
flinkcdc整库同步,如果只将该表加到--including-tables参数中,能正常同步;如果去掉--including-tables也就是整库同步就报下面的错?这个表数据量比其它表大很多,千万级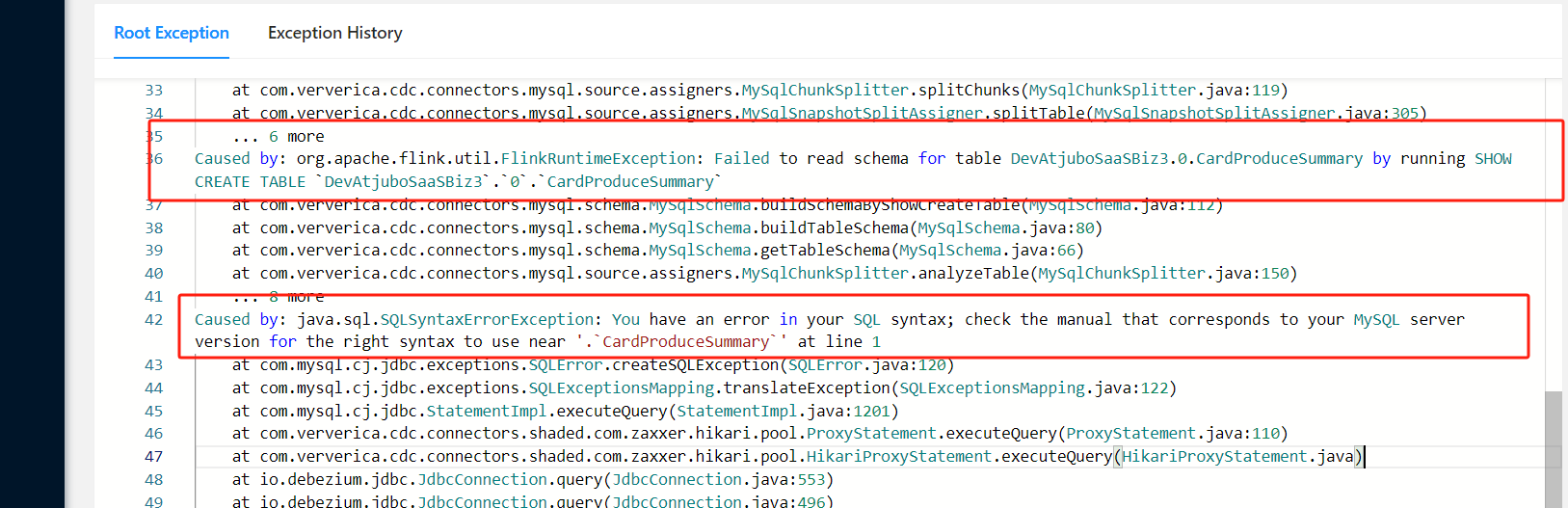
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
当你遇到整库同步时出现问题,而仅指定个别表时却能正常工作的场景时,这可能是由于几个原因造成的。在这种情况下,错误信息非常重要,因为它可以帮助我们诊断问题所在。不过,您没有提供具体的错误信息,所以我将尝试给出一些常见的可能性及其解决方法。
首先,让我们假设错误与数据量较大有关。在 Apache Flink 的 CDC (Change Data Capture) 功能中,如果某个表的数据量非常大,可能会出现以下几种情况:
针对这些问题,可以采取以下步骤来解决:
parallelism 参数以更好地利用集群资源。scan.incremental.snapshot.interval) 来减少单次快照的大小。--including-tables 参数这里是一个示例配置,假设您想要同步整个数据库,但特别指定了一个大表(例如 large_table),以确保它能够被正确处理:
{
"job": {
"content": [
{
"reader": {
"name": "mysql-cdc",
"parameter": {
"username": "your_username",
"password": "your_password",
"servers": "localhost:3306",
"database-list": "your_database",
"table-list": ["large_table"], // 显式列出大表
"table-pattern": "your_database.*", // 用于自动发现其他表
"scan.startup.mode": "initial",
"scan.incremental.snapshot.interval": "1h" // 设置增量快照间隔
}
},
"writer": {
"name": "console",
"parameter": {}
}
}
],
"setting": {
"speed": "fast",
"error-limit": {
"record": "1"
},
"resume-from-failure": true
}
}
}
如果以上建议无法解决问题,请提供具体的错误信息,以便进一步诊断和解决。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

 -此回答整理自钉群“Flink CDC 社区”
-此回答整理自钉群“Flink CDC 社区”