Caused by: com.ververica.cdc.connectors.shaded.org.apache.kafka.connect.errors.DataException: file is not a valid field name
at com.ververica.cdc.connectors.shaded.org.apache.kafka.connect.data.Struct.lookupField(Struct.java:254) ~[flink-sql-connector-mysql-cdc-3.0.0.jar:3.0.0]
at com.ververica.cdc.connectors.shaded.org.apache.kafka.connect.data.Struct.getCheckType(Struct.java:261) ~[flink-sql-connector-mysql-cdc-3.0.0.jar:3.0.0]
oracle 同步到doris,报这个错误,源表跟目标表结构是一样的,这个,怎么处理?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
这个问题通常是由于源表和目标表的字段不匹配导致的。尽管您提到源表和目标表结构相同,但报错信息可能表明源系统中有一个名为file的字段未在目标Doris表中找到,或者Flink CDC配置中可能包含了源系统中不存在的字段。请检查MySQL CDC配置,确保所有配置的字段都在源数据库的表中存在。如果问题依然存在,尝试更新到最新版本的Flink CDC connector,因为新版本可能会修复此问题。
遇到报错com.ververica.cdc.connectors.shaded.org.apache.kafka.connect.errors.DataException: file is not a valid field name,表明在同步过程中尝试访问的字段名file在实际的表结构中不存在。
解决方案建议:
核对字段名称:再次仔细对比源表和目标表的结构,确保字段名称完全一致,特别留意大小写差异。
检查同步配置:确认同步工具或作业的配置中没有错误地指定了字段名,包括任何正则表达式或通配符的使用,确保它们正确匹配了所有相关表的结构。
更新或调整同步工具:考虑升级至最新版本的同步工具或框架,如Ververica Platform 6.0.2及以上版本,这些新版本可能已经解决了类似问题,特别是对于分库分表场景的自动处理
日志分析:深入分析同步过程的日志,寻找有关字段映射或解析失败的具体信息,这有助于定位问题所在。
验证权限与设置:确认执行同步任务的用户具有足够的权限访问所有涉及的数据库和表,并检查是否已根据最佳实践设置了Debezium的相关参数,如debezium.inconsistent.schema.handling.mode[1],以更宽容的方式处理潜在的架构不一致问题。
```js
202x-xx-xx xx:xx:xx,xxx ERROR io.debezium.connector.mysql.BinlogReader [] - Encountered change event 'Event{header=EventHeaderV4{timestamp=xxx, eventType=TABLE_MAP, serverId=xxx, headerLength=xxx, dataLength=xxx, nextPosition=xxx, flags=xxx}, data=TableMapEventData{tableId=xxx, database='xxx', table='xxx', columnTypes=xxx, xxx..., columnMetadata=xxx,xxx..., columnNullability={xxx,xxx...}, eventMetadata=null}}' at offset {ts_sec=xxx, file=mysql-bin.xxx, pos=xxx, gtids=xxx, server_id=xxx, event=xxx} for table xxx.xxx whose schema isn't known to this connector. One possible cause is an incomplete database history topic. Take a new snapshot in this case.
Use the mysqlbinlog tool to view the problematic event: mysqlbinlog --start-position=30946 --stop-position=31028 --verbose mysql-bin.004419
202x-xx-xx xx:xx:xx,xxx ERROR io.debezium.connector.mysql.BinlogReader [] - Error during binlog processing. Last offset stored = null, binlog reader near position = mysql-bin.xxx/xxx
202x-xx-xx xx:xx:xx,xxx ERROR io.debezium.connector.mysql.BinlogReader [] - Failed due to error: Error processing binlog event
org.apache.kafka.connect.errors.ConnectException: Encountered change event for table statistic.apk_info whose schema isn't known to this connector
at io.debezium.connector.mysql.AbstractReader.wrap(AbstractReader.java:241) ~[ververica-connector-mysql-1.12-vvr-3.0.0-SNAPSHOT-jar-with-dependencies.jar:1.12-vvr-3.0.0-SNAPSHOT]
at io.debezium.connector.mysql.AbstractReader.failed(AbstractReader.java:218) ~[ververica-connector-mysql-1.12-vvr-3.0.0-SNAPSHOT-jar-with-dependencies.jar:1.12-vvr-3.0.0-SNAPSHOT]
at io.debezium.connector.mysql.BinlogReader.handleEvent(BinlogReader.java:607) ~[ververica-connector-mysql-1.12-vvr-3.0.0-SNAPSHOT-jar-with-dependencies.jar:1.12-vvr-3.0.0-SNAPSHOT]
at com.github.shyiko.mysql.binlog.BinaryLogClient.notifyEventListeners(BinaryLogClient.java:1104) [ververica-connector-mysql-1.12-vvr-3.0.0-SNAPSHOT-jar-with-dependencies.jar:1.12-vvr-3.0.0-SNAPSHOT]
at com.github.shyiko.mysql.binlog.BinaryLogClient.listenForEventPackets(BinaryLogClient.java:955) [ververica-connector-mysql-1.12-vvr-3.0.0-SNAPSHOT-jar-with-dependencies.jar:1.12-vvr-3.0.0-SNAPSHOT]
at com.github.shyiko.mysql.binlog.BinaryLogClient.connect(BinaryLogClient.java:595) [ververica-connector-mysql-1.12-vvr-3.0.0-SNAPSHOT-jar-with-dependencies.jar:1.12-vvr-3.0.0-SNAPSHOT]
at com.github.shyiko.mysql.binlog.BinaryLogClient$7.run(BinaryLogClient.java:839) [ververica-connector-mysql-1.12-vvr-3.0.0-SNAPSHOT-jar-with-dependencies.jar:1.12-vvr-3.0.0-SNAPSHOT]
at java.lang.Thread.run(Thread.java:834) [?:1.8.0_102]
Caused by: org.apache.kafka.connect.errors.ConnectException: Encountered change event for table xxx.xxx whose schema isn't known to this connector
at io.debezium.connector.mysql.BinlogReader.informAboutUnknownTableIfRequired(BinlogReader.java:875) ~[ververica-connector-mysql-1.12-vvr-3.0.0-SNAPSHOT-jar-with-dependencies.jar:1.12-vvr-3.0.0-SNAPSHOT]
at io.debezium.connector.mysql.BinlogReader.handleUpdateTableMetadata(BinlogReader.java:849) ~[ververica-connector-mysql-1.12-vvr-3.0.0-SNAPSHOT-jar-with-dependencies.jar:1.12-vvr-3.0.0-SNAPSHOT]
at io.debezium.connector.mysql.BinlogReader.handleEvent(BinlogReader.java:590) ~[ververica-connector-mysql-1.12-vvr-3.0.0-SNAPSHOT-jar-with-dependencies.jar:1.12-vvr-3.0.0-SNAPSHOT]
... 5 more
```
相关链接
https://help.aliyun.com/zh/flink/support/faq-about-cdc
这个错误信息表明,在将Oracle数据库同步到Doris的过程中,Flink SQL CDC连接器遇到了一个问题,即某个字段名称不是有效的。错误来自Kafka Connect的数据处理部分,这通常意味着在数据同步过程中,某个字段的名称或数据类型与预期不符。
以下是一些可能的解决方案:
检查字段类型:
尝试简化问题:
cdc-debezium-embedded,来检查从Oracle捕获的数据。下面是一个基本的Flink SQL CDC同步示例,供参考:
报错file is not a valid field name通常是由于源表和目标表的Schema不一致导致的。尽管您提到源表和目标表结构相同,但请检查是否有字段名大小写敏感的问题,或者在Flink CDC配置中是否正确指定了表的结构。确保您使用的Flink CDC版本和目标系统适配。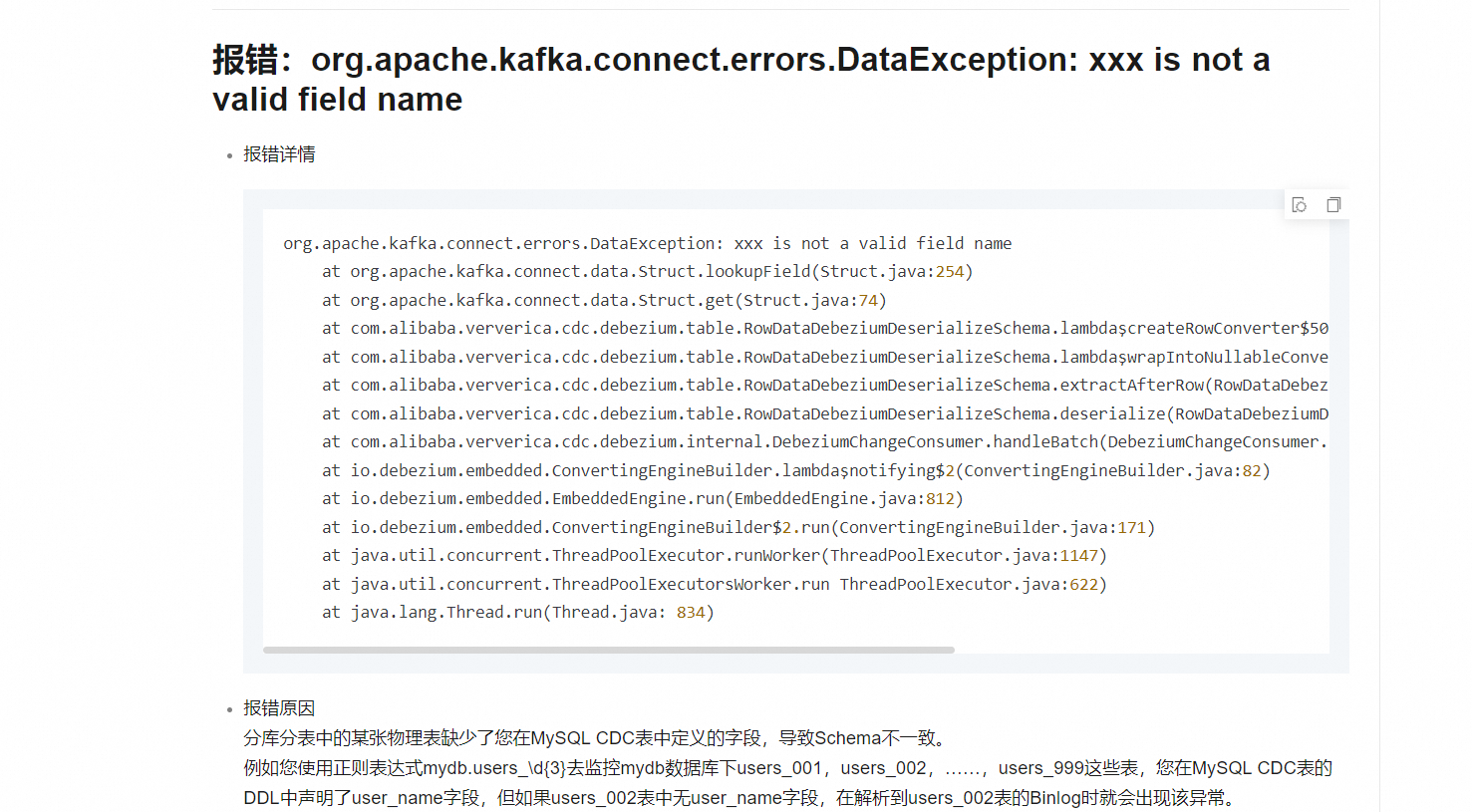
当您在使用 Flink CDC(Change Data Capture)将数据从源表同步到 Doris(一个高性能的分布式SQL数据库)时,如果遇到错误,即使源表和目标表的结构看起来是一样的,也可能存在一些问题。以下是一些排查和解决步骤:
检查表结构定义:
确保源表和目标表的字段类型完全一致。例如,源表中的 INT 类型字段在目标表中也应该是 INT,而不是 BIGINT 或其他类型。
检查是否有任何字段在源表中存在但在目标表中不存在,或者反之。
验证是否有主键、唯一索引或其他约束条件在源表和目标表之间不一致。
检查数据类型转换:
Flink CDC 在同步数据时可能需要对数据类型进行转换。确保 Flink 能够正确处理这些转换。
如果源表和目标表使用了不同的日期/时间格式,您可能需要在 Flink 作业中显式地进行格式转换。
检查字段顺序:
尽管字段顺序通常不影响数据同步,但在某些情况下,数据库可能依赖于字段顺序来解析数据。确保源表和目标表的字段顺序一致。
检查Doris表的分区和索引:
如果 Doris 表是分区表,确保同步的数据符合分区的约束条件。
检查是否有任何索引或物化视图在 Doris 表中导致同步失败。
查看详细的错误信息:
分析 Flink 任务日志和 Doris 数据库的日志,以获取更详细的错误信息。这些信息通常会指出同步失败的具体原因。
调整Flink作业配置:
检查 Flink 作业的并行度、超时设置和其他相关配置,确保它们适合您的数据量和网络条件。
如果错误与资源限制有关(如内存不足),尝试增加 Flink 任务的资源分配。
测试数据同步:
在生产环境之前,尝试在一个较小的数据集上运行 Flink CDC 作业,以验证其是否能成功同步数据。
如果测试成功,逐步增加数据量,直到达到生产规模。
这个问题可能是因为字段映射不匹配导致的。请确认MySQL CDC配置的字段名与Oracle源表中的字段名是否完全匹配。错误信息file is not a valid field name表明源表中可能存在一个名为file的字段,但在目标表中没有对应的字段。请确保源表与目标表的字段定义完全一致,包括字段名和字段顺序。如果已经确认结构相同,尝试检查和重新配置您的数据同步任务,或者更新到最新版本,如Ververica Platform 6.0.2及以上,它能处理分表中不同字段的情况。
com.ververica.cdc.connectors.shaded.org.apache.kafka.connect.errors.DataException: file is not a valid field name,表明在从Oracle同步数据到Doris的过程中,遇到了字段名称不合法的问题
应该是字段命名规范不一致,但Doris可能对字段名称有更严格的限制,比如不支持某些特殊字符或保留字作为字段名。请检查file字段名在Doris中是否符合命名规范,避免使用保留字或不支持的字符
还有就是有时字段类型虽然看似一致,但在序列化/反序列化过程中可能会因精度丢失或类型不完全匹配导致问题。确保Oracle中的file字段类型与Doris中的完全匹配
源表和目标表结构一致,也可能是由于字段名称中包含了Flink CDC或Doris不支持的字符
修改字段名称:首先推荐的做法是修改源表中的字段名称,避免使用数据库保留字或特殊字符。可以将“file”字段重命名为一个非保留字的名称,比如“file_name”。
如果无法修改源表:
在Flink SQL中使用AS关键字对字段进行重命名,以规避保留字问题。例如,如果原字段名为file,在创建sink表定义时,可以将其重命名为一个合法的字段名:
CREATE TABLE doris_sink (
`file_name` VARCHAR(255) AS `file`, -- 假设原字段类型为VARCHAR(255)
-- 其他字段定义...
) WITH (...);
检查并确认序列化/反序列化设置:确保Flink作业中的序列化器和反序列化器配置正确,以适应源表和目标表的数据结构。
在处理FlinkCDC同步到Doris时,如果遇到错误提示“file is not a valid field name”,并且源表与目标表结构相同,可以采取以下步骤来解决问题:
检查字段名称:
确保所有字段名称都不包含特殊字符或保留字,如"file"。根据错误信息,"file"不是一个有效的字段名。请检查源表和目标表的字段名称,确保它们都是有效的。
映射字段名称:
如果源表和目标表的字段名称不同,需要在同步过程中进行字段映射。请检查您的同步配置,确保所有字段都已正确映射。
更新配置:
如果您使用的是配置文件来定义同步规则,请确保配置文件是最新的,并且已经包含了所有必要的字段映射。
重新编译代码:
如果您在代码中硬编码了字段名称,请确保重新编译并部署了包含最新更改的代码。
日志分析:
查看FlinkCDC和Doris的日志,寻找可能的错误信息或警告,这些信息可能会提供更多关于错误的线索。
社区支持:
如果问题仍然存在,可以考虑寻求社区支持。您可以在相关的技术论坛或社区提问,提供详细的错误信息和您已经尝试过的解决方法。
版本兼容性:
确保您使用的FlinkCDC连接器版本与Doris版本兼容。不兼容的版本可能会导致同步问题。
权限验证:
确认用于连接源数据库和目标数据库的用户具有足够的权限来读取源数据和写入目标数据。
总的来说,通过上述步骤,您应该能够定位并解决FlinkCDC同步到Doris时遇到的“file is not a valid field name”错误。
在处理FlinkCDC同步到Doris时,如果源表和目标表结构一样但仍然报错,可以按照以下步骤进行排查和解决:
检查字段类型:
确认源表和目标表中的每个字段的数据类型是否完全相同。例如,VARCHAR(255) 和 STRING 在某些情况下可能被视为不同的类型。
字段顺序:
确保源表和目标表中字段的顺序一致。某些数据库对字段顺序敏感,不一致可能导致错误。
主键和唯一键:
检查源表和目标表的主键和唯一键是否相同。如果主键或唯一键在两个表中的定义不同,可能会导致同步失败。
数据格式:
如果表中包含日期或时间字段,确保源表和目标表中这些字段的格式一致。
索引和约束:
检查源表和目标表中的索引和约束是否一致。不一致的索引或约束也可能导致同步问题。
字符集和排序规则:
确保源表和目标表使用相同的字符集和排序规则。字符集和排序规则的不一致可能会导致数据存储和检索的问题。
权限问题:
确认用于连接源表和目标表的用户具有足够的权限来读取和写入数据。
日志和详细错误信息:
查看FlinkCDC和Doris的日志,获取更详细的错误信息。这有助于定位具体的错误原因。
配置检查:
检查FlinkCDC的配置是否正确,包括连接器、转换器等设置。确保配置与实际表结构和需求匹配。
版本兼容性:
确保FlinkCDC和Doris的版本兼容。有时候新版本的软件可能会有不兼容的改动,导致同步失败。
网络问题:
检查网络连接是否正常,确保源表和目标表之间的通信没有受到阻碍。
通过以上步骤逐一排查,应该能够找到并解决同步过程中出现的问题。如果问题依然存在,可以考虑在社区论坛或相关技术支持渠道寻求帮助,提供详细的错误日志和配置信息,以便获得更有针对性的解决方案。
在使用 FlinkCDC 同步数据到 Doris 时遇到错误,首先需要查看具体的错误信息来确定问题的原因。常见的错误类型包括但不限于:
针对这些可能的问题,可以采取以下步骤进行排查和解决:
如果你能提供具体的错误信息,我可以帮助你更准确地定位问题并提出解决方案。
在使用 Flink CDC (Change Data Capture) 连接器将 Oracle 数据同步到 Doris 时,遇到 com.ververica.cdc.connectors.shaded.org.apache.kafka.connect.errors.DataException: file is not a valid field name 错误,这通常意味着数据处理过程中遇到了无效的字段名称。这个错误可能由以下几个原因引起:
字段名冲突:如果源表中有名为 file 的字段,而 Kafka Connect 的内部逻辑中已经定义了 file 作为保留关键字或特殊用途的字段名,这可能会导致冲突。
字段映射问题:即使源表和目标表结构相同,但在数据转换过程中可能存在某些字段映射不正确的问题。
数据格式问题:在数据序列化或反序列化过程中,可能由于某种原因导致字段名被错误地解析或生成。
file 的字段,可以考虑将其重命名以避免与 Kafka Connect 内部关键字冲突。如果你需要在 Flink CDC 中自定义字段映射,可以参考以下示例代码:
// 创建 DebeziumJsonDeserializationSchema 并设置字段映射
Properties props = new Properties();
props.setProperty("decimal.handling.mode", "string");
DebeziumJsonDeserializationSchema<RowData> deserializer = new DebeziumJsonDeserializationSchema<>(true, props);
// 使用自定义的 DeserializationSchema
FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<>(
topic,
new SimpleStringSchema(),
properties
);
DataStream<RowData> stream = env.addSource(kafkaConsumer)
.map(new MapFunction<String, RowData>() {
@Override
public RowData map(String value) throws Exception {
// 在这里进行字段映射和转换
return deserializer.deserialize(value.getBytes(StandardCharsets.UTF_8));
}
});
// 继续处理流数据...
kafkacat 或者 kafka-console-consumer 来查看 Kafka 中的数据内容,确保数据格式正确。通过上述方法,你应该能够找到并解决 file is not a valid field name 错误的原因。如果问题仍然存在,建议检查更详细的错误日志,并可能需要进一步调试 Flink CDC 和 Kafka Connect 的配置。
Flink CDC中File is not a valid field name 遇到过没?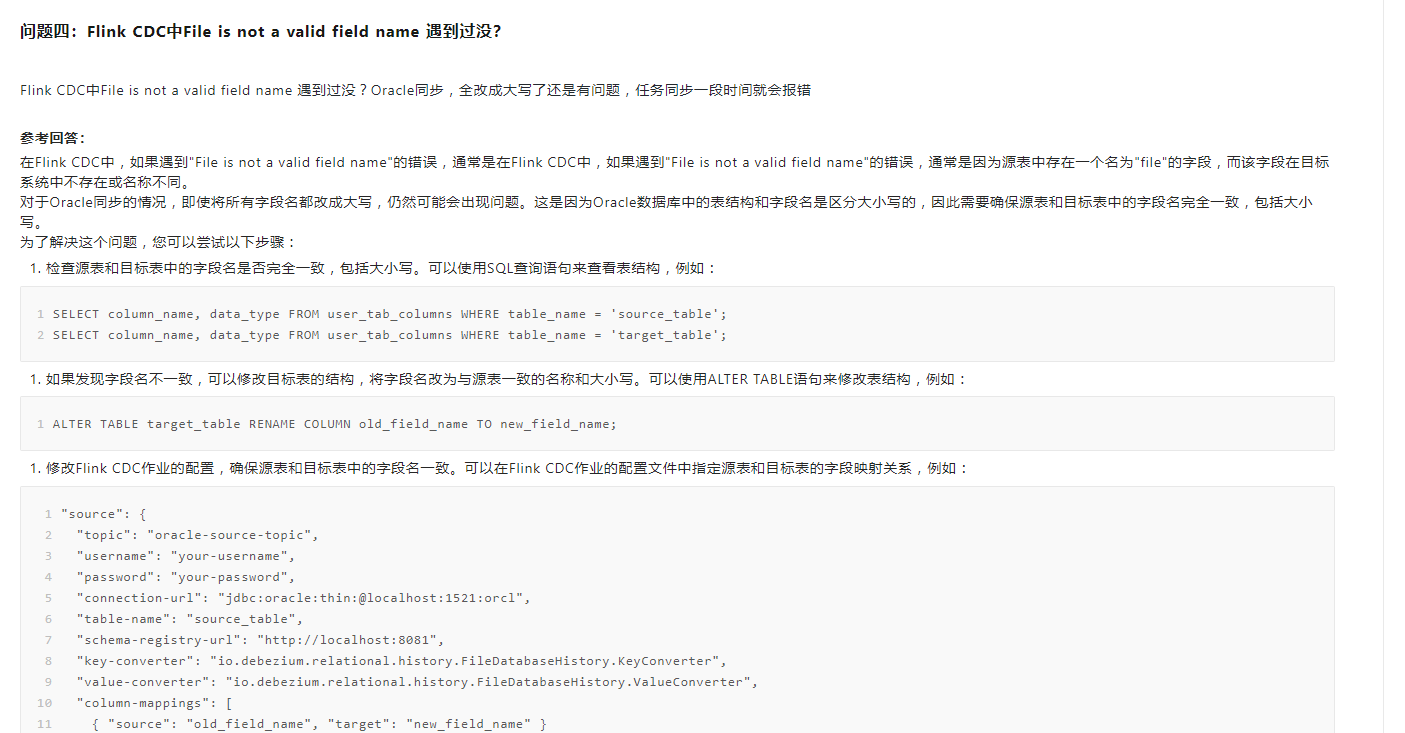
Flink CDC中File is not a valid field name 遇到过没?Oracle同步,全改成大写了还是有问题,任务同步一段时间就会报错
参考回答:
在Flink CDC中,如果遇到"File is not a valid field name"的错误,通常是在Flink CDC中,如果遇到"File is not a valid field name"的错误,通常是因为源表中存在一个名为"file"的字段,而该字段在目标系统中不存在或名称不同。
对于Oracle同步的情况,即使将所有字段名都改成大写,仍然可能会出现问题。这是因为Oracle数据库中的表结构和字段名是区分大小写的,因此需要确保源表和目标表中的字段名完全一致,包括大小写。
为了解决这个问题,您可以尝试以下步骤:
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。