如何在MaxCompute中,选择去重后的字段?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
要在MaxCompute中选择去重后的字段,可以使用DISTINCT关键字。例如,若要查询sale_detail表中不包含重复region的值,可以使用如下SQL:
这将返回region列中去除重复值的结果。DISTINCT关键字作用于SELECT语句中的所有列集合,而非单个列。
就用distinct就可以了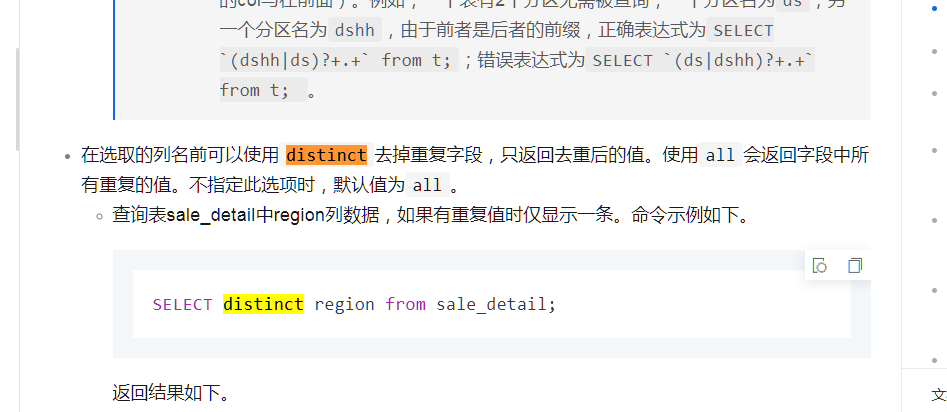
参考链接
https://help.aliyun.com/zh/maxcompute/user-guide/select-syntax#section-xwx-cv2-ggb
回答不易请采纳
要在MaxCompute中选择去重后的字段,可以使用DISTINCT关键字。例如,若要查询sale_detail表中region列去重,命令如下:
这将返回去重后的region值。DISTINCT的作用域是SELECT的列集合,对多列去重需为:
这将返回去重后的region和sale_date组合。请注意,DISTINCT不能与GROUP BY一起使用。
在MaxCompute中,您可以使用SQL语句来选择去重后的字段。以下是一个示例:
假设您有一个名为my_table的表,其中包含一个名为my_column的字段,您想要选择该字段中去重后的值。您可以使用以下SQL查询来实现这一点:
sql
复制代码
SELECT DISTINCT my_column
FROM my_table;
这条SQL语句使用了DISTINCT关键字,它会返回my_column字段中所有唯一的值,从而去除重复项。
如果您需要对多个字段进行去重,可以在SELECT DISTINCT后面列出这些字段
SELECT DISTINCT column1, column2
FROM my_table;
这将返回column1和column2组合后的所有唯一行。
在MaxCompute中处理数据时,如果需要从表中选取某一字段的去重值,可以使用SQL语句中的DISTINCT关键字。这可以帮助我们从大数据集中提取唯一的记录。例如,假设有一个名为orders的表,其中包含一个名为order_id的字段,我们想要获取所有唯一的订单ID,可以执行如下的SQL查询:
这条命令会返回orders表中所有的唯一order_id列表。
在MaxCompute中选择去重后的字段,可以使用多种方法,以下是一些常见的方式:
使用 DISTINCT 关键字
DISTINCT 关键字用于从指定集合中消除重复的元组。在MaxCompute中,如果你想选择某个字段去重后的结果,可以直接在SELECT语句中使用DISTINCT。例如:
注意事项
性能考虑:在使用DISTINCT或COLLECT_SET进行去重时,特别是在处理大数据量时,需要注意性能问题。可能需要考虑对表进行分区、索引或其他优化措施来提高查询效率。
空值处理:在MaxCompute中,如果某列包含NULL值,并且你希望在进行去重时忽略这些NULL值,那么DISTINCT和COLLECT_SET函数都可以满足你的需求。但是,如果你希望对NULL值进行特殊处理(例如将其视为一个特定的值),则需要使用其他方法。
数据类型:确保你正在去重的字段具有适当的数据类型。例如,如果你正在对字符串字段进行去重,那么需要确保该字段中的值是以你期望的方式进行比较的(例如,区分大小写或不区分大小写)。
综上所述,在MaxCompute中选择去重后的字段可以使用DISTINCT关键字或COLLECT_SET函数。具体选择哪种方法取决于你的具体需求和场景。
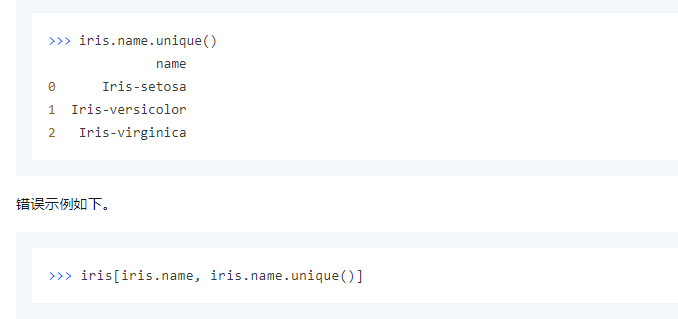
去重
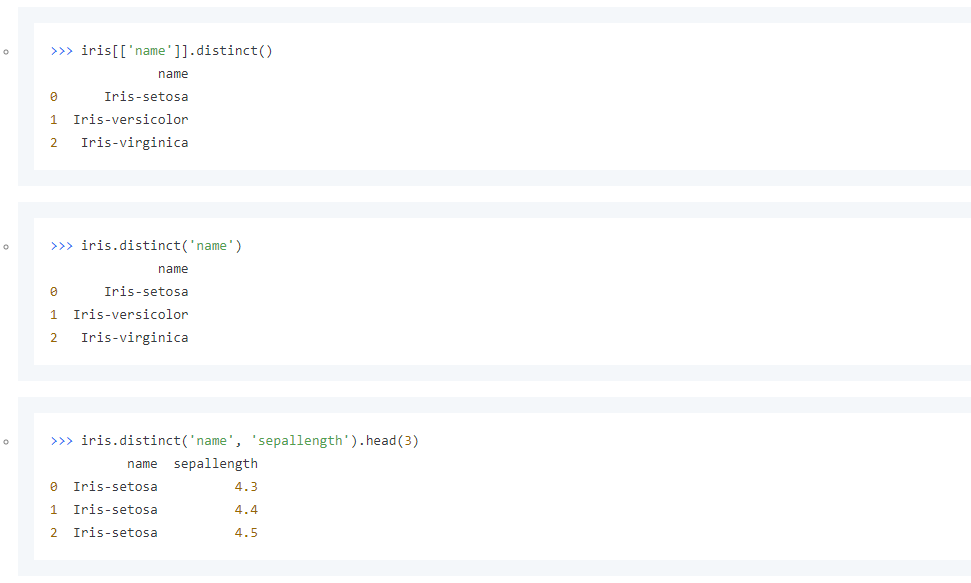
您可以通过以下三种方式调用distinct方法,对Collection进行去重操作。
iris[['name']].distinct()
name
0 Iris-setosa
1 Iris-versicolor
2 Iris-virginica
iris.distinct('name')
name
0 Iris-setosa
1 Iris-versicolor
2 Iris-virginica
iris.distinct('name', 'sepallength').head(3)
name sepallength
0 Iris-setosa 4.3
1 Iris-setosa 4.4
2 Iris-setosa 4.5
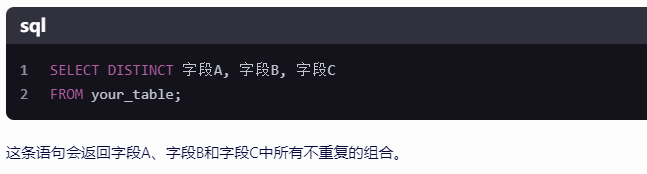
在阿里云的MaxCompute(原名ODPS)中,你可以使用SQL语句来选择去重后的字段。去重操作通常使用DISTINCT关键字来实现。以下是一些常见的去重操作示例:
如果你只需要选择一个字段的去重值,可以直接使用SELECT DISTINCT语句。
SELECT DISTINCT column_name
FROM table_name;
如果你需要选择多个字段的去重组合,可以在SELECT DISTINCT语句中列出这些字段。
SELECT DISTINCT column1, column2, column3
FROM table_name;
如果你希望选择表中所有字段的去重组合,可以使用*通配符。
SELECT DISTINCT *
FROM table_name;
你还可以结合其他条件来进行去重操作,例如使用WHERE子句来过滤数据。
SELECT DISTINCT column1, column2
FROM table_name
WHERE some_condition;
GROUP BY进行去重有时候,你可能需要对某些字段进行分组,并选择每个分组中的第一条记录。虽然这不是严格的去重,但可以达到类似的效果。
SELECT column1, column2, MAX(column3) AS max_column3
FROM table_name
GROUP BY column1, column2;
假设你有一个名为user_logs的表,包含以下字段:user_id, event_time, event_type。你想选择每个用户的唯一事件类型。
-- 选择每个用户的唯一事件类型
SELECT DISTINCT user_id, event_type
FROM user_logs;
-- 选择每个用户的最新事件类型
SELECT user_id, event_type, MAX(event_time) AS latest_event_time
FROM user_logs
GROUP BY user_id, event_type;
通过以上方法,你可以在MaxCompute中选择去重后的字段。根据你的具体需求和数据结构,选择合适的方法进行去重操作。如果有更多具体需求或遇到问题,可以参考MaxCompute的官方文档或联系客户服务获取帮助。
要在MaxCompute中选择去重后的字段,可以使用DISTINCT关键字。例如,若要查询表sale_detail中region列去重后的数据,命令如下:
这将返回去重后的region值。DISTINCT作用于SELECT的所有列,对多列去重需谨慎,因为DISTINCT是对整个行集合去重,而不仅仅是单个列。