






DataWhale夏令营第四期魔搭- AIGC方向task01笔记
DataWhale夏令营,AIGC方向task1笔记。从平台注册到程序调试,最终生成一组古风小故事图片,并对其进行总结分析。

蚂蚁 CodeFuse 代码大模型技术解析:基于全仓库上下文的代码补全
CodeFuse 代码补全插件是 CodeFuse 系列产品中用户数量最多、留存率最大,调用AI能力最多的产品~欢迎大家体验试用https://github.com/codefuse-ai/RepoFuse

告别Hugging Face模型下载难题:掌握高效下载策略,畅享无缝开发体验
【8月更文挑战第2天】告别Hugging Face模型下载难题:掌握高效下载策略,畅享无缝开发体验
阿里云 Serverless 高可用架构
阿里云的《卓越效能,极简运维,Serverless高可用架构》解决方案提供了全托管服务、自动扩展、高可用性、无缝集成以及内置安全等核心功能。该方案通过免除底层基础设施的管理,允许用户专注于应用程序开发,同时确保应用的稳定运行和资源的有效利用。 **核心功能简介**: - **全托管服务**:用户无需关心底层硬件,由阿里云负责维护和扩展计算资源。 - **自动扩展**:根据业务需求自动调整资源,确保应用在高峰期有足够的计算能力,低谷期则节省成本。 - **高可用性**:多地域和多可用区部署,实现故障自动切换,确保业务连续性。 - **无缝集成**:与阿里云的其他服务(如数据库、消息队列等)深度
未来语音交互新纪元:FunAudioLLM技术揭秘与深度评测
人类自古以来便致力于研究自身并尝试模仿,早在2000多年前的《列子·汤问》中,便记载了巧匠们创造出能言善舞的类人机器人的传说。

RAG+AI工作流+Agent:LLM框架该如何选择,全面对比MaxKB、Dify、FastGPT、RagFlow、Anything-LLM,以及更多推荐
【7月更文挑战第9天】RAG+AI工作流+Agent:LLM框架该如何选择,全面对比MaxKB、Dify、FastGPT、RagFlow、Anything-LLM,以及更多推荐

智胜未来:国内大模型+Agent应用案例精选,以及主流Agent框架开源项目推荐
【7月更文挑战第8天】智胜未来:国内大模型+Agent应用案例精选,以及主流Agent框架开源项目推荐
c++开发redis module问题之module根据Redis的角色采取不同的行为,如何解决
c++开发redis module问题之module根据Redis的角色采取不同的行为,如何解决

《<灵活调度,高效编排,容器化管理云上应用>解决方案测评》
在这次测评中,聚焦于技术细节、引导帮助、代码示例、容器托管优势及云产品体验五大方面。技术细节展示出色但需深化复杂场景的优化策略;文档和引导能满足基本需求,但关键步骤应增强提示;代码示例有价值,但遇到实际使用问题;容器化托管带来快速部署、资源隔离和自动化管理的优势,受到高度评价;云产品功能齐全,性能良好,但高级功能配置和手册可读性有待提升。总体而言,解决方案有亮点,期待持续改进。
千问文本分类任务微调
这段代码定义了一个`predict`函数,它使用Hugging Face的`AutoModelForCausalLM`和`AutoTokenizer`来生成对话回复。模型和tokenizer分别从指定路径加载,然后对输入的`messages`(包含指令和用户输入)进行处理,通过模型生成响应。代码最后展示了一个测试用例,其中讨论了历史人物的评价。模型的输出被打印出来。整个流程涉及预处理、模型推理和后处理,用于生成与历史相关的内容。

操作系统OS Copilot 产品体验评测
OS Copilot体验摘要: 开发者评价OS Copilot在软件开发和系统维护中提供帮助。新人易上手,界面直观,但高级功能说明不足。工具在编程时给出智能建议,提升效率,专长于操作系统任务。相比同类产品,如GitHub Copilot,OS Copilot在OS相关建议上更专业,但特定场景准确性待提高。期望增加更多操作系统支持及自动错误排查功能。适合与ACK智能助手等产品联动,提供云环境全面支持。
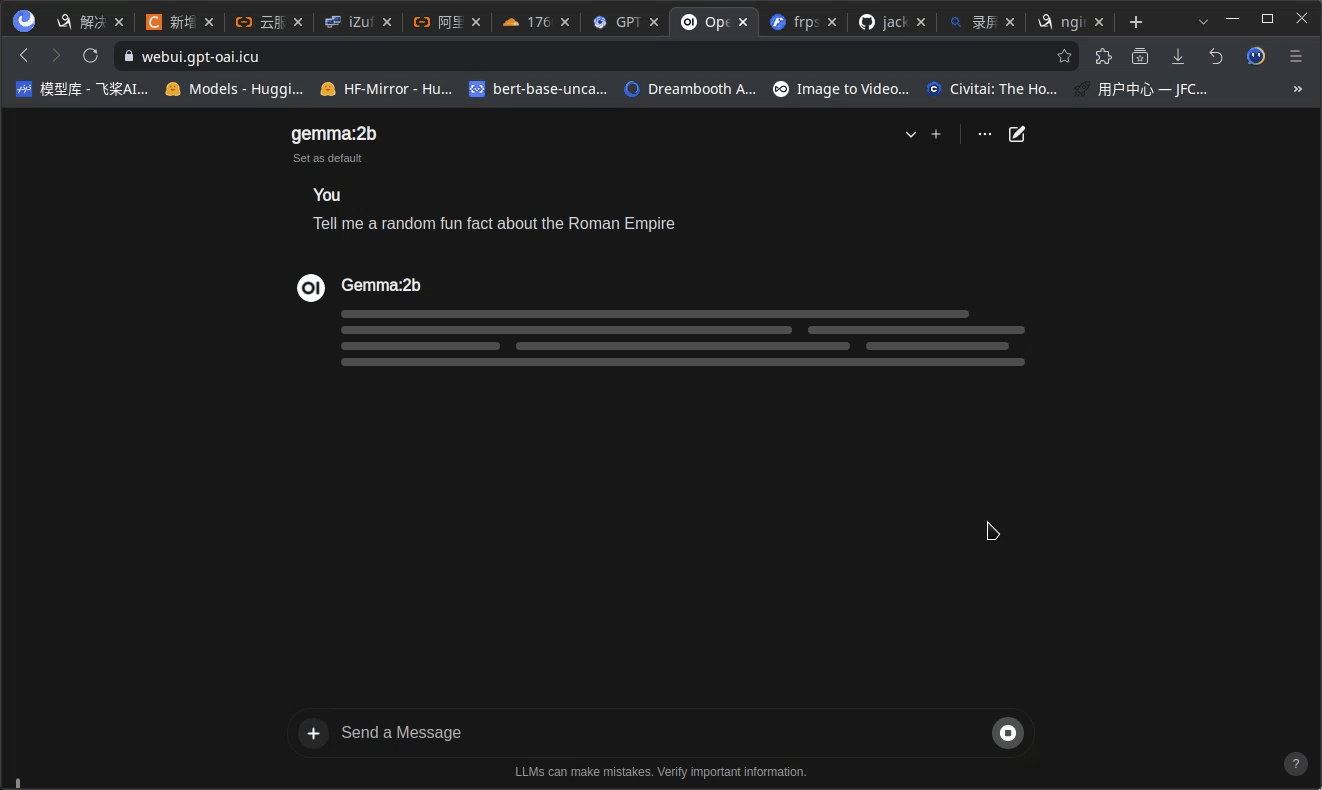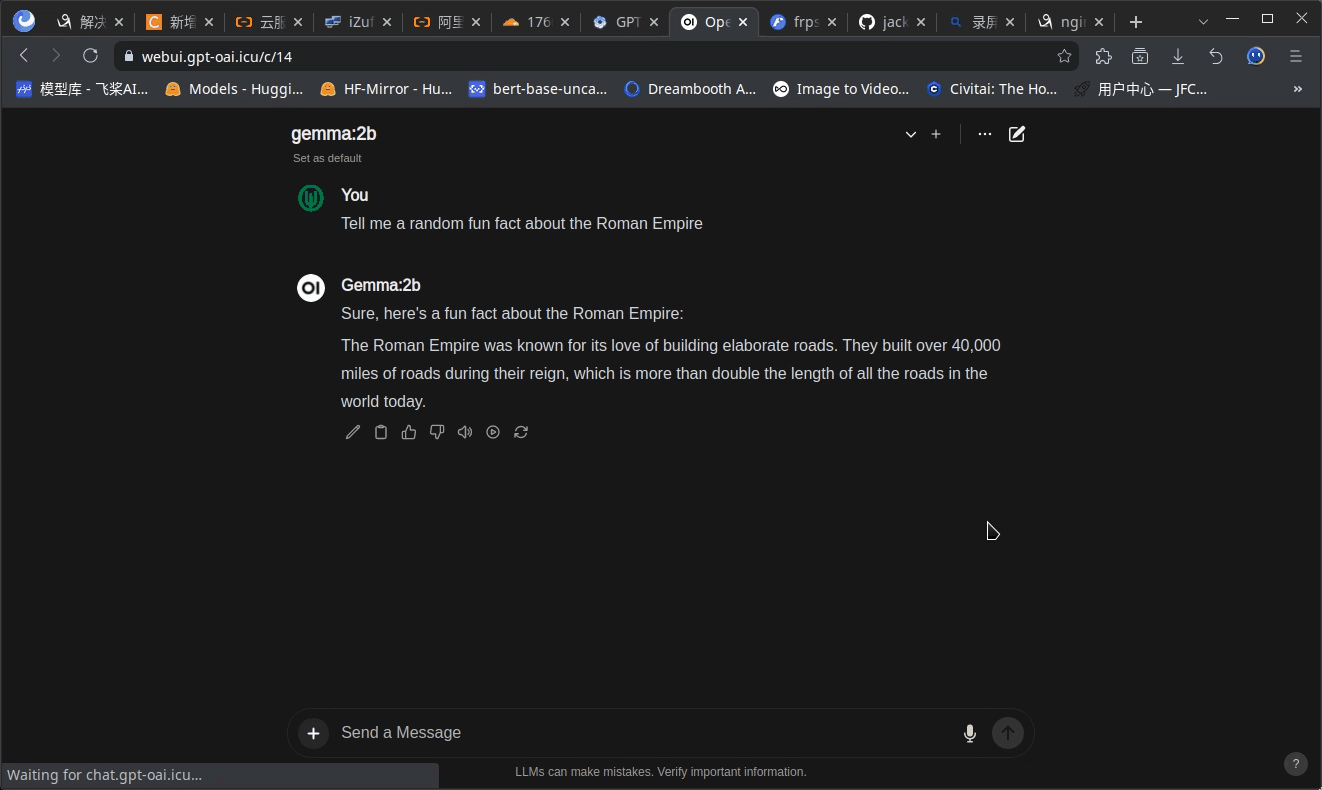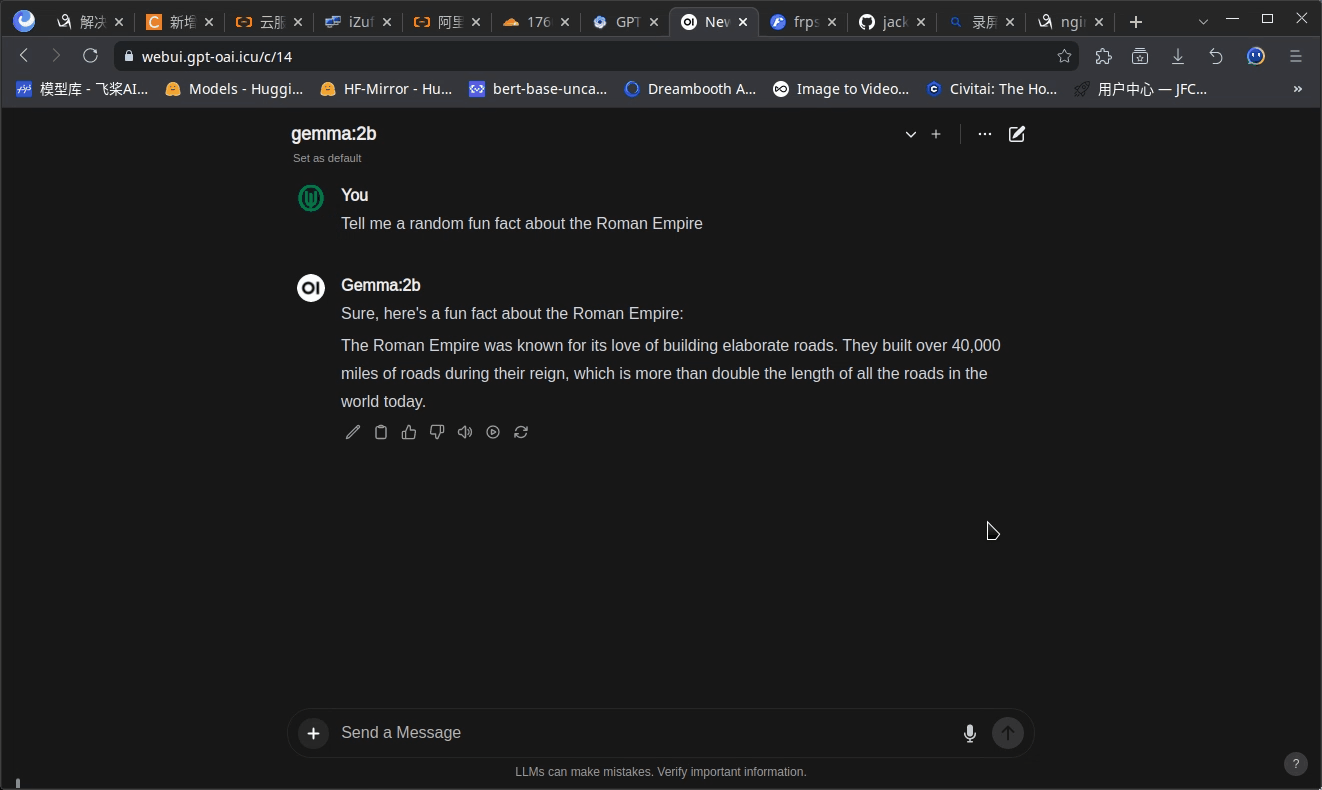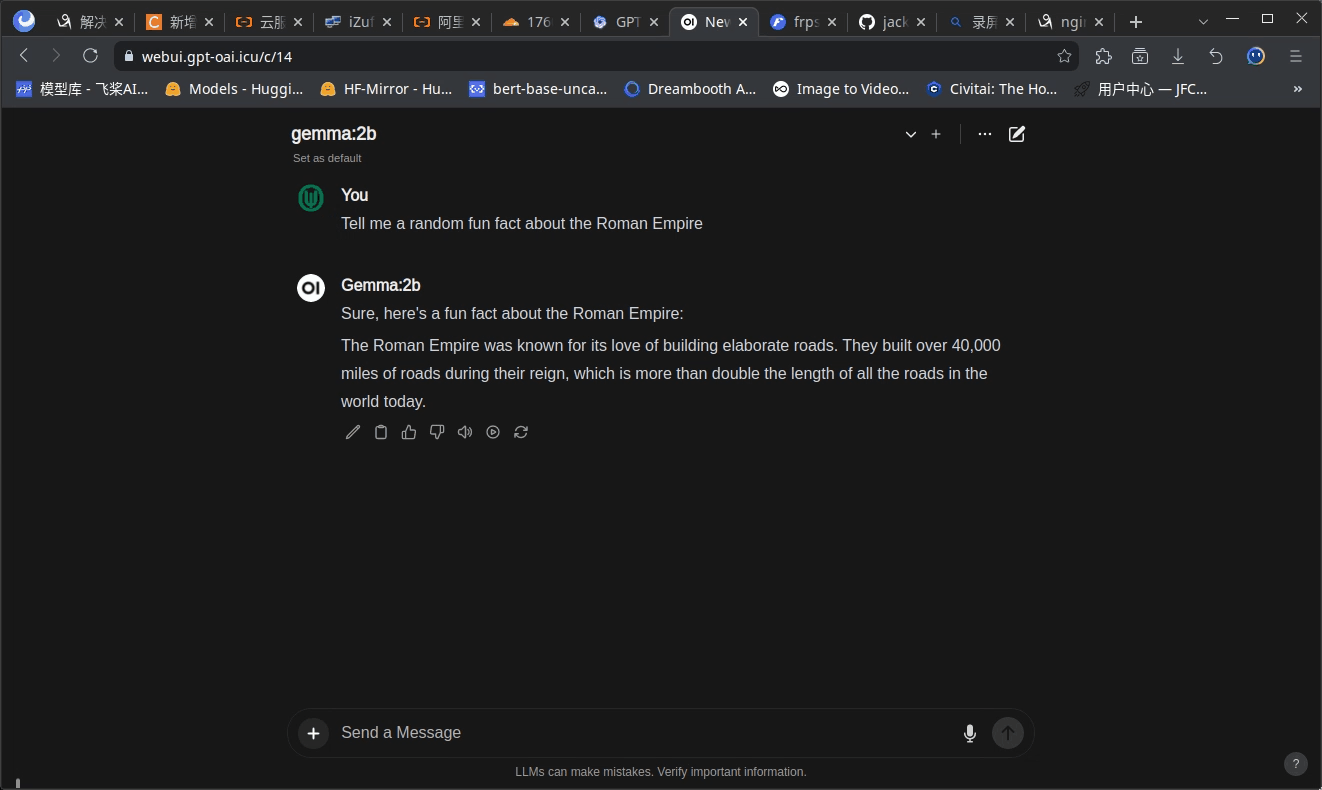
开发个人Ollama-Chat--1 项目介绍
**开发个人Ollama-Chat** 是一系列教程,聚焦于使用`go-zero`框架构建聊天应用后端,并通过`Docker`部署至公网。涉及`Ollama`API调用、`Docker`本地环境、`cloudflare`免费部署、内网穿透及阿里云域名绑定。项目包括服务拆分、用户&模型管理、UI设计及多步骤部署。
OS Copilot:我的云助手体验与改进建议
学生分享阿里云OSCopilot,体验AI助手中数据库操作与Linux命令支持。遇到AccessKey配置小困扰,发现尖括号非必需。给予9分好评,期待开源并贡献力量。与GitHub Copilot相比,OSCopilot执行效率高,但需增强错误分析功能,适合新手简化服务器运维,目前仍有改进空间。
2024年6月118篇代码大模型论文最全整理
基座模型与训练数据、代码微调、测试基准、代码Agent、低资源语言处理、AI代码安全与分析、人机交互、软件工程下游任务应用主题代码大模型论文分享,干货满满~
一种基于YOLOv8改进的高精度表面缺陷检测网络, NEU-DET和GC10-DET涨点明显(原创自研)
【7月更文挑战第3天】一种基于YOLOv8改进的高精度表面缺陷检测, 在NEU-DET和GC10-DET任务中涨点明显;
ACL 2024|D2LLM:将Causal LLM改造成向量搜索模型的黑科技
D2LLM:一种针对语义搜索任务的新颖方法,它结合了大语言模型(LLM)的准确性与双编码器的高效性。实验表明,D2LLM在多项任务上的性能超越了五个领先基准模型,尤其是在自然语言推理任务中,相对于最佳基准模型的提升达到了6.45%
一种基于YOLOv8改进的高精度红外小目标检测算法 (原创自研)
【7月更文挑战第2天】 💡💡💡创新点: 1)SPD-Conv特别是在处理低分辨率图像和小物体等更困难的任务时优势明显; 2)引入Wasserstein Distance Loss提升小目标检测能力; 3)YOLOv8中的Conv用cvpr2024中的DynamicConv代替;
YOLOv10实战:SPPF原创自研 | SPPF_attention,重新设计加入注意力机制 | NEU-DET为案列进行展开
【7月更文挑战第1天】 优点:为了利用不同的池化核尺寸提取特征的方式可以获得更多的特征信息,提高网络的识别精度; 如何优化:在此基础上加入注意力机制,能够在不同尺度上更好的、更多的获取特征信息,从而获取全局视角信息并减轻不同尺度大小所带来的影响; SPPF_attention,重新设计加入注意力机制 ,在NEU-DEU任务中mAP50从0.683提升至0.703;
YOLOv10实战:红外小目标实战 | 多头检测器提升小目标检测精度
本文改进: 在进行目标检测时,小目标会出现漏检或检测效果不佳等问题。YOLOv10有3个检测头,能够多尺度对目标进行检测,但对微小目标检测可能存在检测能力不佳的现象,因此添加一个微小物体的检测头,能够大量涨点,map提升明显; 多头检测器提升小目标检测精度,1)mAP50从0.666提升至0.677
try-catch的作用及使用场景
`try-catch`是错误处理的关键结构,用于执行可能出错的代码并捕获异常,防止程序崩溃。它用于异常处理、资源管理、错误恢复、日志记录和控制业务逻辑。例如,在数据库操作、文件操作、网络请求及用户输入处理中常见其身影,确保程序稳定性和用户体验。
CodeFuse-13B: 预训练多语言代码大模型
该论文针对蚂蚁集团的现实应用场景,详细介绍了CodeFuse-13B预训练模型的数据准备和训练过程,揭秘了CodeFuse是如何成为一款能够同时处理英文和中文提示的高效预训练代码大型语言模型(LLM)。论文还对CodeFuse在代码生成、翻译、注释和测试用例生成等应用场景中的性能进行了评估。CodeFuse-13B在蚂蚁集团内广
openai停止中国的api服务,但是性能相当的阿里云免费提供迁移
OpenAI暂停中国API服务,阿里云百炼响应迅速,提供免费tokens(2200万)与迁移服务给受影响开发者。Qwen2-72B与GPT-4同列全球第四(HELM MMLU榜)。Qwen-plus调用成本仅GPT-4的1/50。阿里云百炼以开放性著称,兼容LlamaIndex等,支持多种数据源及自定义组件,加速AI应用集成。官网有丰富资源,助力快速上手大模型开发。

modelscope-funasr部署后,但是无法通过html链接,是为什么呀?
在虚拟机上成功部署了Docker化的modelscope-funasr服务,日志显示初始化正常。防火墙已关闭,但尝试通过HTML页面访问时连接失败。
使用PostMan请求阿里云通义千问大模型
本文介绍如果通过postman调用阿里云通义千问API,然后介绍如果使用多语言集成,最后介绍了快速使用postman压测创建的API请求。
【LangChain系列】第十篇:数据保护简介及实践
【5月更文挑战第24天】本文探讨了在使用大型语言模型时保护个人数据的重要性,特别是涉及敏感信息如PII(个人可识别信息)的情况。为了降低数据泄露风险,文章介绍了数据匿名化的概念,通过在数据进入LLM前替换敏感信息。重点讲解了Microsoft的Presidio库,它提供了一个可定制的文本匿名化工具。此外,文章还展示了如何结合LangChain库创建一个安全的匿名化流水线,包括初始化匿名器、添加自定义识别器和操作符,以及在问答系统中集成匿名化流程。通过这种方式,可以在利用LLMs的同时保护数据隐私。
B端Agent的机会,不在于“助手”,而在基于垂直领域的任务式Agent微调
该文讨论了AI助手在企业服务中的应用,指出通用的“助手”Agent(如Coze、钉钉)在B端业务场景中表现一般,因为它们依赖用户正确指导且易发散。相比之下,任务式Agent(如TFlow)针对特定行业和场景进行微调,能更好地理解和执行复杂任务,具有更高准确性和稳定性,适合企业业务流程。TFlow的优势包括场景微调、优化流程处理,开发和使用成本较低,能直接解决实际业务问题。作者认为,B端Agent的机会在于为企业降低成本或增加效益,而任务式Agent通过微调形成的适配性成为其核心竞争力。
【LangChain系列】第九篇:LLM 应用评估简介及实践
【5月更文挑战第23天】本文探讨了如何评估复杂且精密的语言模型(LLMs)应用。通过创建QA应用程序,如使用GPT-3.5-Turbo模型,然后构建测试数据,包括手动创建和使用LLM生成示例。接着,通过手动评估、调试及LLM辅助评估来衡量性能。手动评估借助langchain.debug工具提供执行细节,而QAEvalChain则利用LLM的语义理解能力进行评分。这些方法有助于优化和提升LLM应用程序的准确性和效率。
【LangChain系列】第八篇:文档问答简介及实践
【5月更文挑战第22天】本文探讨了如何使用大型语言模型(LLM)进行文档问答,通过结合LLM与外部数据源提高灵活性。 LangChain库被介绍为简化这一过程的工具,它涵盖了嵌入、向量存储和不同类型的检索问答链,如Stuff、Map-reduce、Refine和Map-rerank。文章通过示例展示了如何使用LLM从CSV文件中提取信息并以Markdown格式展示
向量数据库Chroma极简教程
本文重点围绕向量数据库Chroma的使用和实战,主要包括以下内容: * Chroma设计理念 * Chroma常见概念(数据集,文档,存储,查询,条件过滤) * Chroma快速上手 * Chroma支持的Embeddings算法 * 实战:在Langchain中使用Chroma对中国古典四大名著进行相似性查询
【LangChain系列】第七篇:工作流(链)简介及实践
【5月更文挑战第21天】LangChain是一个框架,利用“链”的概念将复杂的任务分解为可管理的部分,便于构建智能应用。数据科学家可以通过组合不同组件来处理和分析非结构化数据。示例中展示了如何使用LLMChain结合OpenAI的GPT-3.5-turbo模型,创建提示模板以生成公司名称和描述。顺序链(SimpleSequentialChain和SequentialChain)则允许按顺序执行多个步骤,处理多个输入和输出

【LangChain系列】第五篇:大语言模型中的提示词,模型及输出简介及实践
【5月更文挑战第19天】LangChain是一个Python库,简化了与大型语言模型(LLM)如GPT-3.5-turbo的交互。通过ChatOpenAI类,开发者可以创建确定性输出的应用。提示词是指导LLM执行任务的关键,ChatPromptTemplate允许创建可重用的提示模板。输出解析器如StructuredOutputParser将模型的响应转化为结构化数据,便于应用处理。LangChain提供可重用性、一致性、可扩展性,并有一系列预建功能。它使得利用LLM构建复杂、直观的应用变得更加容易。
【LangChain系列】第四篇:向量数据库与嵌入简介及实践
【5月更文挑战第18天】 本文介绍了构建聊天机器人和语义搜索的关键组件——向量存储和嵌入。首先,文章描述了工作流程,包括文档拆分、生成嵌入和存储在向量数据库中。接着,通过Python代码展示了如何设置环境并处理文档,以及如何创建和比较文本嵌入。向量存储部分,文章使用Chroma存储嵌入,并进行了相似性检索的演示。最后,讨论了故障模式,如重复文档和未捕获结构化信息的问题。整个博文中,作者强调了在实际应用中解决这些问题的重要性。
【LangChain系列】第三篇:Agent代理简介及实践
【5月更文挑战第17天】LangChain代理利用大型语言模型(LLM)作为推理引擎,结合各种工具和数据库,处理复杂任务和决策。这些代理能理解和生成人类语言,访问外部信息,并结合LLM进行推理。文章介绍了如何通过LangChain构建代理,包括集成DuckDuckGo搜索和维基百科,以及创建Python REPL工具执行编程任务。此外,还展示了如何构建自定义工具,如获取当前日期的示例,强调了LangChain的灵活性和可扩展性,为LLM的应用开辟了新途径。
【AI】从零构建深度学习框架实践
【5月更文挑战第16天】 本文介绍了从零构建一个轻量级的深度学习框架tinynn,旨在帮助读者理解深度学习的基本组件和框架设计。构建过程包括设计框架架构、实现基本功能、模型定义、反向传播算法、训练和推理过程以及性能优化。文章详细阐述了网络层、张量、损失函数、优化器等组件的抽象和实现,并给出了一个基于MNIST数据集的分类示例,与TensorFlow进行了简单对比。tinynn的源代码可在GitHub上找到,目前支持多种层、损失函数和优化器,适用于学习和实验新算法。
【LangChain系列】第二篇:文档拆分简介及实践
【5月更文挑战第15天】 本文介绍了LangChain中文档拆分的重要性及工作原理。文档拆分有助于保持语义内容的完整性,对于依赖上下文的任务尤其关键。LangChain提供了多种拆分器,如CharacterTextSplitter、RecursiveCharacterTextSplitter和TokenTextSplitter,分别适用于不同场景。MarkdownHeaderTextSplitter则能根据Markdown标题结构进行拆分,保留文档结构。通过实例展示了如何使用这些拆分器,强调了选择合适拆分器对提升下游任务性能和准确性的影响。
【LangChain系列】第一篇:文档加载简介及实践
【5月更文挑战第14天】 LangChain提供80多种文档加载器,简化了从PDF、网站、YouTube视频和Notion等多来源加载与标准化数据的过程。这些加载器将不同格式的数据转化为标准文档对象,便于机器学习工作流程中的数据处理。文中介绍了非结构化、专有和结构化数据的加载示例,包括PDF、YouTube视频、网站和Notion数据库的加载方法。通过LangChain,用户能轻松集成和交互各类数据源,加速智能应用的开发。


