
实时计算 Flink
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。
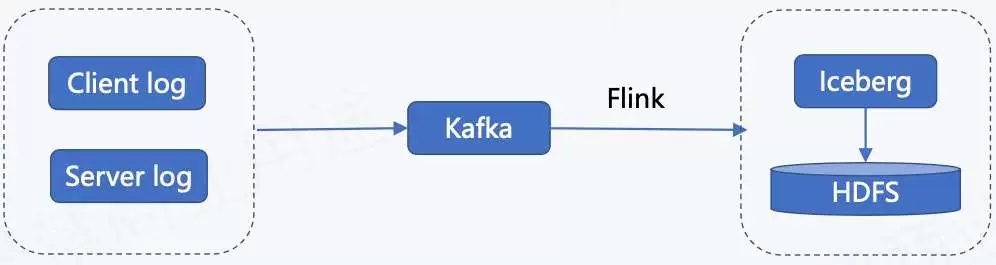
汽车之家:基于 Flink + Iceberg 的湖仓一体架构实践
由汽车之家实时计算平台负责人邸星星在 4 月 17 日上海站 Meetup 分享的,基于 Flink + Iceberg 的湖仓一体架构实践。
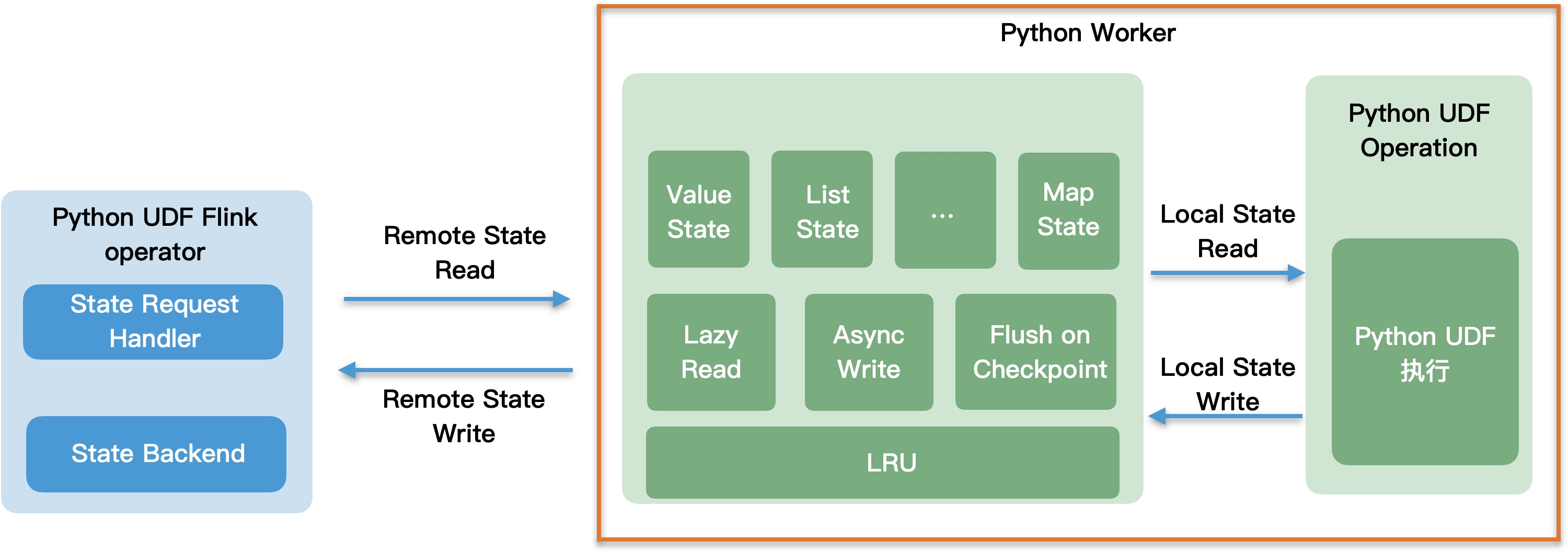
PyFlink 教程(三):PyFlink DataStream API - state & timer
介绍如何在 Python DataStream API 中使用 state & timer 功能。

来电科技:基于 Flink + Hologres 的实时数仓演进之路
本文将会讲述共享充电宝开创企业来电科技如何基于 Flink + Hologres 构建统一数据服务加速的实时数仓
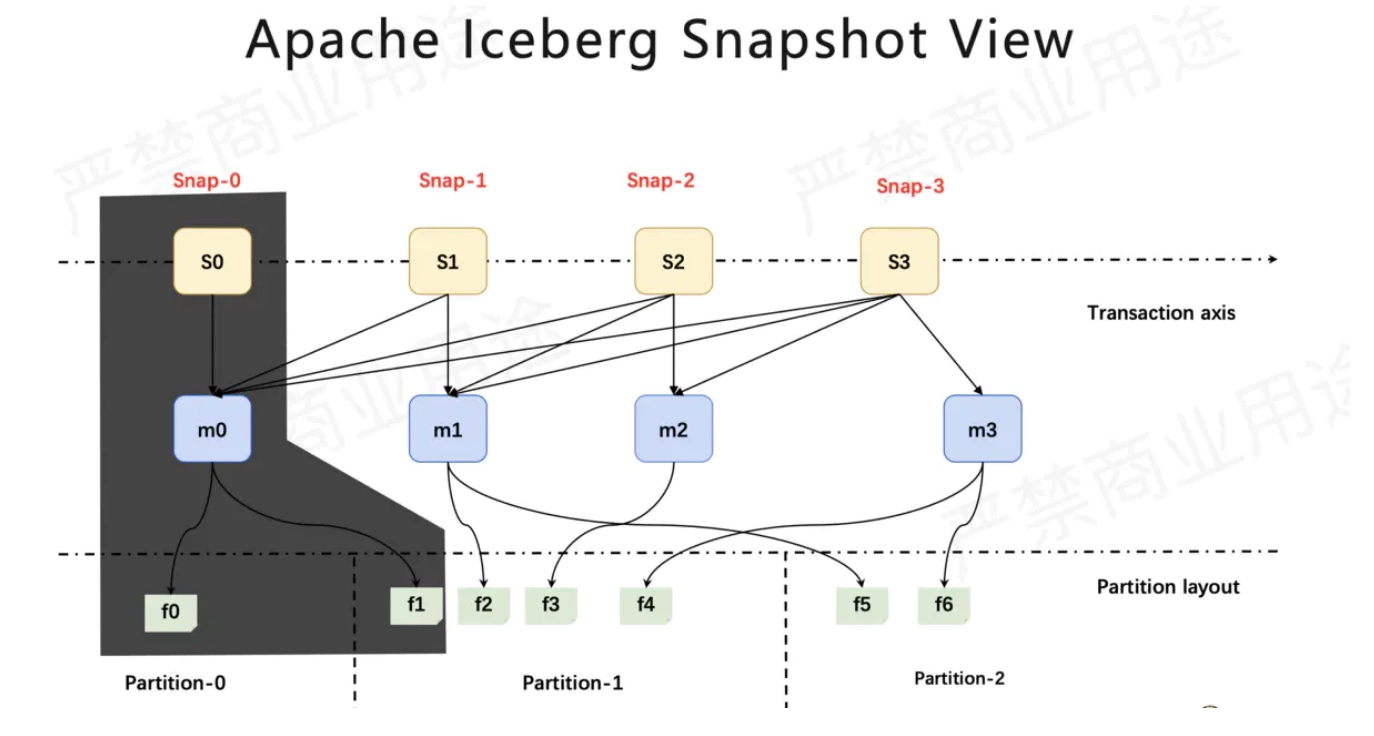
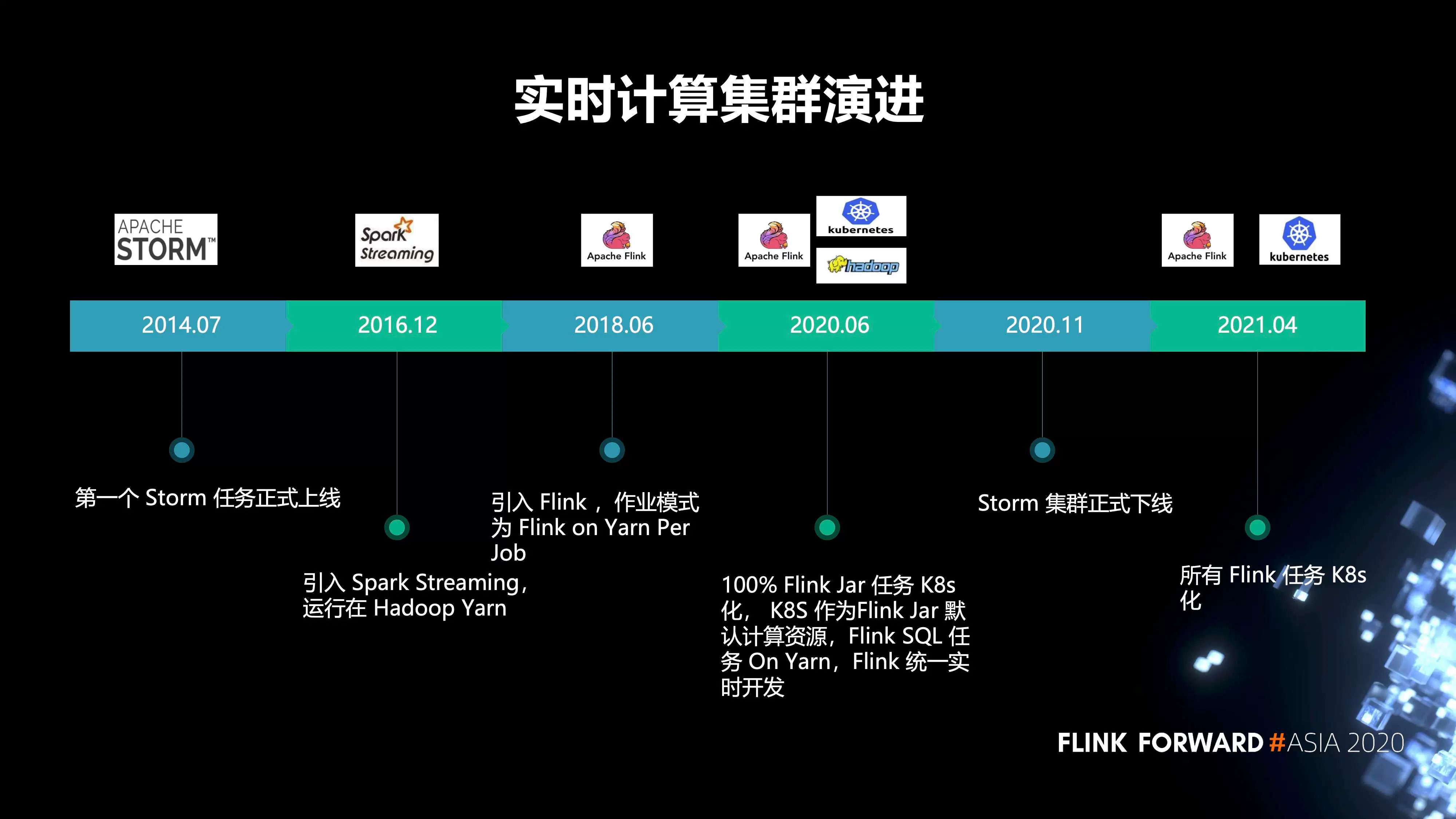

实时数仓入门训练营:实时计算Flink版总体介绍
实时计算Flink版(Alibaba Cloud Realtime Compute for Apache Flink,Powered by Ververica)是阿里云基于 Apache Flink 构建的企业级、高性能实时大数据处理系统,由 Apache Flink 创始团队官方出品,拥有全球统一商业化品牌,完全兼容开源 Flink API,提供丰富的企业级增值功能。

Flink 和 Pulsar 的批流融合
如何通过 Apache Pulsar 原生的存储计算分离的架构提供批流融合的基础,以及 Apache Pulsar 如何与 Flink 结合,实现批流一体的计算。


Call For Presentations!Flink Forward Global 2021 议题征集ing
Flink Forward 全球在线会议将在 2021 年 10 月 26 - 27 日再次重磅开启!现面向全球用户征集议题!如果您对 Flink 的实践案例、深度技术、社区生态和 Stateful Functions 等方向有自己的心得和积累,欢迎投递议题,向全球的开发者分享自己的经验!
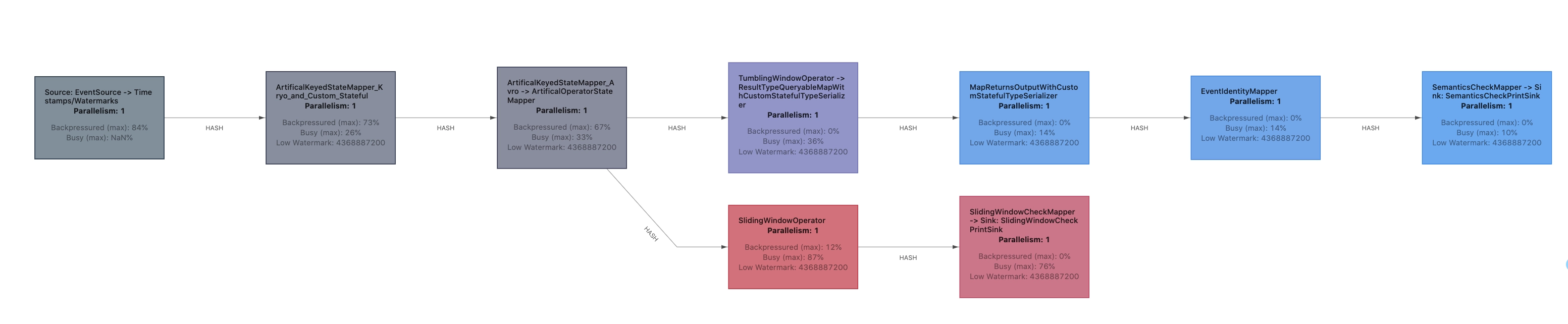
官宣|Apache Flink 1.13.0 正式发布,流处理应用更加简单高效!
Flink 1.13.0 版本让流处理应用的使用像普通应用一样简单和自然,并且让用户可以更好地理解流作业的性能。

Apache Flink在 bilibili 的多元化探索与实践
bilibili 万亿级传输分发架构的落地,以及 AI 领域如何基于 Flink 打造一套完善的预处理实时 Pipeline。

Flink 最佳实践之使用 Canal 同步 MySQL 数据至 TiDB
本文将介绍如何将 MySQL 中的数据,通过 Binlog + Canal 的形式导入到 Kafka 中,继而被 Flink 消费的案例。

PyFlink Table API - Python 自定义函数
Python 自定义函数是 PyFlink Table API 中最重要的功能之一,其允许用户在 PyFlink Table API 中使用 Python 语言开发的自定义函数,极大地拓宽了 Python Table API 的使用范围。

Flink 实时计算在微博的应用
微博通过将 Flink 实时流计算框架跟业务场景相结合,在平台化、服务化方面做了很大的工作,在开发效率、稳定性方面也做了很多优化。我们通过模块化设计和平台化开发,提高开发效率。

百信银行基于 Apache Hudi 实时数据湖演进方案
本文介绍了百信银行实时计算平台的建设情况,实时数据湖构建在 Hudi 上的方案和实践方法,以及实时计算平台集成 Hudi 和使用 Hudi 的方式。


阿里云超强专家阵容倾力打造实时数仓 “王炸组合”,只需 5 天从 0 到 1,结营抢好礼,速来报名!
《实时数仓入门训练营》,理论与实践的摩擦,概念与案例的碰撞,从 0 到1 快速上手,让自己技能加点,速来报名!

Apache Flink Meetup 北京站,1.13 新版本发布 x 互娱场景实践分享的开发者盛筵!
Flink 1.13 版本新功能的深入解读+Flink 在互娱行业典型实践应用。





Flink + Hudi 在 Linkflow 构建实时数据湖的生产实践
可变数据的处理一直以来都是大数据系统,尤其是实时系统的一大难点。在调研多种方案后,我们选择了 CDC to Hudi 的数据摄入方案,目前在生产环境可实现分钟级的数据实时性,希望本文所述对大家的生产实践有所启发。

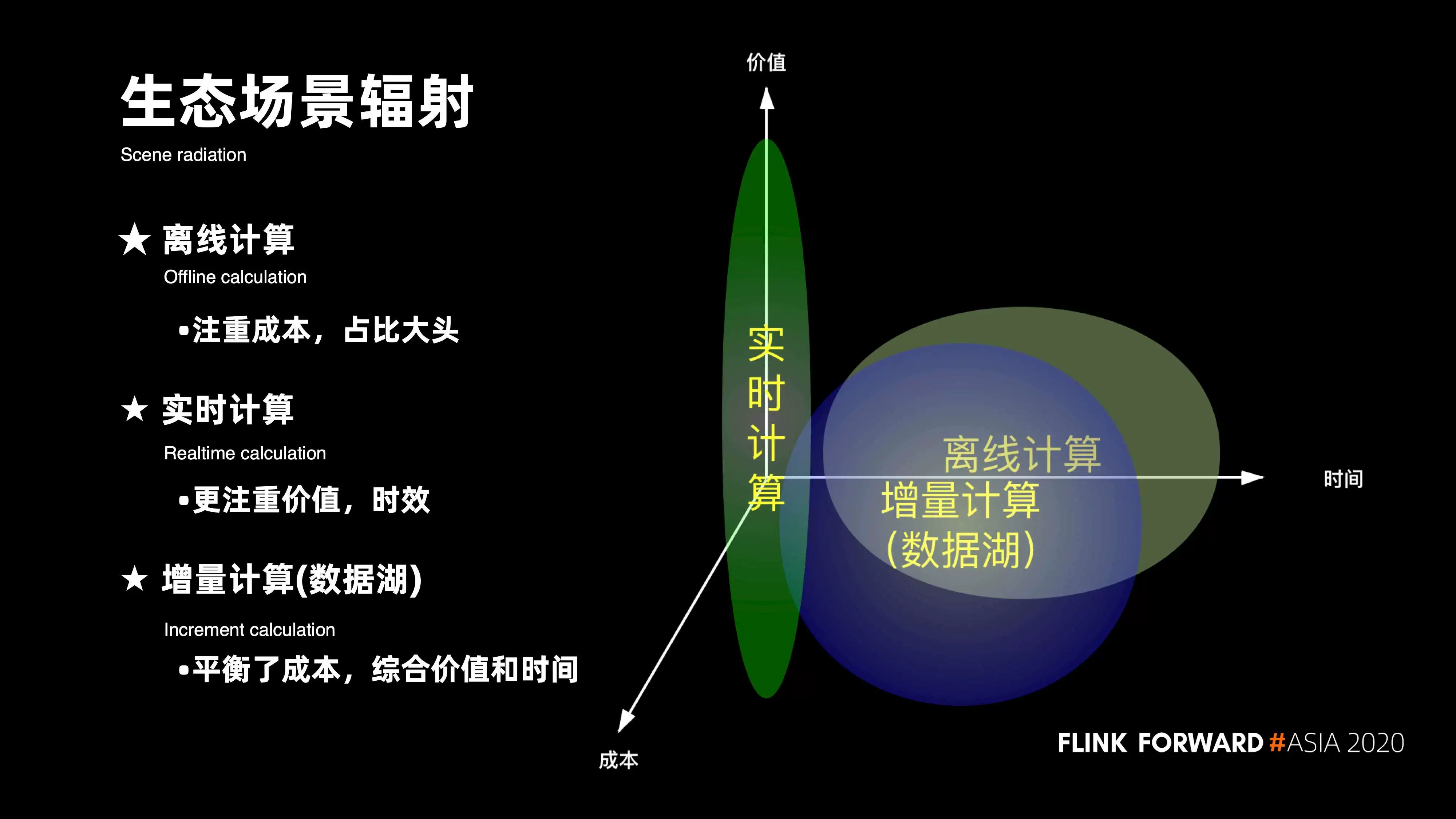
融合趋势下基于 Flink Kylin Hudi 湖仓一体的大数据生态体系
本文由 T3 出行大数据平台负责人杨华和资深大数据平台开发工程师王祥虎介绍 Flink、Kylin 和 Hudi 湖仓一体的大数据生态体系以及在 T3 的相关应用场景。

汽车之家基于 Flink 的数据传输平台的设计与实践
数据接入与传输作为打通数据系统与业务系统的一道桥梁,是数据系统与架构中不可或缺的一个重要部分。数据传输系统稳定性和准确性,直接影响整个数据系统服务的 SLA 和质量。此外如何提升系统的易用性,保证监控服务并降低系统维护成本,优雅应对灾难等问题也十分重要。

知乎的 Flink 数据集成平台建设实践
本文由知乎技术平台负责人孙晓光分享,主要介绍知乎 Flink 数据集成平台建设实践。内容如下: 1. 业务场景 ; 2. 历史设计 ; 3. 全面转向 Flink 后的设计 ; 4. 未来 Flink 应用场景的规划。

免费下载!Apache Flink 必知必会电子书, 轻松收获 Flink 生产环境开发技能
“实时计算”不再只是未来趋势,它已经融入到企业生产的各个环节之中。一线开发同学如何掌握大数据极致算力应用,企业如何全面提升数据服务能力?


【必看】如何正确使用实时计算 Flink 版?
本篇文章将从实时计算 Flink 版产品功能、产品架构、产品模式、产品优势、产品应用场景等全面呈现,同时还汇总了实时计算 Flink 版学习资料!更有特惠独享活动限时参与!


Flink 必知必会经典课程8:Flink Connector 详解
关于Flink Connector的详解,本文将通过四部分展开介绍:1. 连接器;2. Source API;3. Sink API;4. Collector的未来发展。





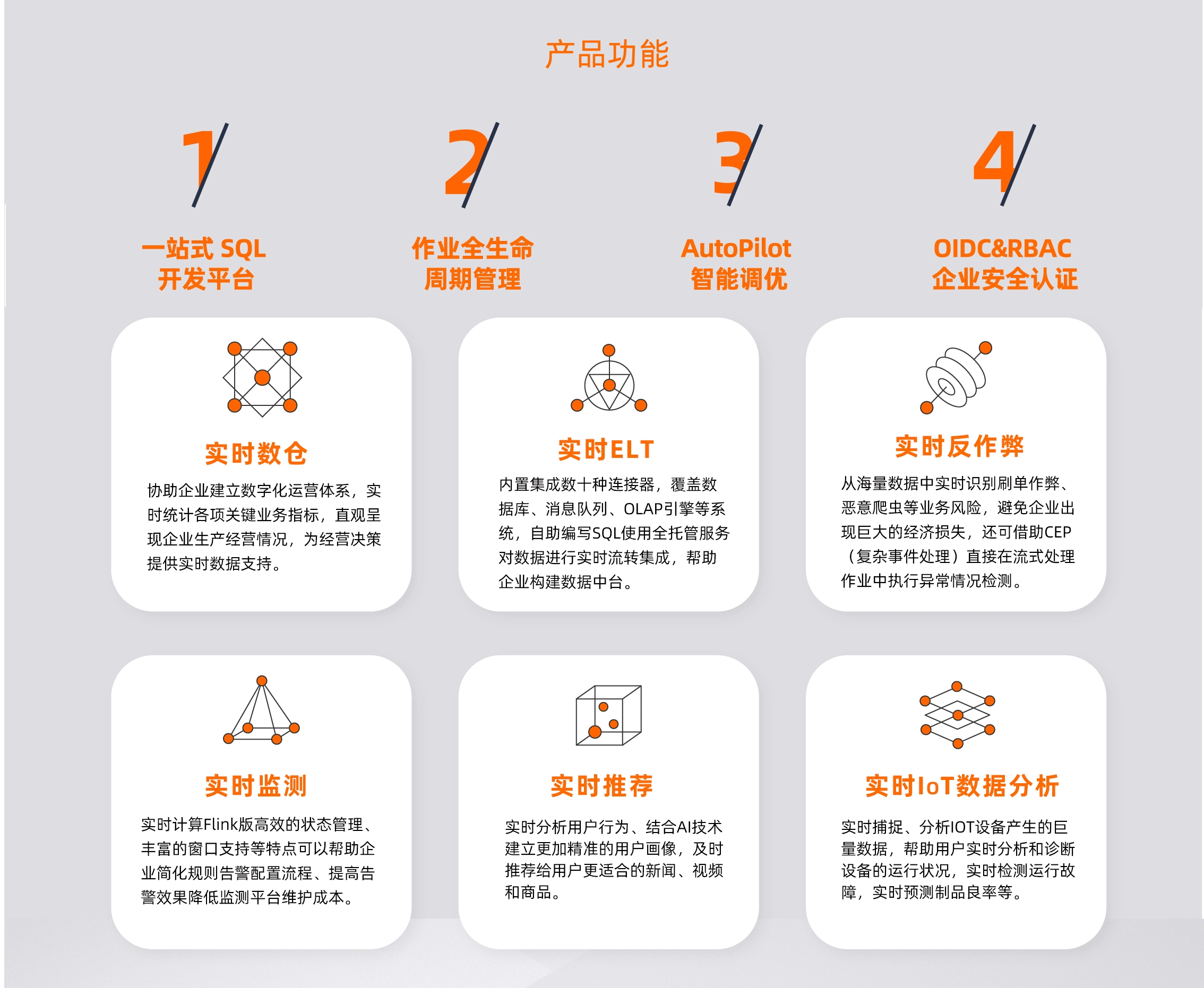

七大经典技术场景!Apache Flink 在多维领域应用的 40+ 实践案例
随着 Apache Flink 自身的发展,越来越多的企业选择 Apache Flink 应用于自身的业务场景,如底层平台建设、实时数仓、实时推荐、实时分析、实时大屏、风控、数据湖等场景中,解决实时计算的需求。


Flink 必知必会经典课程2:Stream Processing with Apache Flink
本篇内容包含三部分展开介绍Stream Processing with Apache Flink:1、并行处理和编程范式;2、DataStream API概览及简单应用;3、 Flink 中的状态和时间。

字节跳动单点恢复功能及 Regional CheckPoint 优化实践
本文介绍字节跳动在过去一段时间里做的两个主要的 Feature,一是在 Network 层的单点恢复的功能,二是 Checkpoint 层的 Regional Checkpoint。

十大行业经典案例!Apache Flink 的 40 个最佳实践
如今,Apache Flink 行业应用几何?在降本增效的需求驱动下,企业如何实现数据与算力价值最大化?本文整理了 Flink 社区近一年的社区案例,并按照行业进行分类,供大家参考!

Flink 必知必会经典课程4:Fault-tolerance in Flink
本文由 Apache Flink PMC , 阿里巴巴高级技术专家李钰分享,主要从有状态的流计算、全局一致性快照 、Flink的容错机制、Flink的状态管理 四个方面介绍 Flink 的容错机制原理。

Flink 必知必会经典课程6:PyFlink 快速上手
本文介绍了PyFlink项目的目标和发展历程,以及PyFlink目前的核心功能,包括Python Table API、Python UDF、向量化Python UDF、Python UDF Metrics、PyFlink依赖管理和Python UDF执行优化,同时也针对功能展示了相关demo。

Flink 必知必会经典课程3:Flink Runtime Architecture
众所周知 Flink 是分布式的数据处理框架,用户的业务逻辑会以Job的形式提交给 Flink 集群。Flink Runtime作为 Flink 引擎,负责让这些作业能够跑起来并正常完结。这些作业既可以是流计算作业,也可以是批处理作业,既可以跑在裸机上,也可以在Flink集群上跑,Flink Runtime必须支持所有类型的作业,以及不同条件下运行的作业。








