
flink cdc同步数据的资源,比如内存,cpu这些有什么参考依据吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
这个就是相关的cpu还有内存的依据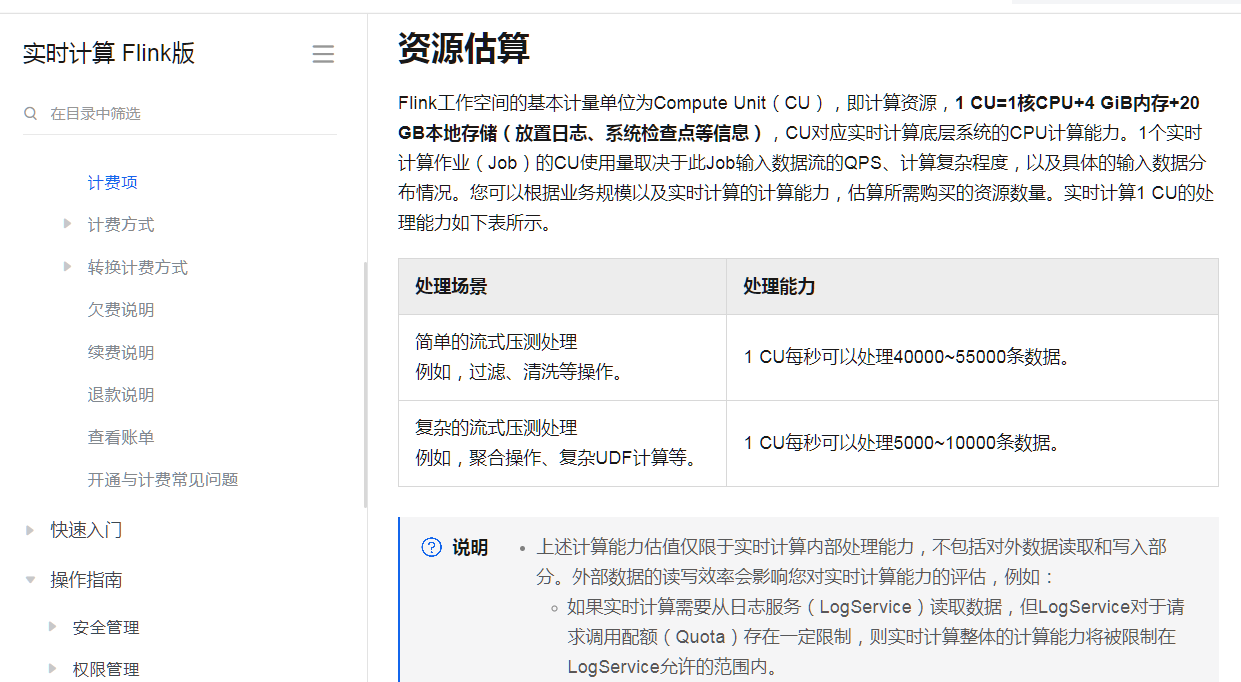
1CU每秒可以处理40000~55000条数据。
参考链接
https://help.aliyun.com/zh/flink/product-overview/billable-items?spm=a2c6h.13066369.0.0.2b6245221KR3R3
回答不易请采纳
生成 SSH 密钥对:如果还没有 SSH 密钥对,你需要生成一个。这通常涉及到使用 ssh-keygen 命令。
配置 MongoDB:确保 MongoDB 实例配置为接受 SSH 连接,并且 SSH 服务正在运行。
配置 Flink CDC 连接器:在 Flink 应用程序中,你需要配置 MongoDB CDC 连接器以使用 SSH 连接。这通常涉及到设置连接属性,如主机名、端口、用户名、SSH 私钥路径等。
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.mongodb.MongoDBSource;
public class MongoDBCDCExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 假设的配置参数,需要根据实际的 MongoDB CDC 连接器文档来设置
Properties flinkProperties = new Properties();
flinkProperties.setProperty("mongodb.host", "your-mongodb-host");
flinkProperties.setProperty("mongodb.port", "your-mongodb-port");
flinkProperties.setProperty("mongodb.username", "your-ssh-username");
flinkProperties.setProperty("mongodb.ssh.privateKeyPath", "/path/to/your/private/key");
// 其他必要的配置...
MongoDBSource<String> mongoSource = new MongoDBSource<>(flinkProperties);
env.addSource(mongoSource)
.addSink(...);
env.execute("MongoDB CDC Example");
}
}
在使用Flink CDC进行数据同步时,资源需求如内存和CPU的配置主要受到几个因素的影响,包括但不限于数据流的吞吐量(QPS)、计算复杂度以及数据的存储与处理需求。以下是一些参考依据和建议:
基础资源配置:
内存配置:

综上所述,Flink CDC同步数据时的资源配置应基于实际数据流特性、计算复杂度及状态管理需求综合考量。通过监控作业运行状态,适时调整资源分配,可以达到最优的性能与成本效益。
相关链接
计费项 资源估算 https://help.aliyun.com/zh/flink/product-overview/billable-items
Flink CDC(Change Data Capture)是Apache Flink的一个扩展,用于捕获数据库中的变更数据,并实时地将这些变更同步到其他系统。在配置Flink CDC作业的资源时,以下是一些参考依据来决定合适的内存、CPU等资源分配:

Flink CDC 同步数据的资源消耗主要取决于以下几个因素:
数据量:同步的数据量越大,所需的内存和 CPU 资源越多。
并行度:Flink 任务的并行度越高,可以同时处理更多的数据,从而减少资源消耗。
网络带宽:数据传输速度越快,同步过程所需的时间越短,从而减少资源消耗。
系统配置:Flink 集群的配置,如 JVM 堆大小、垃圾回收策略等,也会影响资源消耗。
为了评估 Flink CDC 同步数据的资源消耗,可以参考以下方法:
监控工具:使用 Flink 自带的 Web UI 或者第三方监控工具(如 Prometheus、Grafana 等)来查看任务的 CPU 和内存使用情况。
性能测试:在生产环境中进行性能测试,模拟不同的数据量和并发场景,观察资源消耗情况。
经验值:根据以往的项目经验和类似场景,预估资源消耗。
需要注意的是,资源消耗可能会随着 Flink 版本的更新而发生变化,因此建议查阅官方文档以获取最新的性能指标和优化建议。
在Flink CDC同步数据时,资源如内存和CPU的使用情况是确保作业高效运行的重要因素。以下是一些参考依据:
资源调整:确保Flink作业所需的计算和内存资源充足。可以通过增加TaskManager的数量或调整其配置来提供更多的计算和内存资源。同时,监控作业运行期间的资源使用情况,以避免资源耗尽导致性能下降或任务失败。
并发度设置:适当调整并发度(parallelism)来平衡作业的吞吐量和资源消耗。较高的并发度可能会增加吞吐量,但也会占用更多的计算和网络资源。根据实际场景和硬件资源,选择合适的并发度。
数据传输优化:检查源数据库和目标系统之间的网络连接和带宽。确保网络稳定,并通过调整并行度、调节数据传输的批处理大小等方式来优化数据传输性能。
Checkpoint配置:在进行整库同步时,Checkpoint的频率和数据量会增加,可能会导致Checkpoint操作变慢。可以适当调整Checkpoint相关的配置,包括Checkpoint间隔、并发数、超时时间等,以平衡数据处理和Checkpoint操作之间的资源分配。
增量同步:考虑将整库同步任务拆分为多个数据切片,并采用增量同步的方式进行。通过设定合适的切片范围和顺序,将整个库的数据按照一定的规则进行增量同步,降低整体负载和资源需求。
实时物化视图:用户还可以借助Flink CDC source实现实时物化视图,结合下游Flink作业处理逻辑实现更丰富的业务场景。这可能会影响到资源的使用,需要根据实际情况进行调整。
YAML API定义:Flink CDC API使用YAML语法定义数据同步任务,用户只需定义同步数据源和数据目标端即可快速搭建起一个实时同步流水线。这有助于更好地管理和优化资源使用。
CLI工具:Flink CDC提供的CLI(flink-cdc.sh)进一步简化了用户提交Flink CDC任务的流程。通过CLI,用户可以更容易地管理Flink CDC作业,从而间接影响资源的使用和管理。
总的来说,Flink CDC同步数据时的资源使用需要综合考虑多个因素,包括作业配置、网络环境、数据切片策略以及API使用等。通过合理调整这些因素,可以有效地管理和优化资源使用,确保Flink CDC作业的高效运行。
一、内存资源评估
总数据量:
评估需要同步的数据总量,包括全量数据和增量数据。这有助于确定在处理过程中所需的最大内存量。
状态管理:
Flink CDC在处理数据时,会维护一定的状态信息。这些状态信息需要占用内存资源。因此,需要考虑状态管理所需的内存量。
堆内存配置:
通常建议将Flink的堆内存配置为总内存的50%~75%,以确保有足够的内存用于数据处理和状态管理。
并发任务数:
如果Flink CDC需要同时处理多个并发任务,每个任务都会占用一定的内存资源。因此,并发任务数也是评估内存需求的重要因素。
二、CPU资源评估
数据处理复杂度:
评估数据处理的复杂度,包括数据过滤、转换、聚合等操作。这些操作对CPU的计算能力有一定的要求。
并行度设置:
Flink支持并行执行任务,并行度设置会影响CPU资源的利用。根据数据处理的需求,合理设置并行度可以提高CPU的利用率。
吞吐量需求:
评估需要处理的数据吞吐量,即每秒需要处理的数据量。这有助于确定所需的CPU计算能力。
Flink CDC同步数据时,资源需求如内存和CPU取决于数据量、变更频率及并行度。通常,建议为每个Flink任务分配至少1-2个CPU核心和2-4GB内存。在高负载场景下,可能需要更多资源。实际部署时,应根据测试结果调整这些参数以达到最佳性能和资源利用率。此外合理设置并行度也能帮助优化资源使用。
在使用 Apache Flink CDC(Change Data Capture)进行数据同步时,资源的分配(如内存、CPU 等)是非常关键的,因为这直接影响到同步任务的性能和稳定性。以下是一些参考依据和最佳实践,帮助你合理配置 Flink CDC 任务的资源:
parallelism.default 配置项设置默认的并行度。taskmanager.memory.process.size 或 taskmanager.heap.size 进行配置。state.backend.rocksdb.memory.managed 进行配置。-Xmx 和 -Xms 设置 JVM 的最大和初始堆内存大小。
taskmanager.numberOfTaskSlots 和 taskmanager.cpu.cores 进行配置。以下是一个示例配置,假设你需要同步大量数据,并且希望充分利用资源:
# flink-conf.yaml
jobmanager.memory.process.size: 4096m
taskmanager.memory.process.size: 8192m
taskmanager.numberOfTaskSlots: 4
taskmanager.cpu.cores: 4
parallelism.default: 4
# RocksDB 状态后端配置
state.backend: rocksdb
state.backend.rocksdb.memory.managed: true
state.backend.rocksdb.block.cache-size: 256m
通过以上方法和参考依据,你可以更合理地配置 Flink CDC 任务的资源,确保任务能够高效稳定地运行。
在快照操作期间,连接器将查询每个包含的表,以生成该表中所有行的读取事件。 此参数确定 MySQL 连接是否将表的所有结果拉入内存(速度很快,但需要大量内存), 或者结果是否需要流式传输(传输速度可能较慢,但适用于非常大的表)。 该值指定了在连接器对结果进行流式处理之前,表必须包含的最小行数,默认值为1000。将此参数设置为0以跳过所有表大小检查,并始终在快照期间对所有结果进行流式处理。

实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

