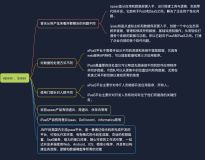
spanner的前身是big table,让我们先来看看big table这个老子的方方面面,然后再来看看儿子spanner为啥一出世就吸引了全球技术人员的眼球。
2006年,google 发表了big table [1]的文章,为什么要做big table,下面有一个简短的总结[2]:

就是一个问题:数据太多,访问量太大,规模问题出现。规模是问题的源泉,是后续故事的核心,在此基础上才碰到了动态schema(semi-structure带来的问题,比如big table支持的schema change),全局可用,数据一致读写等问题。
big table的数据模型是 <row, column, timestamp> -> cell content ,每个cell都是一个三维空间中的一个点,每个维度都是动态可配置的(行可以随意增加,列可以随意增加,时间序列可以随意增加),非常灵活自由。
big table 的系统架构,解决数据和访问在一个cluster内部如何分配:将数据分片,每台tablet server load 若干分片,有一个核心节点master来做全局信息同步。

在big table 论文发布之后,big table一直在改进,主要是致力于提供更好的scalability;加入了跨cluster(一般是跨机房的cluster)的数据异步复制以及Coprocessor(HBase的coprocess应该也是从这里引入)。
google 大哥在成长,工程师需要更好用的结构化存储,big table 看来在以下几个方面做的不够好:
1. 分布式transaction:比如A给B发送了一个消息,那么A的发件箱和B的收件箱应该同时有一封信件,这是一个完整的事务,应该遵循事务的ACID原则,但是big table无法支持,其只支持single-row-transactions。这也也好理解,在啥都没有的情况下,big table的出世就足以让人兴奋,谁会为分布式transaction伤脑筋呢?不过日子越过越好,人们的要求也越来越高,这件事情就逃避不掉了。
2. 强一致性数据同步:即使某些用户不要求分布式transaction,那么强一致性也是希望提供的,也就是说在数据没有同时主、备集群写入之前,不要返回client成功的消息。应用有此需求也容易理解,如果你主集群写完就返回,然后主集群挂了,我最新的数据不是丢了吗?
3. SQL语言支持:大家都很懒
4. 全球负载均衡:负载均衡是个很大的话题,包括存储负载(存储空间全球数据中心共享)、调度负载(在全球数据中心内平衡CPU/MEM利用)、网络负载(在全球数据中心内平衡网络流量)、距离负载(让数据紧贴应用进行全球移动)
不得不说,系统真的是一步步进步的,人们的需求真的是一步步提高的,如果不是big table做出来,这些问题估计没人敢想。也正是因为这些问题的存在,Spanner[3]横空出世。
看看spanner解决了哪些问题:
Spanner is Google’s scalable, multi-version, globally distributed, and synchronously-replicated database
Spanner’s main focus is managing cross-datacenter replicated data, providing externally consistent [16] reads and writes, and
globally-consistent reads across the database.
最核心的是两点:
1. 分布式transaction
2. 全球自动化负载均衡(细粒度切分和全球数据复制都是为这个目的服务的)
Spanner 体系架构:
A Spanner deployment is called a universe. 全球只有三个spanner,分别用于测试、开发/生产(VS dark launching from Facebook ?)和生产。
Spanner is organized as a set of zones, where each zone is the rough analog of a deployment of Bigtable. 全球big table 集群(类比)被统一管理,统一调度起来就是spanner。
The universe master is primarily a console that displays status information about all the zones for interactive debugging. universe master并不是用来服务系统的,更像是个管理工具。


tablet和paxos state machine共存,多个互为replica的tablet和paxos state machine形成了paxos group,其中有一个是leader,也就是用于写的tablet,保管lock table等。该leader同时也是一个transaction manager,用于实现分布式transaction。当实现分布式transaction时候,有不止一个paxos group参与进来,这时候有一个group会被选作coordinator group,则该group的leader就是coordinator leader,该group的slave就是coordinator slave。(这部分跟Spanner没多少关系,是distributed transaction的经典内容)
在big table中,tablet只是行数据的容器,tablet内部的行都是一视同仁的;而spanner对tablet进行了进一步的结构划分,多了一层dictionary结构,用以区分那些PK前缀相同的行(比如,所有以Alice开头的行都在一个dictionary里面)。dictionary是数据复制和placement配置的基本单位,比如某个dictionary要分布在亚洲和美洲,共4份拷贝。
spanner中负载均衡的最小单位也是dictionary,同时提供方法MoveDir可以手动将一个dictionary移动到指定的zone。文中提到dictionary只是一层抽象目录,下面还有fragment才是真正的物理目录,有点诧异。细粒度当然可以更加优化负载均衡以及数据恢复,但是太细的粒度也意味着复杂度成倍增加,这是不是值得呢?可能的原因是某些用户的dictionary目录里面数据还是太多,而同时反正分布式transaction已经实现,不同fragment之间交互也顺便可以借点光,没有增加太多的实现负担,不过我仍然感觉到这点做的太复杂了。
另外,文中虽然没写,根据之前的一些资料,dictionary应该也是权限控制的最小单元。
关于数据模型:
关于big table 不实现传统transaction的理由是:我们认为这些transaction太复杂,程序员会过度使用transaction从而导致性能太差,所以不实现。
而这里spanner实现传统的transaction的理由是:系统的职责是实现应该有的功能,如果程序员用错了,那么改正就行了;但是如果系统不实现,谁也没办法用。
上面应该是经典的需求实现问题,不同的人会有不同的理解。
spanner的行模型是 (key:string, timestamp:int64) -> row content,可以看到跟big table的模型最大的不同是这里强化了row的概念,不再突出column;这样spanner的timestamp是赋给整行数据的,是有物理意义的,这使得spanner更像一个实现多版本并发的数据库,而在big table中,timestamp仅仅用于保存多个版本的key-value,跟并发完全无关;我觉得这也是为什么spanner称自己为semi-relational 数据库,而big table只称自己是semi-structure 数据库的原因。
下面是spanner的数据表模式,其中user是一张父亲表,album一张子表(不存在没有user的album),这非常像一个树形结构,user树枝,blbum是树叶,多么清晰,好的东西都是易于理解的,大部分时候也是难于实现的。

关于TrueTime:只要知道两点就可以了:
1. 一堆机器投票来决定当前时间应该是多少,然后按人头计数,人多者胜。
2. 跟传统投票不同的是,每个人不是报来一个数字,而是根据一般误差报上一个范围来,比如A报[3-4], B 报[4-5], C报[3-5],结果就会变成4,因为每人都同意现在是4点。再详细的话请看原论文吧。
并发控制:
1. 对于什么是external consistency, 我理解不深,觉得就当成serializable transaction的一种实现协议,和基于lock的、基于MVCC啥的并列,就可以了。解释:provides the illusion that each operation applied by concurrent processes takes effect instantaneously at some point between its invocation and its response, implying that the meaning of a concurrent object's operations can be given by pre- and post-conditions.
2. 一个paxos group内的leader通过投票选出来,通过不停的延长lease继续担当leader的角色,文中提到paxos group内任何两个paxos leader必须保证disjointness invariant,这是为什么呢?因为每个leader都要给自己这个group内执行的transaction分配一个timestamp, 如果两个leader的interval有重叠,那么就不能保证所有leader在分配timestamp时候全局单调递增。其实就是说,咱们俩一人一个时间段,这个时间段内的时间点随便我们分配,只要我们各自保证分配的时间单调递增,则咱俩都是单调递增的。
3. 文中一堆时间,简单抽象一下就是:spanner不依靠事件通信来保证transaction一致性,而是依靠严格的时间序列。
一个极端简单的例子:某个partition内部最新commit的一个transaction的完成时间是3点,当前还有两个transaction继续在执行,不知道什么时候结束,那么如果这时候有一个读请求过来,那么我们只能认让这个读的请求看到(visible)3点之前的数据,因为3点之后的数据可能只写了一半,是不允许读的。那么文中那么多的时间序列和假设就是为了保证读请求过来的时候,我们能准确的找到3点这个数字。很容易?如果是单机当然容易,如果有一堆机器参与了分布式transaction,找到3这个数字并不是轻而易举。
4. 几种操作
读写操作:最典型的操作,基于锁的并发控制,只不过使用乐观锁,如果出现冲突,某些低优先级的transaction先终止(系统会自动再重试),高优先级的先完成。在准备写之前,依然是决定timestamp,如果不是分布式transaction,则自己选一个时间就可以了;如果是分布式transaction,则同时收取所有participant的建议,选一个最大的,再跟cooperator自己的now比较选个大的,继续向下进行。
只读操作:跟上面举的例子类似,就是找个最近刚commit的transaction的时间点,然后返回该时间点之前写入的数据。值得注意的是,这时候,因为所有的replica都已经完成了写入,所以该时间点只要找到了之后,可以随便挑一个replica进行读。
SnapshotRead:这就不用说了,时间点都省的找了,client会提供;不过如果client提供的时间点还未到来呢?根据系统实现可以选择报错或者block,不过我想报错更合理吧,读取未来数据的业务没见过。

这部分transaction看起来复杂,因为主要是细节问题,宏观问题都是清楚明白的。
不得不说,Google的创新力很可怕,Spanner恐怕两年内不会有开源的实现,因为其不仅依靠软件、而且依靠硬件,更主要的是,开源界可能没有那么紧迫的需求推动。
逐步搬之前的文章过来:http://www.cnblogs.com/raymondshiquan/articles/2697956.html
[1] Bigtable: A Distributed Storage System for Structured Data
[2] jeff notes 2009
[3] Spanner