个性化推荐已成为人们获取信息的主要形式。以往,人们更多通过主动搜寻自己感兴趣的信息,而现在,基于算法推荐技术的信息分发平台会自动识别用户兴趣,快速筛选信息,推送用户所感兴趣的信息。
一方面,推荐系统大幅提升了用户体验,另一方面,个性化分发信息更精准、高效,可以帮助平台更准确地匹配用户和信息,大大提高流量变现效率,基于推荐技术的流量变现引擎甚至成就了万亿市值的庞大商业帝国。
从短视频信息流推荐、广告搜索到线上购物,这些应用都构筑于精准的推荐系统之上,背后的核心功臣就是深度学习模型。
不过,随着海量数据的积累以及更加频繁的用户数据迭代,底层系统可扩展性和训练速度面临严峻的挑战。人们发现,通用深度学习框架都不能直接满足工业级推荐系统的需求,而是必须基于通用深度学习框架做深度定制,甚至于要开发专门的系统才行。
针对现代推荐系统的种种痛点,一流科技 OneFlow 团队推出了一款高性能、可扩展、灵活度高的推荐系统组件 OneEmbedding。它的使用方式和通用深度学习框架一样简单,性能却远超通用框架,甚至超过了 NVIDIA HugeCTR 这样为推荐场景定制开发的系统。
具体而言,在 DCN、DeepFM 两个模型上,无论是 FP32 还是混合精度(automatic mixed-precision, AMP)训练,OneEmbedding 的性能大幅超过 HugeCTR,而在 HugeCTR 深度优化以至于有点 “过拟合” 的 DLRM 模型上,OneEmbedding 性能与 HugeCTR 基本持平。
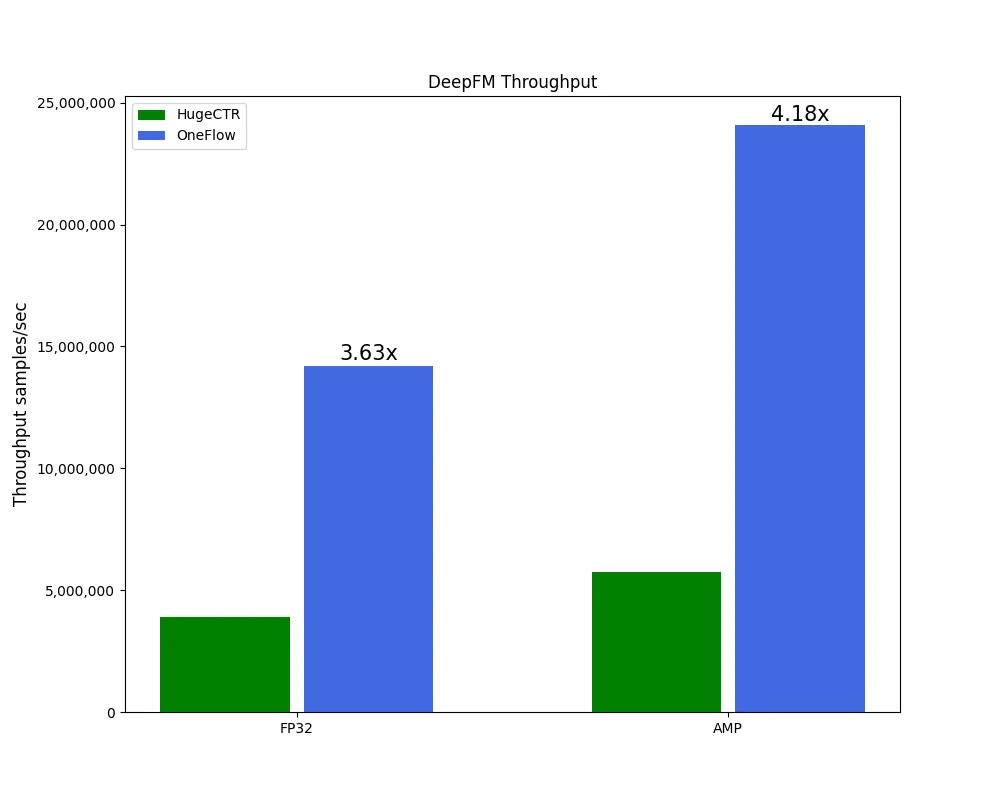
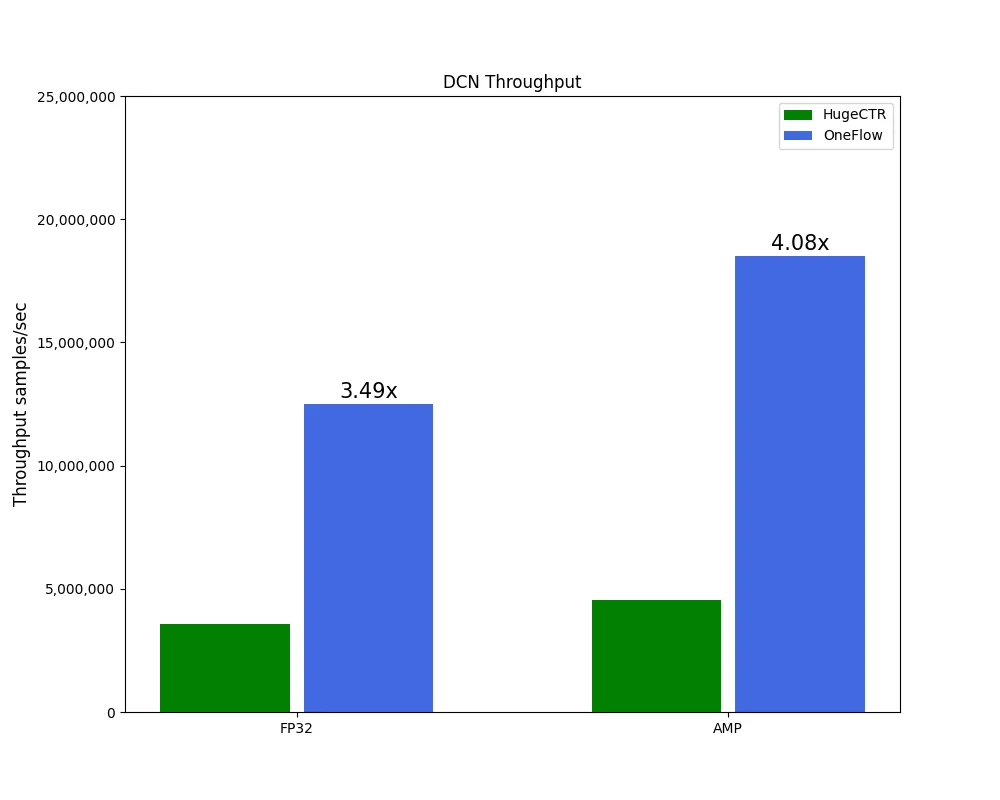
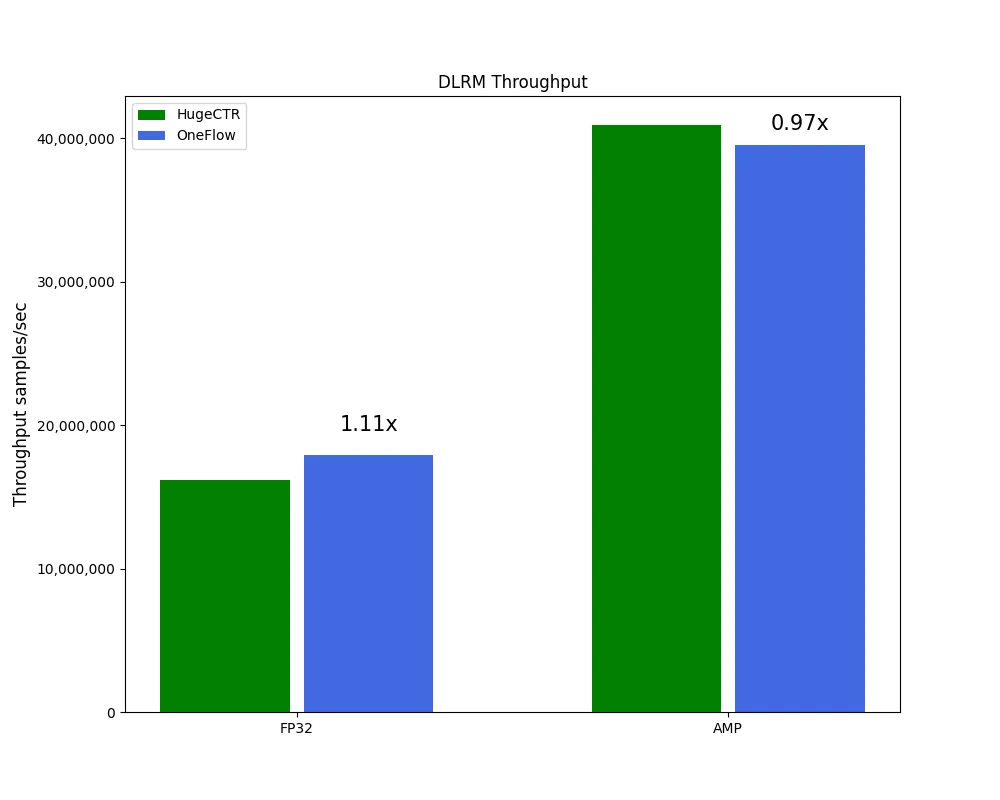
(以上测试环境均为:CPU Intel(R) Xeon(R) Platinum 8336C CPU @ 2.30GHz * 2;CPU Memory 1920GB;GPU NVIDIA A100-SXM-80GB * 8;SSD Intel SSD D7P5510 Series 3.84TB * 4)
当用户使用 OneFlow 搭建推荐模型时,只需使用以下数行代码对 Embedding 词表进行配置即可训练含有 TB 级别词表的推荐模型:
# self.embedding = nn.Embedding(vocab_size, embedding_vec_size)self.embedding = flow.one_embedding.MultiTableEmbedding( "sparse_embedding", embedding_dim=embedding_vec_size, dtype=flow.float, key_type=flow.int64, tables=tables, store_options=store_options, )
基于 OneEmbedding 搭建的常见搜索推荐广告模型案例地址:https://github.com/Oneflow-Inc/models/tree/main/RecommenderSystems
大规模推荐系统的挑战
一般而言,推荐系统需要使用类似性别、年龄、行为等方面的离散特征(sparse feature),在一个 Embedding 词表中用特征 ID 进行查表(lookup),取得对应的 Embedding 向量并送到下游使用。
常用的公开数据集 Criteo1T 中大概包含十亿个特征 ID,如果 embedding_dims 配置为 128,那总共需要 512 GB 空间来容纳 Embedding 参数,如果使用 Adam 优化器,由于需要保存额外的两个状态变量 m 和 v,所需存储容量就增加到 1536 GB。实际应用场景中,数据规模比 Criteo 还要高出几个数量级,模型的容量就更大了。
大规模推荐系统的核心问题就是,如何高效经济地支持大规模 Embedding 的查询和更新。权衡规模、成本和效率,出现了如下三种常见的解决方案。
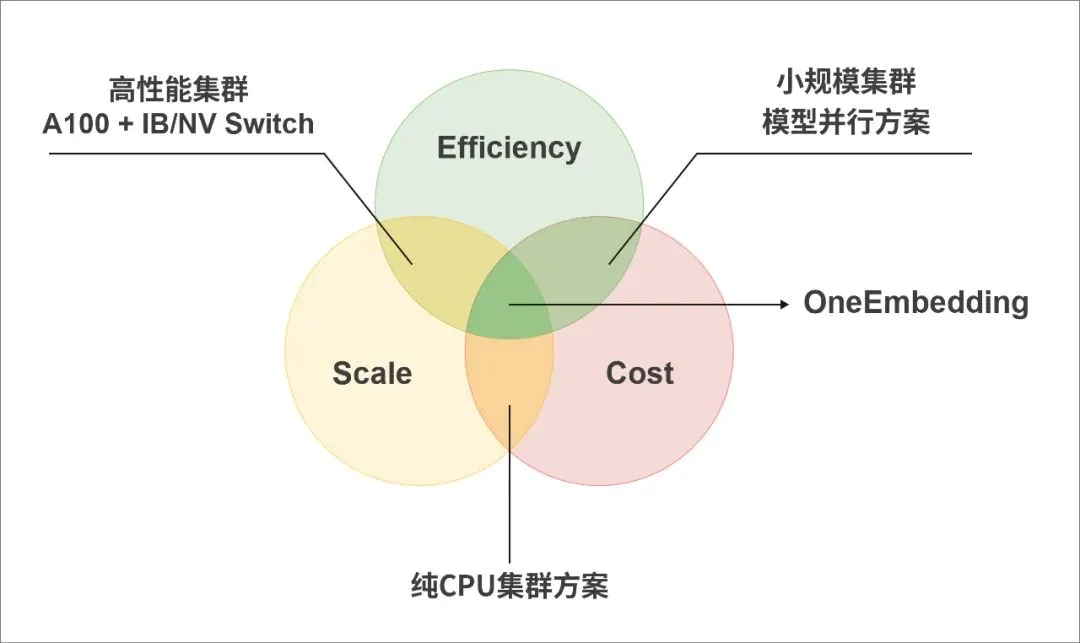
最常见也是最早出现的一种解决方案是将 Embedding 全部部署在 CPU 上,利用 CPU 内存容量大、成本低的特点扩展参数规模,优点是模型规模几乎可以无限大。不过,其缺点也很明显,无论是计算性能还是带宽,CPU 都远低于 GPU,导致 Embedding 部分成为显著瓶颈,往往需要数十乃至上百台 CPU 服务器才能支撑一个工业级的推荐系统。
鉴于 GPU 在稠密计算中得天独厚的优势,也有人建议用 GPU 来训练大型 Embedding 模型。问题是,GPU 很贵且显存容量有限,如果使用显存容量为 40GB 的 A100 来基于 Criteo 数据训练 128 维嵌入向量,至少需要 13 张显卡才能放下 512GB 的 Embedding 词表。每张卡只有 40GB 显存容量,分布式 Embedding 需要使用所谓的模型并行技术,理想情况下,为了解决更大规模的模型只需要增加 GPU 的数量即可。
现实是,GPU 相对于 CPU 的成本非常高昂,并且推荐系统中模型主体计算部分不大,模型并行在扩展过程中只是解决了 Embedding 规模的问题,训练速度的收益比较有限,甚至会因为多设备之间引入通信导致训练速度下降,因此通常只适用于小规模集群。
为了缓解 GPU 之间传输带宽的问题,业界发展出比以太网带宽更高的 NVSwitch、Infiniband 网络等互联技术。一方面,这意味着额外的成本,另一方面,很多用户的基础设施不具备相应改造、升级的条件。
那么,有没有鱼和熊掌兼得的方案?
针对上述方案存在的问题,OneFlow 团队设计了 OneEmbedding,通过分层存储让单卡也能支持 TB 级模型的训练,通过横向扩展让模型容量没有天花板,通过 OneFlow 的自动流水线机制、算子优化和通信量化压缩等技术实现极致性能,在用法像 PyTorch 一样简单的前提下, OneEmbedding 在 DLRM 模型上性能是 TorchRec 的 3 倍以上,开启 TorchRec 没有支持的混合精度后,OneEmbedding 的性能更是 TorchRec 的 7 倍以上。
(TorchRec 性能数据参考 8 卡 A100 测试结果:https://github.com/facebookresearch/dlrm/tree/main/torchrec_dlrm/#preliminary-training-results )
OneEmbedding 的核心优势
分层存储:单卡也能支持 TB 级模型训练
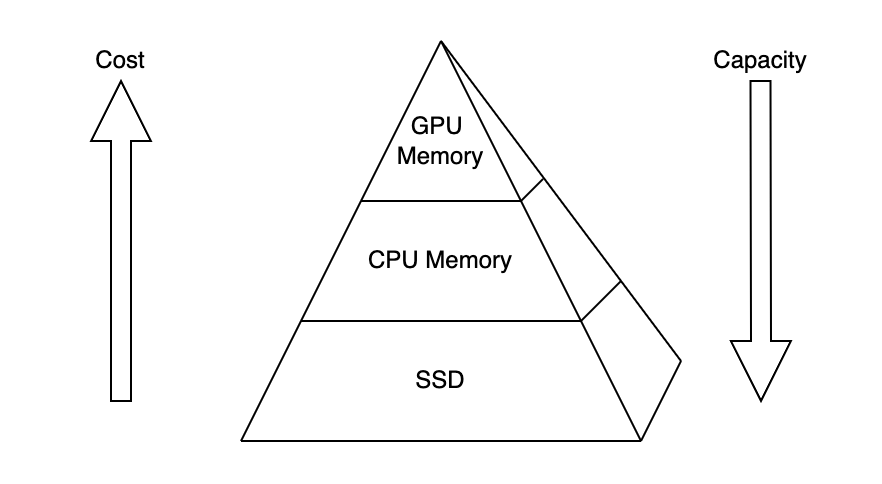
利用数据的空间局部性和时间局部性,多级缓存可以很好地实现性能和成本的折衷。OneEmbedding 也基于这个思想实现了多级缓存,即使用户只有一张 GPU 也可以训练 TB 级别的模型。
用户既可以把 Embedding 部署到 GPU 显存上,也可以把 Embedding 部署到 CPU 内存甚至是 SSD 上。这种方案可以发挥 CPU 内存或者 SSD 更低的成本优势,以对 Embedding 参数规模进行扩展,还可以利用 GPU 显存作为高速缓存设备,以实现高性能效果。
OneEmbedding 会动态地将最近频繁访问的条目缓存到 GPU 显存上,同时将最近访问频率较低的条目逐出到 CPU 内存或者 SSD 等底层存储中。在数据遵循幂律分布这一前提下,基于有效的 Cache 管理算法,OneEmbedding 可以使 GPU 缓存的命中率始终维持在较高的水平。
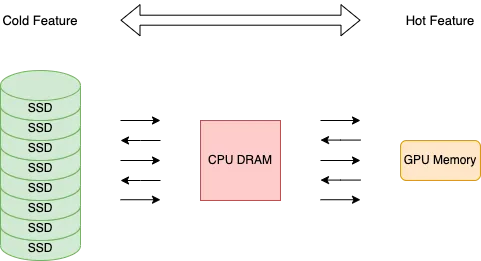
值得强调的是,OneEmbedding 只是将 CPU 内存和 SSD 作为存储设备,所有计算都在 GPU 上执行。目前,OneEmbedding 提供三种预置存储方案:
- 使用 GPU 显存存储模型所有参数
- 将 CPU 内存作为 Embedding 参数存储设备,并搭配使用 GPU 作为高速缓存
- 将 SSD 作为 Embedding 参数存储设备,并搭配使用 GPU 作为高速缓存
# 使用 SSD 作为存储设备,搭配 GPU 作为高速缓存store_options = flow.one_embedding.make_cached_ssd_store_options( cache_budget_mb=cache_memory_budget_mb, persistent_path=persistent_path, capacity=vocab_size, )
用户可以根据实际使用时的硬件设备情况,只需用短短数行代码进行配置,即可一箭三雕实现规模、效率、成本的最优化。
为了掩盖 CPU 和 SSD 取数据的延迟,OneEmbedding 引入流水线、数据预取等技术手段,使得在以 CPU 内存 和 SSD 作为存储后端的同时,效率依然可以和使用纯 GPU 训练那样保持在同样的水平。
分别对三种存储方案进行测试。其中,测试用例与 MLPerf 的 DLRM 模型一致,参数规模约为 90GB。在使用 SSD 和 CPU 内存作为存储设备时,我们配置的 GPU 缓存大小为每个 GPU 12GB,相比于 90 GB 的总参数量,只能有一部分参数保持在 GPU 显存内,其他的参数则是保存在 CPU 内存或者 SSD 上,随着训练过程动态的换入到 GPU 缓存中来,测试结果如下图。
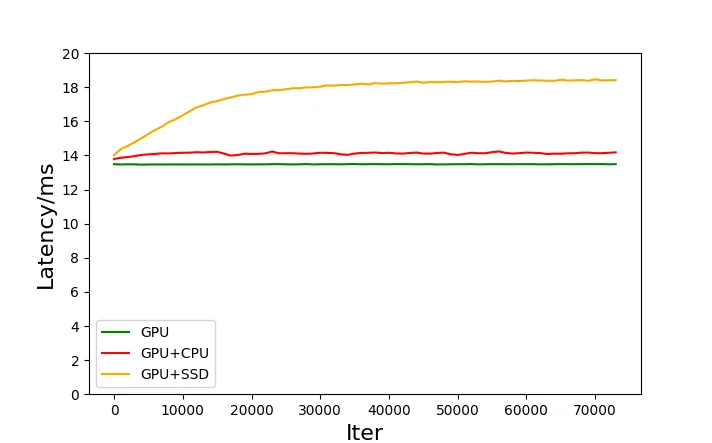
(测试环境:CPU Intel(R) Xeon(R) Silver 4214R CPU @ 2.40GHz * 2;CPU Memory 512GB;GPU NVIDIA A100-PCIE-40GB * 4;SSD Intel SSD D7P5510 Series 7.68TB * 4)
从测试结果中可以看到:
(1)纯 GPU 显存方案性能最佳,但由于 GPU 显存只有 4x40GB,理论上最大只能够训练 160 GB 模型;(2)相比纯 GPU 显存方案,GPU 缓存 + CPU 存储的方案性能只有微小损失,但可以把参数规模的天花板扩展到 CPU 内存容量,往往是数百 GB~数 TB;(3)更进一步,如果能接受更大的性能损失,GPU 缓存 + SSD 存储的方案能将参数规模的天花板扩展到 SSD 的容量,模型规模可达数十 TB,甚至更大。
如果我们想在只有一个 NVIDIA A30-24GB GPU 的服务器上进行上述 DLRM 模型的完整训练,24G 的显存显然无法直接训练 90GB 规模的模型。借助分层存储,使用 CPU 内存作为存储设备,GPU 显存作为高速缓存,就可以支持比 90GB 还大的模型。
横向扩展:多卡线性加速,打破模型天花板
使用分层存储技术,OneEmbedding 提升了单卡情况下的 Embedding 参数规模极限,只要内存空间够大甚至能够训练 TB 级别大小的模型。如果模型的容量进一步扩大到甚至大大超过 CPU 内存的容量,用户还可以在多级存储的基础上借助 OneFlow 的并行能力轻松地横向拓展到多机多卡,以训练更大的模型。
在推荐系统中,模型主体参数相较 Embedding 则小的多。因此我们一般将 Embedding 部分设置为模型并行,模型主体设置为数据并行。通过使用多机多卡,可进一步提升 Embedding 大小。

具体到实现细节,每个 Rank 各自负责一部分 Embedding 的存储,特征 ID 进入到各个 Rank,可能存在重复 ID 的情况,首先要进行去重(即下图的 ID Shuffle);各个 Rank 拿着去重后的 ID 去查询 Embedding,得到对应的局部数据,所有 Rank 数据合并后各 Rank 得到完整的 Embedding 数据(即下图的 Embedding Shuffle);最后,各 Rank 以数据并行的方式完成整个模型训练过程。
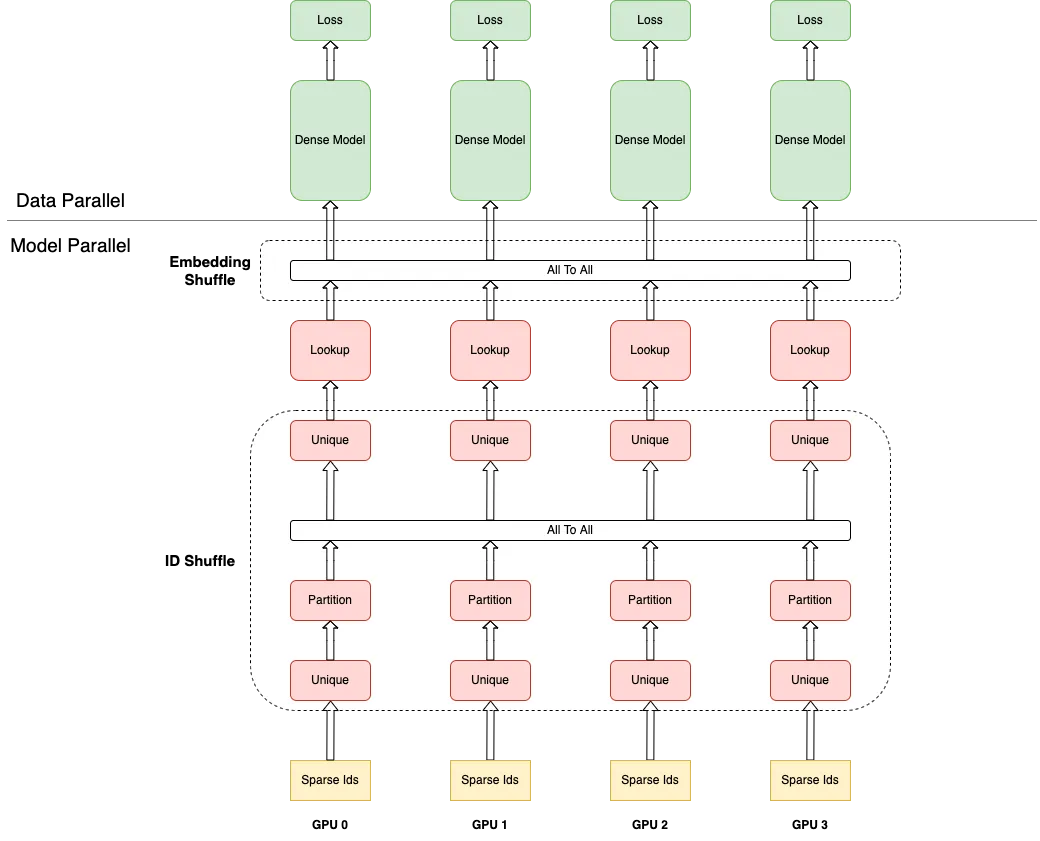
下图展示了 OneEmbedding 采取纯 GPU 显存的策略训练 DLRM 模型时,FP32 和 AMP 配置下,不同 GPU 个数下模型吞吐量。
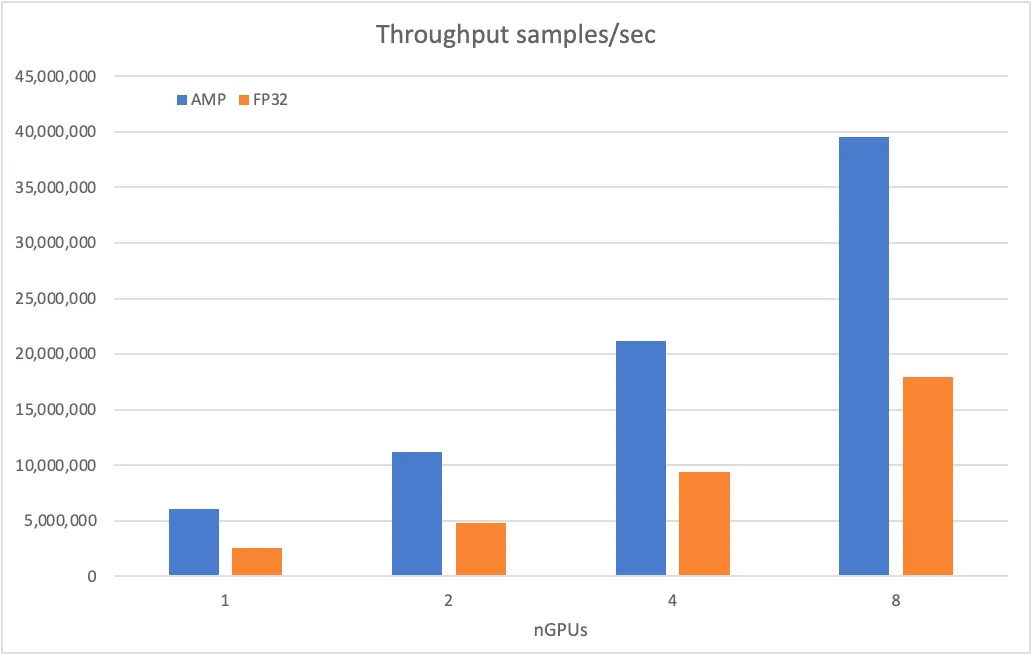
(测试环境:CPU Intel(R) Xeon(R) Platinum 8336C CPU @ 2.30GHz * 2;CPU Memory 1920GB;GPU NVIDIA A100-SXM-80GB * 8;SSD Intel SSD D7P5510 Series 3.84TB * 4)
可以看到,随着 GPU 设备数的增加,模型吞吐量均能显著增加,在混合精度情况下,单张 GPU 能有 600 万的吞吐量,当扩展到 8 张 GPU 时能有近 4000 万的吞吐量。
流水线机制:自动重叠计算和数据传输
在 DLRM 模型中,Embedding 中的 Dense Feature 会进入到 Bottom MLP 中,而 Sparse Feature 经过 Embedding 查询得到对应特征。两者进入 Interaction 进行特征交叉,最后进入到 Top MLP。
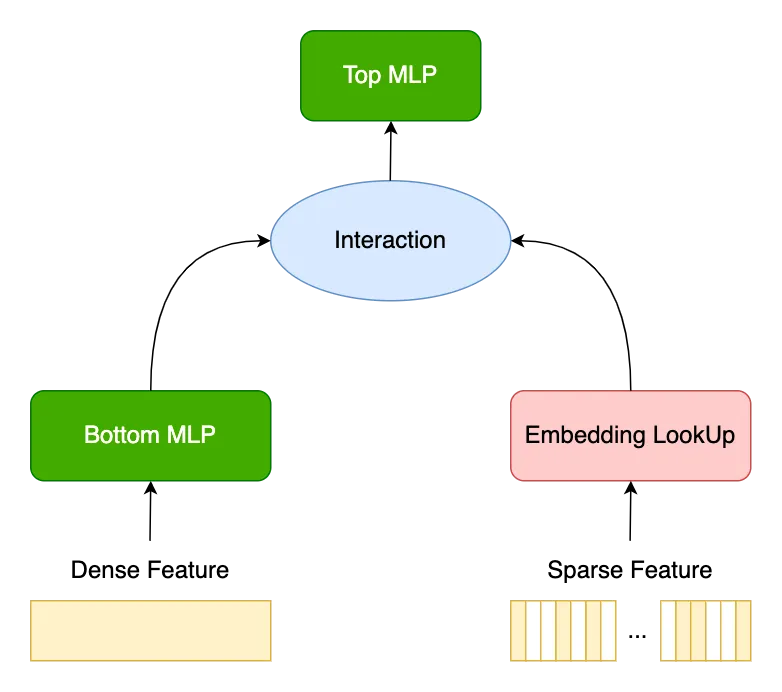
Embedding 相关操作包含查表(Embedding Lookup)、更新(Embedding Update)。由于 OneEmbedding 使用的是分层存储的机制,可能会遇到特征 ID 没有命中高速缓存的情况,此时,数据拉取耗时较长,会影响训练速度。
为避免这个不足,OneEmbedding 加入数据预取(Embedding Prefetch)操作,以保证查表和更新操作均能在 GPU 上执行。由于前后迭代之间的数据预取不存在依赖关系,在当前迭代计算的同时,可以预取下一个迭代需要的 Embedding 数据,实现计算和预取的重叠。
在 Embedding 数据查询交换的过程中,与 Embedding 操作无关的 Dense Feature 可以进入到 Bottom MLP 进行计算,在时间上进行重叠。完整的重叠执行时序如下图所示。
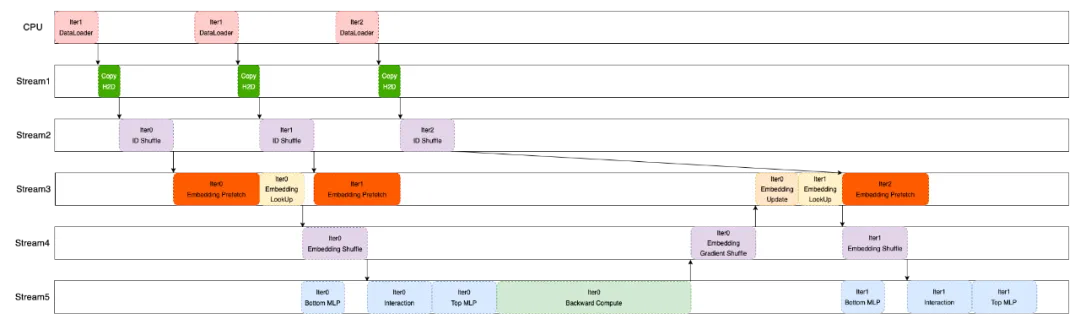
如此复杂的数据流水线控制在传统深度学习框架里是一个很挑战的问题。不仅如此,在实际推荐场景中,用户的数据在不断变化,这要求流水线机制还要能应对动态数据。
而 OneFlow 的 Actor 机制让这一切问题变得很简单,每个 Actor 都通过自己内部的状态机和消息机制实现了分布式协同工作。通过为每个 Actor 赋予多份存储块,不同的 Actor 可以同时工作,重叠各自的工作时间,从而实现 Actor 之间的流水线。我们只需要将 Embedding 操作分配到单独的一个 stream 上,即可让系统自发地形成流水线。