如何使用Python调用MaxCompute上的数据?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
要用python获取MaxCompute上的数据那就先把PyODPS装上
pip install pyodps
执行如下命令检查安装是否成功。若无返回值和报错信息表示安装成功。
python -c "from odps import ODPS"
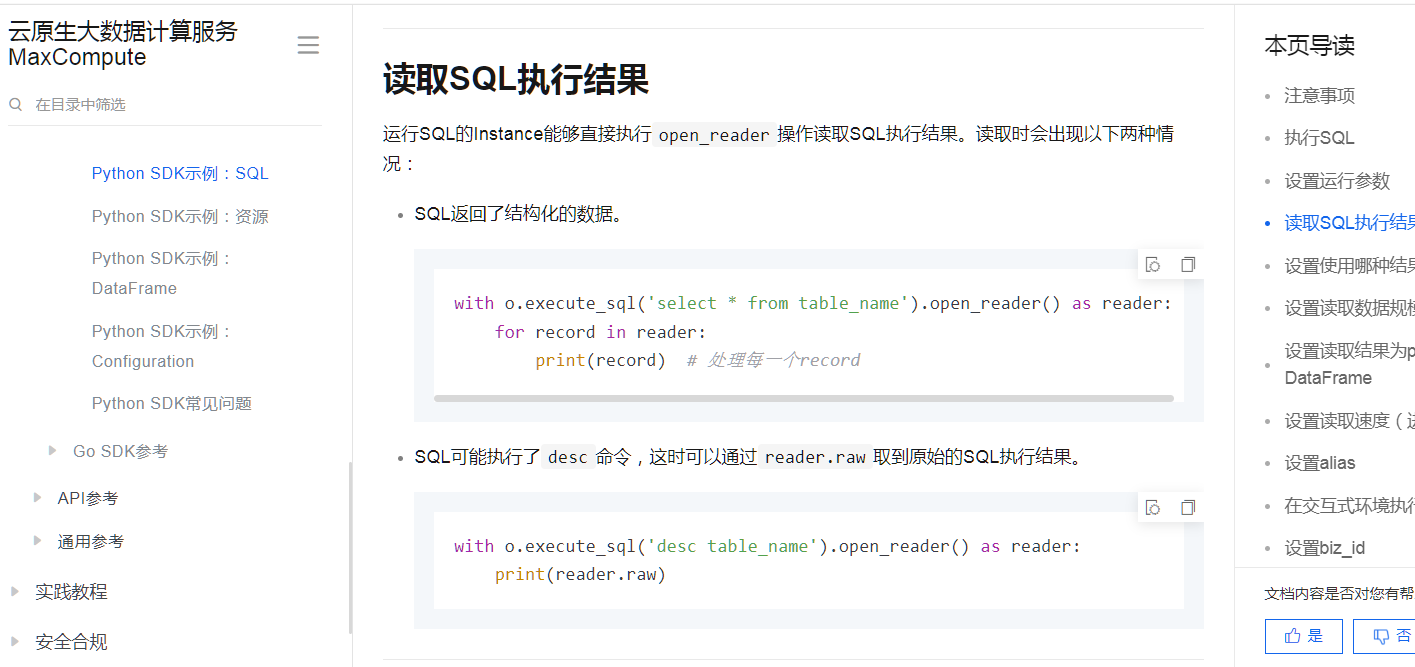
接着就可以通过SQL语句获取数据了
with o.execute_sql('select * from table_name').open_reader() as reader:
for record in reader:
print(record) # 处理每一个record
回答不易请采纳
要使用Python调用MaxCompute上的数据,您可以使用阿里云提供的PyODPS库。以下是使用Python调用MaxCompute数据的步骤:
安装PyODPS:
首先,您需要在您的Python环境中安装PyODPS库。可以使用pip命令来安装:
pip install pyodps
配置访问凭证:
在使用PyODPS之前,您需要配置访问MaxCompute的凭证。这通常包括AccessKey ID和AccessKey Secret。您可以在阿里云控制台中找到这些信息。
初始化MaxCompute项目:
使用您的AccessKey ID、AccessKey Secret以及MaxCompute项目的URL来初始化一个MaxCompute项目对象。例如:
from odps import ODPS
access_id = 'your-access-key-id'
secret_access_key = 'your-secret-access-key'
project = 'your-project-name'
endpoint = 'http://service.cn.maxcompute.aliyun.com/api'
o = ODPS(access_id, secret_access_key, project, endpoint)
执行SQL查询:
使用MaxCompute项目对象,您可以执行SQL查询并获取结果。例如,如果您想查询名为my_table的表中的所有数据,可以这样做:
with o.execute_sql('SELECT * FROM my_table').open_reader() as reader:
for record in reader:
print(record)
处理查询结果:
查询结果可以通过迭代器的方式读取,每条记录是一个元组,包含了表中的一行数据。
关闭连接:
完成数据操作后,确保关闭与MaxCompute的连接。
以上是使用Python调用MaxCompute数据的基本步骤。根据您的具体需求,您可能还需要进行更复杂的数据处理或分析。
PyODPS是MaxCompute的Python SDK,能够方便地使用Python语言与MaxCompute进行交互和数据处理。通过该SDK,可以更高效地开发MaxCompute任务、进行数据分析和管理MaxCompute资源。本文为您介绍PyODPS的使用和常见方法。
参考文档https://help.aliyun.com/zh/maxcompute/user-guide/overview-32
要使用Python调用阿里云MaxCompute上的数据,你可以使用pyodps库。pyodps是阿里云官方为MaxCompute开发的Python SDK,它允许你通过Python代码来执行SQL查询、管理资源等操作。下面是使用pyodps的基本步骤和示例代码。
首先需要安装pyodps库。可以通过pip来安装:
pip install pyodps
你需要配置访问MaxCompute所需的凭证信息。通常包括AccessKey ID、AccessKey Secret以及项目所在的Endpoint。
可以设置以下环境变量来避免在代码中直接写入敏感信息:
ODPS_ENDPOINT:你的MaxCompute服务地址。ODPS_ACCESS_ID:你的阿里云AccessKey ID。ODPS_ACCESS_KEY:你的阿里云AccessKey Secret。ODPS_PROJECT:你的MaxCompute项目的名称。或者,你也可以直接在Python代码中进行配置。
下面是一个简单的示例,展示如何使用pyodps从MaxCompute中读取数据并打印出来:
from odps import ODPS
# 创建ODPS对象
# 如果已经设置了环境变量,则可以直接创建ODPS对象
odps = ODPS()
# 或者手动指定参数
# odps = ODPS('<your-access-id>', '<your-access-key>', '<your-project-name>', endpoint='<your-endpoint>')
# 执行SQL查询
sql = "SELECT * FROM your_table LIMIT 100" # 替换为你的表名和查询语句
with odps.execute_sql(sql).open_reader() as reader:
for record in reader:
print(record) # 每条记录都是一个字典
# 如果你想将结果转换成Pandas DataFrame,可以这样做
import pandas as pd
result = []
with odps.execute_sql(sql).open_reader() as reader:
for record in reader:
result.append(record.values)
df = pd.DataFrame(result, columns=reader._schema.names)
print(df)
对于大数据量的情况,建议使用Tunnel功能来下载数据,这样可以提高效率。这里是如何使用Tunnel的一个例子:
from odps import ODPS
from odps.tunnel import TableTunnel
# 创建ODPS和TableTunnel对象
odps = ODPS()
tunnel = TableTunnel(odps)
# 获取表
table = odps.get_table('your_table') # 替换为你的表名
# 开始下载会话
download_session = tunnel.create_download_session(table.name)
# 下载整个表的数据
with download_session.open_record_reader(0, download_session.count) as reader:
while True:
records = reader.read(batch_size=100) # 一次读取多条记录
if not records:
break
for record in records:
print(record) # 处理每条记录
pyodps还提供了DataFrame API,类似于Pandas DataFrame,可以更方便地进行数据处理。
from odps.df import DataFrame
# 创建ODPS对象
odps = ODPS()
# 读取表数据到DataFrame
df = DataFrame(odps.get_table('your_table'))
# 执行SQL-like操作
filtered_df = df[df['column_name'] > 10]
# 显示前几行数据
print(filtered_df.head())
# 将DataFrame写回MaxCompute
filtered_df.persist('new_table', partition='partition_spec', lifecycle=7)
通过以上步骤,你可以使用Python和pyodps库有效地调用和处理MaxCompute上的数据。根据你的具体需求,你还可以进一步探索pyodps的其他功能,如上传数据、更新表结构等。
PyODPS是MaxCompute的Python SDK,能够方便地使用Python语言与MaxCompute进行交互和数据处理。通过该SDK,可以更高效地开发MaxCompute任务、进行数据分析和管理MaxCompute资源。本文为您介绍PyODPS的使用和常见方法。
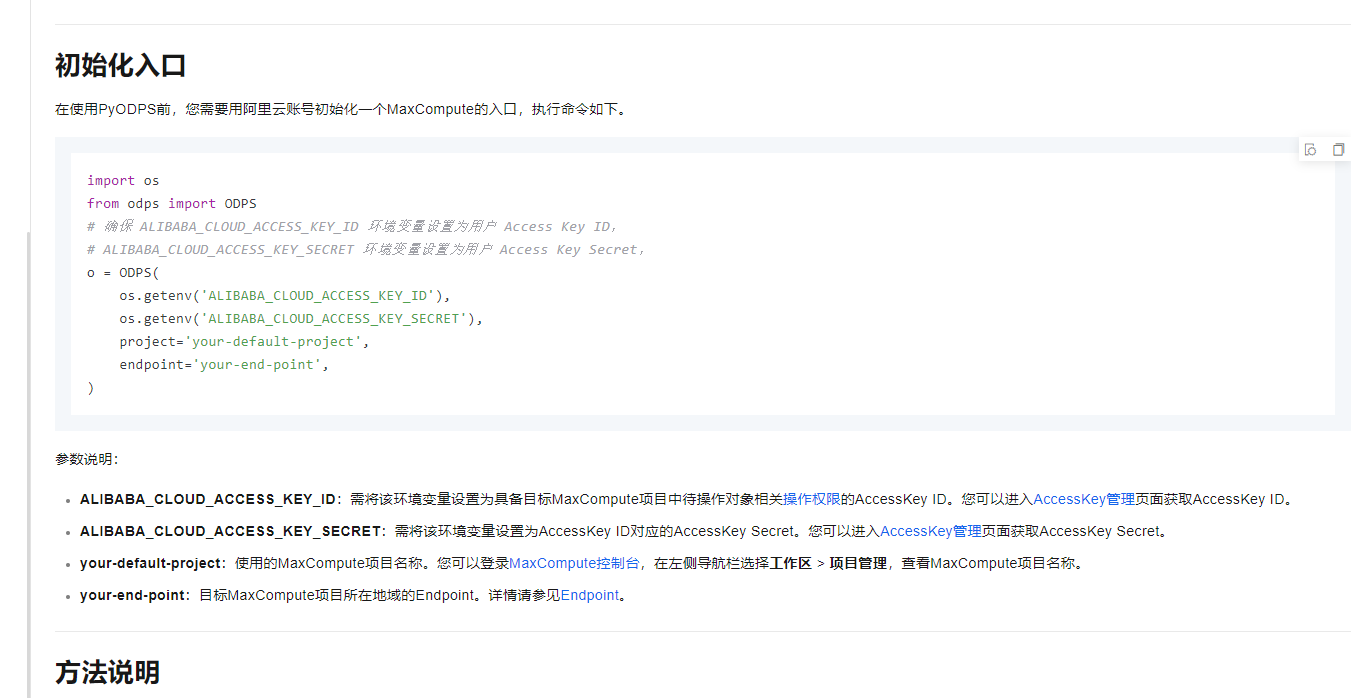
参考文档https://help.aliyun.com/zh/maxcompute/user-guide/overview-32