建应用程序极其简单。你创建的应用程序会与推特应用程序接口(API)相连。 想象 API 是一个多功能电子个人助手。你可以使用 API 让其它程序帮你做事。这样一来,你可以接入推特 API 令其收集数据。只需确保不要请求太多,因为推特数据请求次数是有限制 的。
收集推文有两个可用的 API 。你若想做一次性的推文收集,那么使用 REST API. 若是想在特定时间内持续收集,可以用 streaming API。教程中我主要使用 REST API。
创建应用程序之后,前往 Keys and Access Tokens 标签。你需要 Consumer Key (API key)、 Consumer Secret (API secret)、 Access Token 和 Access Token Secret 才能在 R 中访问你的应用程序。
收集推特数据
下一步是打开 R 准备写代码。对于初学者,我推荐使用 RStudio,这是 R 的集成开发环境 (IDE) 。我发现 RStudio 在解决问题和测试代码时很实用。 R 有访问该 REST API 的包叫 twitteR。
打开 RStudio 并新建 RScript。做好这些之后,你需要安装和加载 twitteR 包:
- install.packages("twitteR")
- #安装 TwitteR
- library (twitteR)
- #载入 TwitteR
安装并载入 twitteR 包之后,你得输入上文提及的应用程序的 API 信息:
- api_key <- ""
- #在引号内放入你的 API key
- api_secret <- ""
- #在引号内放入你的 API secret token
- token <- ""
- #在引号内放入你的 token
- token_secret <- ""
- #在引号内放入你的 token secret
接下来,连接推特访问 API:
- setup_twitter_oauth(api_key, api_secret, token, token_secret)
我们来试试让推特搜索有关社区花园和农夫市场:
- tweets <- searchTwitter("community garden OR #communitygarden OR farmers market OR #farmersmarket", n = 200, lang = "en")
这个代码意思是搜索前 200 篇 (n = 200) 英文 (lang = "en") 的推文, 包括关键词 community garden 或 farmers market 或任何提及这些关键词的话题标签。
推特搜索完成之后,在数据框中保存你的结果:
- tweets.df <-twListToDF(tweets)
为了用推文创建地图,你需要收集的导出为 .csv 文件:
- write.csv(tweets.df, "C:\Users\YourName\Documents\ApptoMap\tweets.csv")
- #an example of a file extension of the folder in which you want to save the .csv file.
运行前确保 R 代码已保存然后继续进行下一步。.
生成地图
现在你有了可以展示在地图上的数据。在此教程中,我们将用一个 R 包 Leaflet 做一个基本的应用程序,这是一个生成交互式地图的热门 JavaScript 库。 Leaflet 使用 magrittr 管道运算符 (%>%), 因为其语法自然,易于写代码。刚接触可能有点奇怪,但它确实降低了写代码的工作量。
为了清晰起见,在 RStudio 打开一个新的 R 脚本安装这些包:
- install.packages("leaflet")
- install.packages("maps")
- library(leaflet)
- library(maps)
现在需要一个路径让 Leaflet 访问你的数据:
- read.csv("C:\Users\YourName\Documents\ApptoMap\tweets.csv", stringsAsFactors = FALSE)
stringAsFactors = FALSE 意思是保留信息,不将它转化成 factors。 (想了解 factors,读这篇文章"stringsAsFactors: An unauthorized biography", 作者 Roger Peng)
是时候制作你的 Leaflet 地图了。我们将使用 OpenStreetMap基本地图来做你的地图:
- m <- leaflet(mymap) %>% addTiles()
我们在基本地图上加个圈。对于 lng 和 lat,输入包含推文的经纬度的列名,并在前面加个~。 ~longitude 和 ~latitude 指向你的 .csv 文件中与列名:
- m %>% addCircles(lng = ~longitude, lat = ~latitude, popup = mymap$type, weight = 8, radius = 40, color = "#fb3004", stroke = TRUE, fillOpacity = 0.8)
运行你的代码。会弹出网页浏览器并展示你的地图。这是我前面收集的推文的地图:
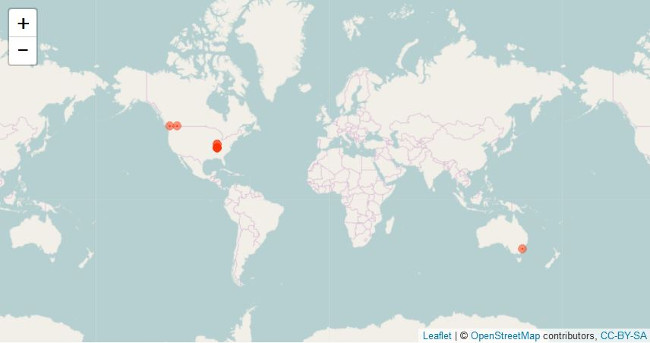
推文定位地图
带定位的推文地图,使用了 Leaflet 和 OpenStreetMap CC-BY-SA
虽然你可能会对地图上的图文数量如此之小感到惊奇,通常只有 1% 的推文记录了地理编码。我收集了总数为 366 的推文,但只有 10(大概总推文的 3%)是记录了地理编码的。如果你为得到记录了地理编码的推文而困扰,改变搜索关键词看看能不能得到更好的结果。
总结
对于初学者,把以上所有碎片结合起来,从推特数据生成一个 Leaflet 地图可能很艰难。 这个教程基于我完成这个任务的经验,我希望它能让你的学习过程变得更轻松。
(题图:琼斯·贝克. CC BY-SA 4.0. 来源: Cloud, Globe. Both CC0.)
作者:Dorris Scott
来源:51CTO