一、业务背景
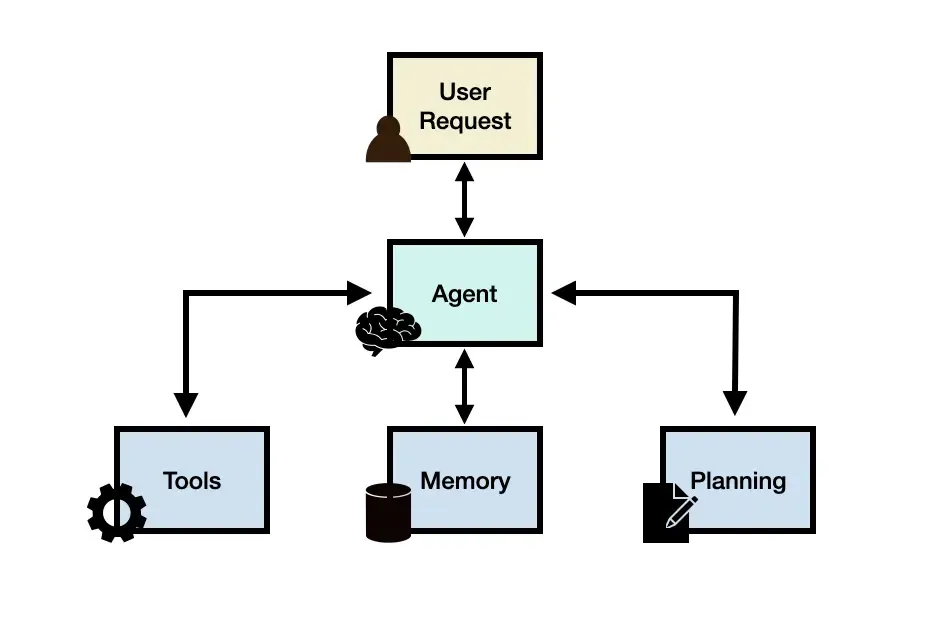
在AI技术重构软件工程范式的新阶段,大模型技术正推动编程模式从"工具辅助型"向"需求驱动型"的历史性跨越。我们期待未来蚂蚁安全与智能实验室所有提交到代码库的代码中,大部分是由codefuse自动生成的, 这就对codefuse在原有代码补全以及AI partner能力的基础上,提出了更高的要求,希望把codefuse按“AI需求执行者”的目标构建,让AI直接理解自然语言需求,自主完成需求解析、任务拆解、跨仓库的文件搜索、代码生成、相应测试代码生成等全流程动作。
二、目标
1. 业务需求实现从需求到代码的端到端生成。
2. 大安全域提交到代码库的代码由AI生成的占比为60%。
3. 实现企业级代码规范和要求,实现风险左移:需求拆解时自动符合变更三板斧,符合适合大安全的设计要求(如发布功能必须有散列设计,查询必须有limit设计等)。
三、面临的主要挑战
a. 已有的复杂的代码资产
• 已有代码资产复杂性:已有的代码仓库都是规模达数十万行代码量级的,呈现典型"天书式"架构特征,包含大量废弃代码碎片、多版本逻辑共存的兼容方案及补丁式代码堆积,形成复杂的技术债网络。
• 智能解析瓶颈:目前的代码库,实证新入职开发人员在无资深导师指导下,难以独立读懂uctfront项目核心逻辑,而现有AI编程系统受限于代码表面特征统计,对跨文件依赖关系、隐式业务规则等深层逻辑的识别准确率不足。
b. 业务复杂,需求理解困难
安全业务背景知识庞杂,经历十几年的发展,很多业务规则散落,AI 只能基于现有代码统计规律,无法穿透代码表象理解业务语义, 自动对齐真实业务语义,产品功能,这就导致AI在需求理解时,模型不理解涉及到的业务背景知识,经常出现不理解“已有仓库文件”,以及无法找到需要修改的“已有代码文档”。
四、建设方案
针对以上两个问题,经过不断探索与实践,最终从以下几个模块实现最终的AICoding能力:
- 构建AICoding标准workflow,实现端到端逐步生码:围绕完整的生命研发周期,从prd出发,经过标准化系分、上下文知识扩充、需求拆解等阶段,最终结合安全自定义规则,逐步生码。
- 扩充模型上下文,增强对仓库历史知识的理解能力:将数据从业务、通用、规范等维度结构化,基于RAG和知识图谱的能力,逐步增强模型生码需要的背景知识内容。
- 沉淀流程数据,评测能力效果,不断优化AI生码质量:为了优化生码质量,不仅需要对各阶段模型能力制定评测benchmark,优化agent能力;同时将生码过程数据逐步沉淀,扩充知识库和知识图谱内容,增强知识召回能力,保证召回数据质量。
1. 建设框架

2. 扩充业务知识,增强模型能力
a. 业务知识体系化
面对庞杂的业务代码内容以及复杂的业务背景知识,需要从安全业务wiki、安全代码wiki、通识wiki、需求wiki多维度结构化补充背景知识,支撑跨仓库、跨业务链路、跨技术栈等复杂场景的生码能力。
- 安全业务wiki:涵盖各业务领域知识、风控通识和稳定性知识,确保生成的代码符合安全研发规范(如三板斧、熔断),且充分理解了安全业务语义。
- 安全仓库wiki:包括仓库级wiki、文件级wiki和调用链路wiki,提供全面的安全侧代码库知识,协助需求拆解和生码过程,快速定位需要修改/依赖的仓库代码内容。
- 通识wiki:基于研发中间件知识和全站研发通用知识,确保需求拆解和生码符合蚂蚁研发规范。
- 需求wiki:基于prd、系分和关联代码内容,构造需求和领域模型的关联背景知识,从实际需求扩充领域模型实际业务语义内容。
b. 上下文知识扩充,增强业务理解能力
ⅰ. RAG检索业务知识
对于大模型不理解特有业务场景的问题,使用业界通用方案,RAG在线检索相关的业务语义文档做代码生成的增强上下文。但是使用RAG知识库召回数据过程,会存在以下问题:
【召回准确率低】
当前RAG知识检索能力,普遍存在的召回率低问题,采用以下方式去优化:
- 提取业务实体:增加需求实体提取阶段,避免整个需求文档直接搜索召回,提升准确率。
- 增加搜索标签:针对二方包跨仓库调用场景,在需求描述时,指定需要的bundle,提升知识库召回率。
- 分应用召回:核心h1h2应用使用geamker(支持业务三元组知识图谱和向量数据库),确保召回准确率;其他应用使用grt(仅有向量数据库搜索能力),保证可用性。
【支持库存储&检索耗时成本高】
为了增强用户体验,同时考虑到大规模数据存储的成本,从以下几个角度进行多维优化:
- 优化查询流程:在知识库召回wiki过程中,剔除最后模型总结步骤,在只做文本搜索召回和倒排流程,节省98%耗时(3min->3s)。
- 精炼知识内容:只保留代码总结中涉及业务语义的部分,降低知识库的初始化解析和存储成本。
ⅱ. 知识图谱能力扩充
在实践过程中,发现现有知识库都是以markdown格式做初始召回文本,但这也会存在一个通用问题:在语义检索时只会命中md文档的某一个chunck块,导致召回结果完整性缺失。
针对此问题,使用知识图谱能力,基于“文件路径+仓库”节点索引标签,定向检索知识库召回文档,扩充wiki内容。
同时,考虑到知识图谱的存储召回耗时成本,简化图谱结构,仅保留必要的文档、仓库、bundle、需求、rpc、drm节点,剔除扩散比大的方法、属性等节点。最终在不降低语义质量前提下,将知识图谱规模从10亿+节点,简化到100万+节点。
c. 模型能力强化
除了RAG+知识图谱方式扩充背景知识外,模型自身的需求拆解和业务理解能力也需要不断增强。
- 持续预训练:基于Qwen-base model,在离线使用语料库,通过持续预训练方式,让需求拆解基模提前学习业务知识。
- 强化学习:通过强化学习手段,让需求拆解模型拆解出的子任务有三板斧和鲁棒性考虑,从而实现风险左移。整体流程如下:

- 训练语料:基于pr的codediffs,先反向生成需求list,再反向合成原始需求。其中会用LLM进行多次扩充。以及原始prd提供反向生成上下文。
- 训练方式:基于sllmworks框架,使用GRPO方式,设计多个维度奖励(输出格式、拆解任务个数、变更三板斧、鲁棒性、任务依赖准确性)增强模型拆解能力。同时利用agent提取高可用历史AAR经验,总结成关键词词库,及时更新prompt。
- 训练评测:按照手动评测 + 自动评测,阶段性评测(需求拆解评测)+ 端到端评测(生码评测)相结合的方式对后训练后的需求拆解模型进行评测。
- 应用:需求拆解后的子任务列表用于最终生码,同时还在探究在其他方向的落地(如:系分生成)。
在当前的强化学习训练过程中,我们主要面临数据质量的挑战,并已制定相应的改进思路与落地计划。
【训练集数据质量】
- 现状与做法:现阶段采用“PR → 子任务列表 → 需求”的逆向工程链路构造训练样本,能够在数量上保证数据的充足。同时对数据进行初步清洗:过滤掉代码改动行数在20以下或1000以上的PR,避免过于简单或过于复杂的样本带来的噪音与偏差;在数据生成链路中引入两轮agent进行校验与补全(第一轮用于子任务完善、第二轮用于需求完善),在一定程度上提升了样本的可用性和一致性。
- 问题与不足:自动化生成的数据仍可能存在语义偏差、场景不匹配、标签不够细致等问题;数据分布与真实生产场景不完全一致,容易导致训练过程中的偏拟合或泛化能力不足。
- 改进计划:
- 人工精标与优选:建立小规模的“黄金集”,由领域专家人工审核与精标,作为训练与评测的对照基准;对自动生成数据进行抽样复核,沉淀高质量样本。
- 分类与分层:根据实际应用场景对数据进行分类(如修复类、优化类、重构类、文档类等),并按难度分层(简单/中等/复杂),确保训练时的分布与使用时一致。
- 去重与一致性:对近似或重复样本进行去重;提升一致性与可控性。
- 动态更新与课程学习:建立数据滚动更新机制与课程式采样策略,先学易后难,逐步引入复杂场景,促进稳定收敛。
3. 标准化workflow,端到端生码
3.1 自动生成系分
【问题】
- 每个人写的系分往往格式不一,而且会缺失不少方案细节内容,如业务逻辑、多表之间的关联关系等。增加了约束规范,也就保证了细分质量,增加了AICoding的上下文信息。
- 对于高可用、稳定性等非功能性需求,在系分中往往缺失,导致拆解和生码过程为了遵循实际业务内容,需求描述内容无法完全扩充相关能力,三板斧等基本要求依旧不满足。
【方案】
- 给出统一的系分文档,扩充业务流程、状态转换、权限约束规范等必要细节。
- 使用agent自动生成标准化文档,开发人员只需介入修订,减少人工撰写成本。
# 各模块说明## 模块名## **业务实体**| 实体 | 属性及类型<br/>(默认varchar类型) | 索引键 | 字段值说明 || --- | --- | --- | --- |### **领域功能**| 领域 | 领域服务 | 领域功能 | 功能描述 | 规则约束 || --- | --- | --- | --- | --- |### **应用服务**| 服务域 | 服务接口 | 服务方法 | 方法流程描述 | 校验约束 || --- | --- | --- | --- | --- |# 业务流程与状态机说明### 状态机说明#### 实体名| 实体 | 当前状态 | 事件/操作 | 下一状态 | 校验约束 || --- | --- | --- | --- | --- |### 业务流程说明# 与其他bundle或系统的交互| 交互方 | 交互方式 | 触发时机 | 主要接口/消息 | pom信息 | 业务目的/说明 | 出入参说明 || --- | --- | --- | --- | --- | --- | --- |# 高可用相关能力| 能力 | 是否需要 | 待补充内容 || --- | --- | --- |
- 在生成标准化系分文档时,根据前置约束条件,过滤必要业务场景(如生产发布等)扩充高可用要求内容。以itask为例,在prd内容中没有满足到三板斧的监控感知、回滚、审批的要求,经过agent自动转换成标准化文档时,会补充相关能力要求和建议。
3.2 需求拆解子任务
【问题】
众所周知,上下文描述越清楚,AI生码越准确。因此,对于一个完整的模块功能,哪怕是管理时任务,也会有很很多业务细节需要实现。当把这些内容直接全部给大模型生码时,经常会出现超token,或者业务细节实现不符合预期的问题。
因此,提供供给模型生码的需求,内容越简单,功能越原子化越好。但是拆解后的子需求越简单,意味着子需求个数越多。在拆解时,需要合理定义需求的原子性和复杂度,最终需要在需求复杂度和个数之间找到平衡点,实现需求个数较少,生码质量又要相对较高。
【方案】
- 目标:将需求模块内容拆解为主要执行任务流程清单,包含详细描述和实现方案,并根据任务之间的依赖关系进行排序。
- 拆分标准:
- 确保子任务单一职责明确。
- 根据业务影响评估优先级。
- 维持与提供的业务背景知识、领域模型等的语义一致性。

拆解后需求结构(e.g):

3.3 仓储生码规范生成
【问题】
- 系统经过长期的迭代,功能复杂,对于每个目录结构已经无法简单描述。
- 不同仓库生码规范不一,单一模型无法覆盖全部场景。以itask仓库为例,管理时需要按照dal->repository->service->controller层次,且dal层同一张表,需要区分BaseDAO和业务DAO。
【方案】
利用模型和codefuse具有的仓库索引能力,增加通用指令,以现有仓储具体场景为例,初始化生码规范(.project_rule),实现不同仓库的架构兼容规范。并在后续生码过程中将该规范内容作为生码上下文约束内容。例如以下是针对实际生产itask仓库自动生成的项目规范:


3.4 分层生码
Q:为什么不按照纵向分模块拆分生码,而是横向分层生码A:1. 在系分和需求拆解阶段,已经按照模块拆分,且根据模块间依赖问题,排序生码子任务。2. 考虑到流程规范性,约束按照mvc分层生码,不仅能避免模块生码过程,模型偶尔丢失controller层代码问题,也能避免不同接口依赖同一个表或者接口、方法,导致merge冲突问题。
【问题】
- token受限:对于功能模块,在AI生码过程中,如果一次实现dal->service->controller层的生码,经常会遇到执行过程超出token限制,导致生码中断问题。
- 上下文遗忘:当在同一个会话中大篇幅生码时,模型往往会遗忘历史生码内容,导致生成大量冗余代码。
【方案】
- 固化生码指令,设计mvc三层各自的生码workflow。
- 优化生码指令,增加统一的命名规范、鲁棒性处理、可读性等质量要求。
3.5 自动review需求效果
【问题】
以管理时ai生码为例,从prd生码,哪怕是单一需求模块,也需要同时覆盖crud多个能力,mvc多层代码,开发人员cr过程无法一行行check代码,直接采纳对模型信任度还不够,风险高。
【方案】
通过自定义prompt,固化需求实现效果总结指令,从变更代码结构、功能覆盖范围、稳定性需求、代码实现方案等多维度总结,降低cr难度。

4. 评测与数据更新,持续增强能力
a. 动态更新知识库,确保数据准确性
- 针对安全代码仓库、需求每天不断变更的问题,不断沉淀最新代码和业务知识数据,基于自动化数据清洗流程,实现知识数据不断迭代演进。
- 持久化拆解流程的过程数据,保存“实际业务需求 -> 代码类”的新增/依赖/修改等关联关系,扩充知识库、知识图谱的数据,进一步优化召回准确率,同时实现了需求拆解流程的标准化。

b. 能力评测
【评测重点】
- RAG+知识图谱:评测知识召回能力
- 召回率:实际命中文件数/目标召回文件数据,目前运行时核心链路能完全召回。
- 准确率:实际命中文件数/实际召回文件总数。
- 模型训练:评测需求拆解偏好
- 总计1分,按照奖分方案,不扣分。
- 输出格式:严格按照json格式、根据需求复杂度合理规划任务列表个数。
- 业务逻辑:拆解任务列表需要满足三板斧、鲁棒性、任务依赖顺序合理等要求。

- 需求拆解能力:评测agent+上下文作用
- 拆解prompt优化效果:简单prompt vs 复杂prompt
- 拆解上下文作用:优化背景知识召回能力

- 端到端AICoding能力评测
- 评测数据覆盖标签范围
- 业务类别:业务风控相关需求、反洗钱相关需求、高可用相关需求、处罚相关需求、终端相关需求、流量风控相关需求、内容风控相关需求、其他外包小二需求。业务相关核心场景占比63%,高可用占比14%。
- 需求场景:管理时需求(MVC类型服务架构,涉及接口、Controller等)占比34%;运行时需求(纯业务逻辑实现,不涉及Cotroller接口实现)占比66%。
- 需求类别:新增、修改、新增+修改(占比77%)。
- 需求复杂度:从拆出的需求任务个数和可能实现代码行数评估。简单10%、中等50%、困难40%。
- 评测重点
- 完整性:需求是否覆盖prd文档中领域模型、业务流程和状态机相关内容,其他内容做参考。
- 一致性:需求内容是否与PRD描述的领域模型、业务流程和状态机相关内容,其他内容做参考,领域模型属性描述不完全不影响需求列表的准确性。
- 依赖合理性:需求间的依赖关系是否符合技术实现顺序。
- 覆盖范围:拆分的需求列表是否包含prd以外的内容。如果包含,对于合理的额外内容,比如线程锁、单元测试等属于正常范围的合理扩展。其他额外内容,如增加prd不涉及的接口,此类占比超过整个需求列表的20%,则视为拆解不准确。
- 鲁棒性:需求拆解过程是否考虑到包括数据、业务逻辑、安全、资源、外部依赖等各维度鲁棒性。
- 高可用能力:可监控、可灰度、可应急
五、建设进展
1. 通过AIcoding编码实际使用情况
CodeFuse 用户提交代码 AI 占比:43.25% |
全部提交代码AI占比:36.01% |
|
|


2. 生产实践效果
a. 审理平台端到端生码
项目背景:通过需求单管理模块,管理业务方的审理需求,更好地串联生产用工流程
功能说明:需求单及版本的创建、编辑、审批、上线流程,支持草稿-审批-上线的状态流转,以及每月自动触发任务量级确认与通知。
AI生码效果:AI生码近20000行,按照仓库的数据访问规范dal/repository/service/controller,实现原始系分文档->标准化系分文档->任务拆解->codefuse生码的全过程
b. 智能UI助手端到端生码
项目背景:探索大模型在质量域的提效方式之一,助力质量团队在UI自动化上达到快速编写和调试,自动保鲜提升稳定性等能力提升。为减少用户学习成本,且支持后续公开的快速扩展,采用智能体集成的方式建设智能UI助手。
功能说明:
1. 脚本管理模块基本能力:脚本创建、脚本展示、脚本刷新、脚本删除。
2. 集成antcode三方交互。
3. 非功能性需求:变更操作监控感知、异常处理等鲁棒性需求。
AI生码效果:AI生码3000+行,,代码采纳率70%+,按照仓库结构规范,实现由prd开始的端到端生码。
c. 一键接入业务二方包
目标:针对相对固定的研发范式,从面向人的编码转换成面向智能体的编码,定制化指令,增强需求生码能力。实现熔断接入/压测接入/班车接入/流量接入 等场景的AICoding生码,一键接入二方包。用户只需编写剩余业务逻辑部分。
效果:已实现在风控系统中,自动接入熔断二方包。
六、下一步规划
1、目前面临的问题:
- 当前需求迭代过程中缺乏统一的技术风险管控标准,主要依赖研发人员个体对风险规范的主观认知。这种模式导致两个典型问题:
- 治理与新增风险并存:
既有技术债务治理(如变更三板斧合规改造、AAR缺陷修复)的同时,新增业务需求仍持续产生同类风险隐患; - 防控机制不可持续:依赖研发同学意识的非标准化防控,难以保证这些技术风险管控要求在跨需求、跨团队中的一致性落地。由于亟需建立可嵌入研发流程的标准化风险防控体系,通过机制化手段确保技术风险规范在业务需求实现中自动贯彻,从根本上阻断同类问题的复发路径。
- 当前端到端的生码过程为:原始PRD或系分文档 -> 标准化系分 -> 任务拆解 -> Codefuse生码,要能持续的优化和打磨 「标准化系分」、「任务拆解」 这2个节点的能力,评测数据必不可少,而「标准化系分」、「任务拆解」无历史数据是我们面临的另一问题。
2、应对方案:
- AIcoding增强技术风险能力强化:将技术风险持续左移,在需求阶段即识别这些风险隐患,在「标准化系分阶段」,识别并扩充高可用相关能力接入的内容,经过后续拆解+生码,使需求具备高可用能力。
- 优化编码规范:将编码类的经验教训,总结为规则,并进行分类,在「标准化系分阶段」阶段 或者 生码阶段 识别并避免问题的发生。
- 数据沉淀:在推广落低过程中,不断沉淀用户数据,尤其比对交互过程中的用户修改内容,作为评测数据和评测功能点,基于此优化全流程生码能力和知识库数据。
3、持续能力增强
3.1 、能力研发规划

鸣谢
感谢CodeFuse团队在日常能力需求快速迭代上大力合作和支持以及日常答疑指导。
感谢GRT和GeaMaker团队在模型上下文扩充方案上的指导和支持。
来源 | 阿里云开发者公众号
作者 | 素舒