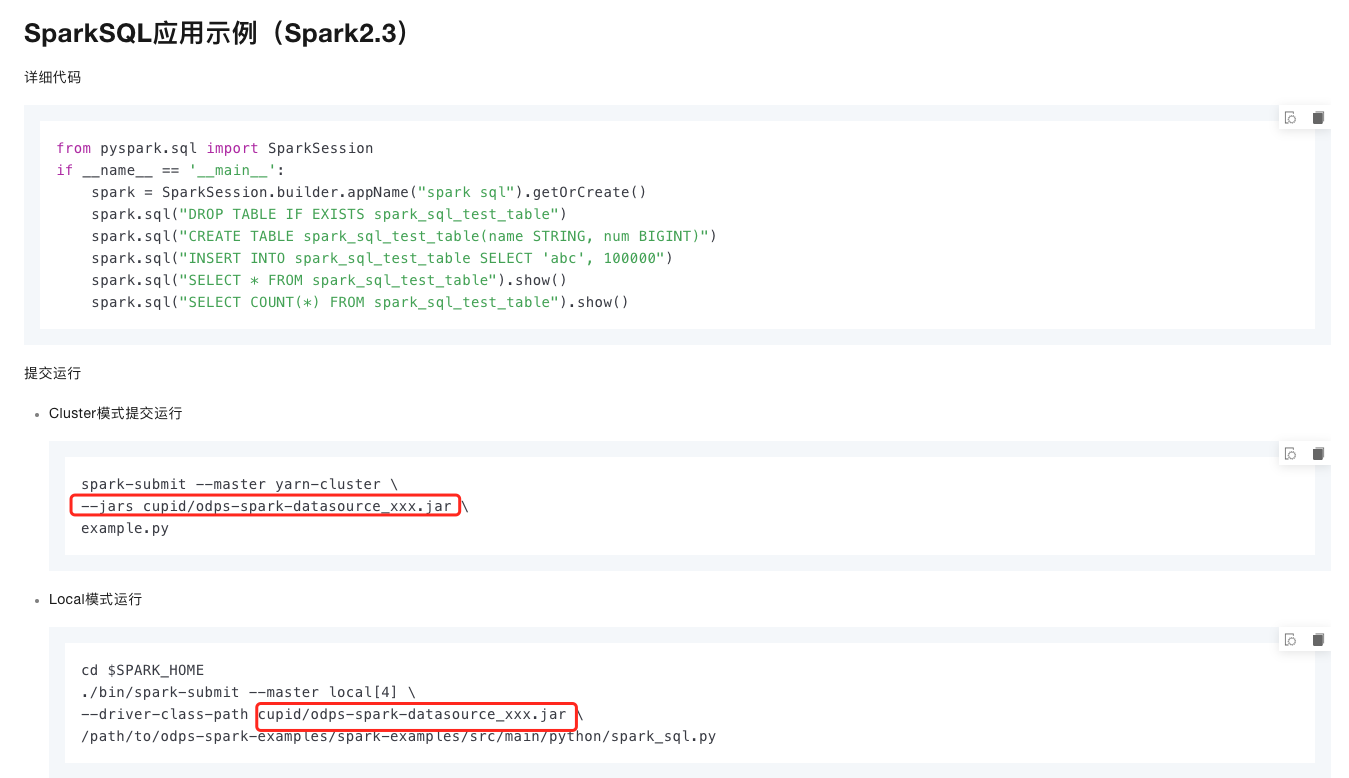
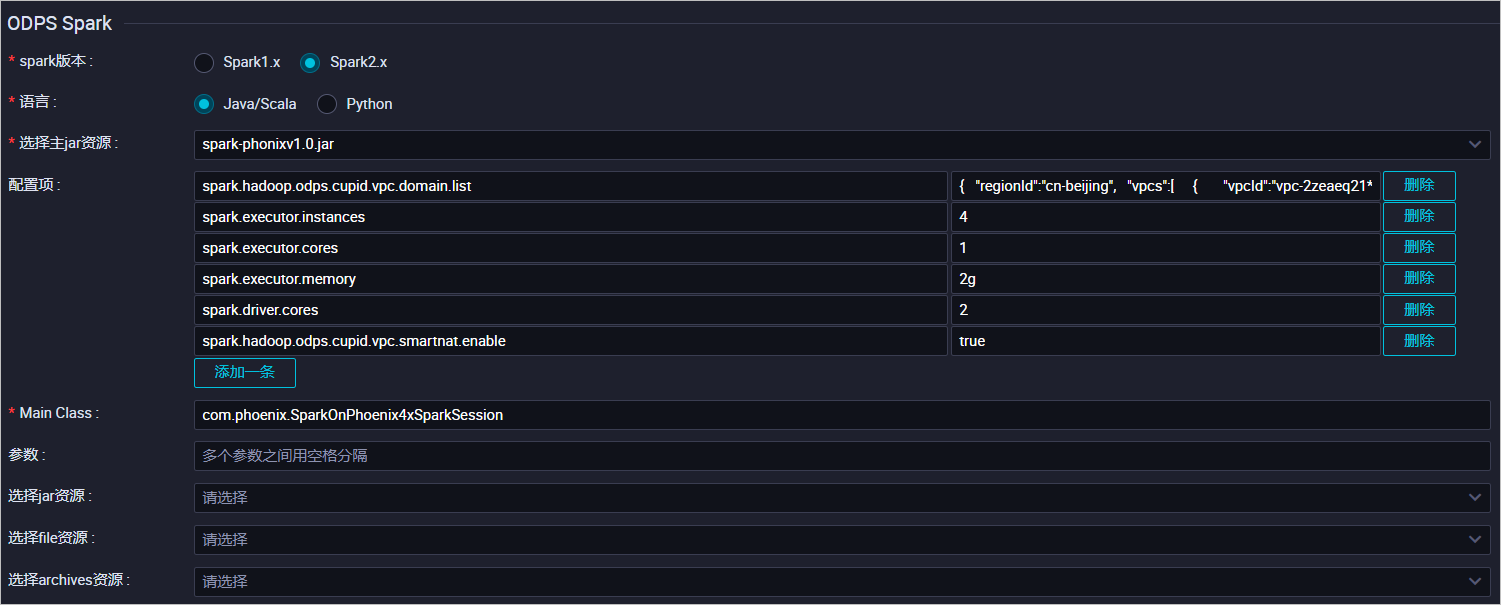
odps spark任务只有使用java时才可以选择jar包资源,python时只能选择python或者archives资源。我想使用graphframes,该包不只需要python还需要jar包。请问该如何把jar包在提交python odps spark任务的时候加进去呢?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
将JAR包的内容作为资源打包:
如果JAR包中的代码或资源可以通过其他方式(如Python的内置库、将JAR包解包并作为文件资源包含)来访问,那么你可以考虑这种方法。但这通常不是处理JAR包依赖的标准方式,且可能不适用于所有情况。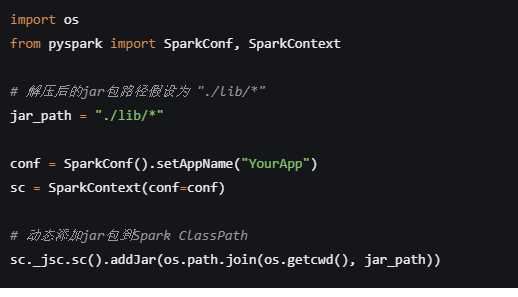
要在一个Python-based的ODPS Spark任务中使用GraphFrames这类既包含Python部分又需要Java JAR包的库,您可以采取以下步骤来确保所有必需的资源都能被正确地加载:
准备JAR包与Python库:
spark-graphx_2.11.jar和其依赖如graphframes.jar)以及Python部分。上传资源到MaxCompute:
引用外部文件:
spark.hadoop.odps.cupid.resources参数指定已上传的JAR包路径。这要求您在任务的运行配置中设置此参数,使其指向之前上传的JAR存储位置。这样,Spark作业运行时,这些JAR包会被自动加入到类路径中。--py-files参数在任务提交时上传Python库,确保Python部分也能被正确加载。编写Python脚本:
SparkContext.addPyFile方法显式地添加Python库,以便在分布式环境下使用这些库。任务提交配置:
spark-submit命令行参数指定JAR和Python文件的位置,以及任何其他必要的Spark配置项,如上述提到的spark.hadoop.odps.cupid.resources。通过上述步骤,您可以在提交Python类型的ODPS Spark任务时,成功地包含并使用既需要Python库也依赖Java JAR包的库,如GraphFrames。
相关链接
Spark on MaxCompute访问Phoenix数据 操作步骤 https://help.aliyun.com/zh/maxcompute/use-cases/use-spark-on-maxcompute-to-access-phoenix-data
登录DataWorks控制台,进入您的项目,然后在“数据开发”页面,选择“新建资源”并上传刚才打包的zip文件作为“archives”资源类型。这样,您的Python环境及所需jar包就被上传到了DataWorks中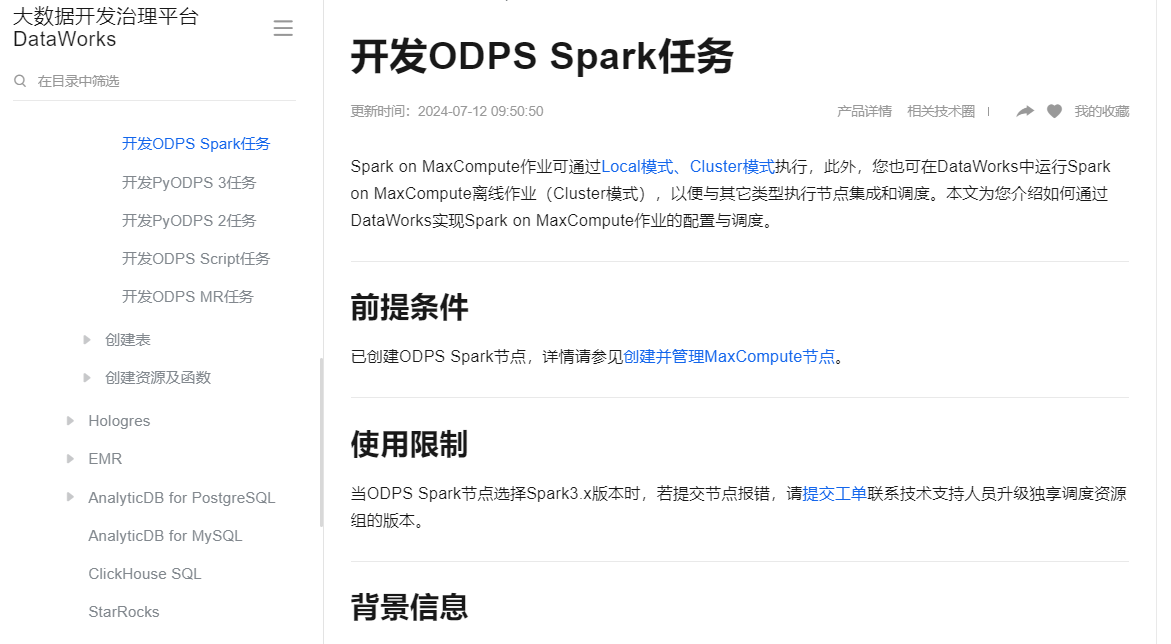
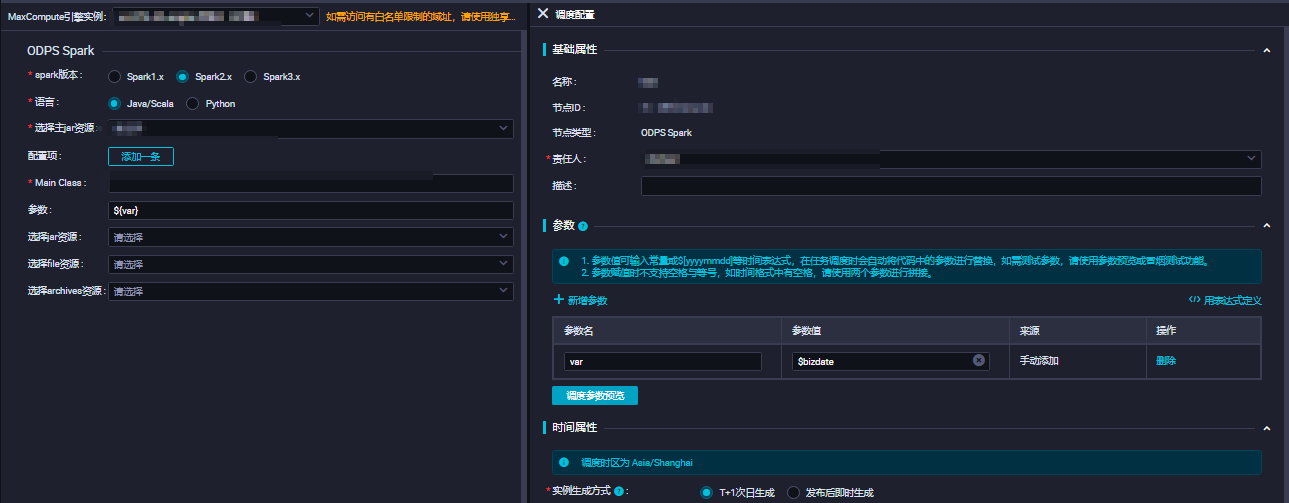
在DataWorks中使用Python编写ODPS Spark任务时,如果你需要引用额外的JAR包,通常这些JAR包是为了在Spark作业中引入特定的库或者依赖项。然而,由于DataWorks的ODPS Spark环境是基于阿里云MaxCompute(原名ODPS)的,其配置和管理方式与传统的Apache Spark集群有所不同。
在DataWorks中,直接通过Python脚本引用JAR包可能不是直接支持的操作,因为DataWorks的Spark作业管理更加偏向于通过其提供的界面和工具链来管理依赖和作业。不过,你仍然有几种方法可以引入和使用JAR包:
通过DataWorks的依赖管理:
检查DataWorks的文档或界面,看是否有直接上传或指定JAR包作为依赖的功能。有些云平台的Spark服务支持通过UI上传JAR包,并在作业配置中指定它们。
使用Spark的--jars参数:
如果你是在提交Spark作业到集群时控制作业的参数(尽管在DataWorks中这可能是受限的),你可以通过--jars参数来指定JAR包。但在DataWorks中,这个参数可能需要通过DataWorks的特定配置或API来设置,而不是直接在Python脚本中设置。
将JAR包的内容作为资源打包:
如果JAR包中的代码或资源可以通过其他方式(如Python的内置库、将JAR包解包并作为文件资源包含)来访问,那么你可以考虑这种方法。但这通常不是处理JAR包依赖的标准方式,且可能不适用于所有情况。
联系阿里云支持:
由于DataWorks是一个托管服务,你可能需要联系阿里云的技术支持来获取关于如何在DataWorks中正确引用JAR包的指导。
使用自定义镜像或环境:
如果你有足够的权限和资源,可以考虑在阿里云上创建一个自定义的Spark环境或镜像,其中已经包含了所需的JAR包。然后,你可以尝试将这个自定义环境或镜像与DataWorks集成,但请注意,这可能需要额外的配置和管理工作。
利用Spark的spark.jars.packages配置:
在Spark中,你可以通过spark.jars.packages配置来指定Maven坐标中的JAR包,Spark会自动从Maven仓库下载这些JAR包。但是,在DataWorks中,你可能需要通过DataWorks的配置界面来设置这个参数,而不是直接在Python脚本中设置。
综上所述,由于DataWorks的特定环境和限制,直接通过Python脚本在ODPS Spark任务中引用JAR包可能不是直接可行的。你需要查看DataWorks的文档和界面,或者联系阿里云的技术支持来获取更具体的指导。
在DataWorks中使用Python编写ODPS Spark任务时,如果你需要引用额外的JAR包,通常这些JAR包是为了在Spark作业中引入特定的库或者依赖项。然而,由于DataWorks的ODPS Spark环境是基于阿里云MaxCompute(原名ODPS)的,其配置和管理方式与传统的Apache Spark集群有所不同。
在DataWorks中,直接通过Python脚本引用JAR包可能不是直接支持的操作,因为DataWorks的Spark作业管理更加偏向于通过其提供的界面和工具链来管理依赖和作业。不过,你仍然有几种方法可以引入和使用JAR包:
通过DataWorks的依赖管理:
检查DataWorks的文档或界面,看是否有直接上传或指定JAR包作为依赖的功能。有些云平台的Spark服务支持通过UI上传JAR包,并在作业配置中指定它们。
使用Spark的--jars参数:
如果你是在提交Spark作业到集群时控制作业的参数(尽管在DataWorks中这可能是受限的),你可以通过--jars参数来指定JAR包。但在DataWorks中,这个参数可能需要通过DataWorks的特定配置或API来设置,而不是直接在Python脚本中设置。
将JAR包的内容作为资源打包:
如果JAR包中的代码或资源可以通过其他方式(如Python的内置库、将JAR包解包并作为文件资源包含)来访问,那么你可以考虑这种方法。但这通常不是处理JAR包依赖的标准方式,且可能不适用于所有情况。
联系阿里云支持:
由于DataWorks是一个托管服务,你可能需要联系阿里云的技术支持来获取关于如何在DataWorks中正确引用JAR包的指导。
使用自定义镜像或环境:
如果你有足够的权限和资源,可以考虑在阿里云上创建一个自定义的Spark环境或镜像,其中已经包含了所需的JAR包。然后,你可以尝试将这个自定义环境或镜像与DataWorks集成,但请注意,这可能需要额外的配置和管理工作。
利用Spark的spark.jars.packages配置:
在Spark中,你可以通过spark.jars.packages配置来指定Maven坐标中的JAR包,Spark会自动从Maven仓库下载这些JAR包。但是,在DataWorks中,你可能需要通过DataWorks的配置界面来设置这个参数,而不是直接在Python脚本中设置。
综上所述,由于DataWorks的特定环境和限制,直接通过Python脚本在ODPS Spark任务中引用JAR包可能不是直接可行的。你需要查看DataWorks的文档和界面,或者联系阿里云的技术支持来获取更具体的指导。
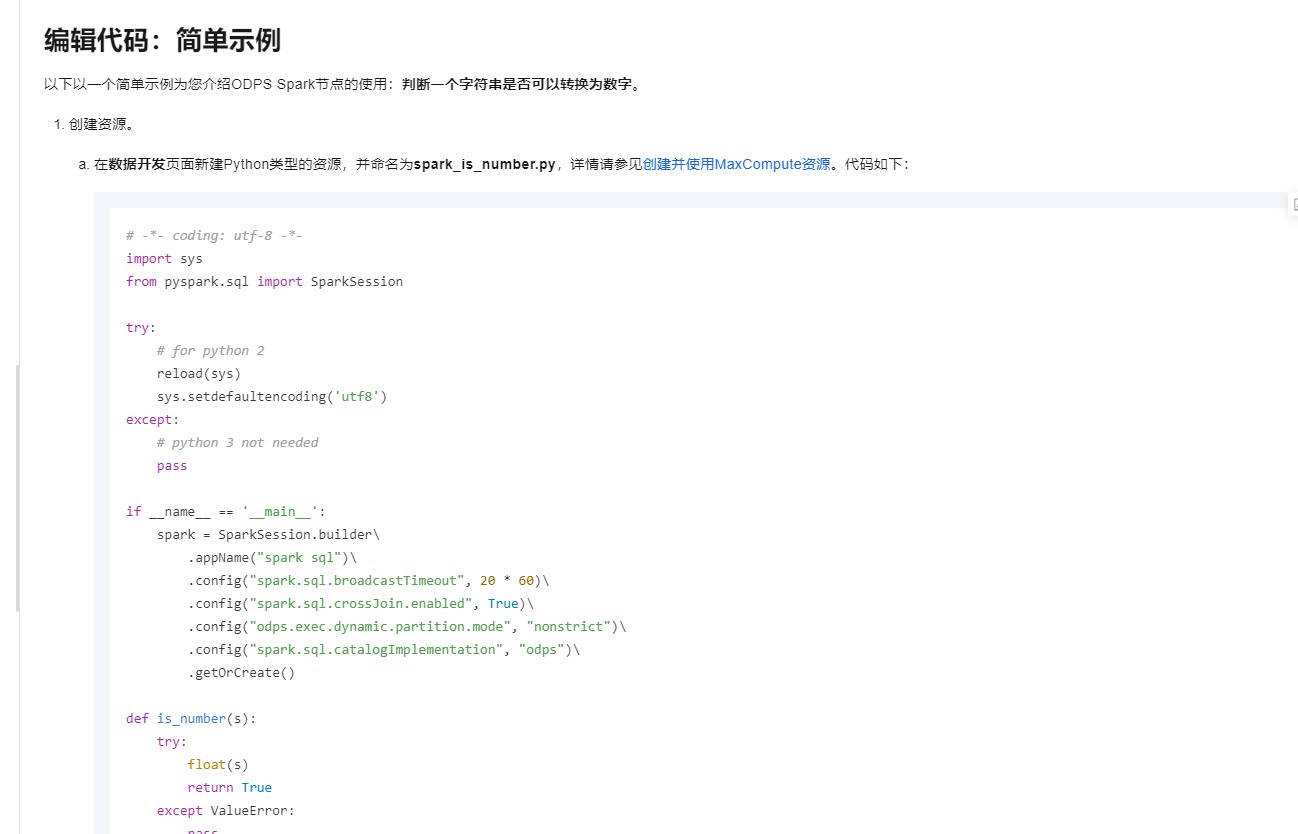
要在一个Python-based的ODPS Spark任务中使用GraphFrames这类既包含Python部分又需要Java JAR包的库,
引用资源:
@resource_reference{"your_python_lib.zip"}语法来引用之前上传的ZIP文件资源,这里的your_python_lib.zip是您上传的Python库ZIP文件的资源名称。spark.hadoop.odps.cupid.resources参数指定之前上传的JAR包路径。例如,如果JAR包名为graphframes_jars.jar,并且已上传至项目空间,可以设置类似这样的参数:spark.hadoop.odps.cupid.resources=hdfs://your_project_path/graphframes_jars.jar。要在Python的MaxCompute Spark任务中使用GraphFrames,您需要通过spark.jars参数指定JAR包。可以这样设置:
确保projectname.graphframes.jar是正确的路径,且在提交任务时,该JAR包已经上传到MaxCompute的资源库,并设置好相应的权限。可参考Spark访问VPC实例。
在DataWorks中使用ODPS Spark任务时,确实存在这样的限制:Python任务通常只能选择Python文件或archives资源,而不能直接选择JAR包。但是,您仍然可以使用GraphFrames这样的库,即使它需要JAR包。以下是一种可能的解决方案:
使用setup.py:编写一个setup.py文件,将GraphFrames的Python部分和JAR包一起打包成一个Wheel文件。例如:
from setuptools import setup, find_packages
setup(
name="graphframes_wheel",
version="0.1",
packages=find_packages(),
package_data={
'': ['*.jar'],
},
include_package_data=True,
)
python setup.py bdist_wheel命令生成Wheel文件。安装Wheel:在Python脚本中使用pip install命令安装这个Wheel文件。例如:
import sys
import subprocess
def install(package):
subprocess.check_call([sys.executable, "-m", "pip", "install", package])
# 安装wheel文件
install('graphframes_wheel')
spark.jars:您还可以通过spark.jars参数将JAR包添加到Spark的ClassPath中。这需要在提交Spark任务时指定这些JAR包的位置。但是,这种方式通常适用于Java/Scala任务,对于Python任务来说,建议使用上面的方法。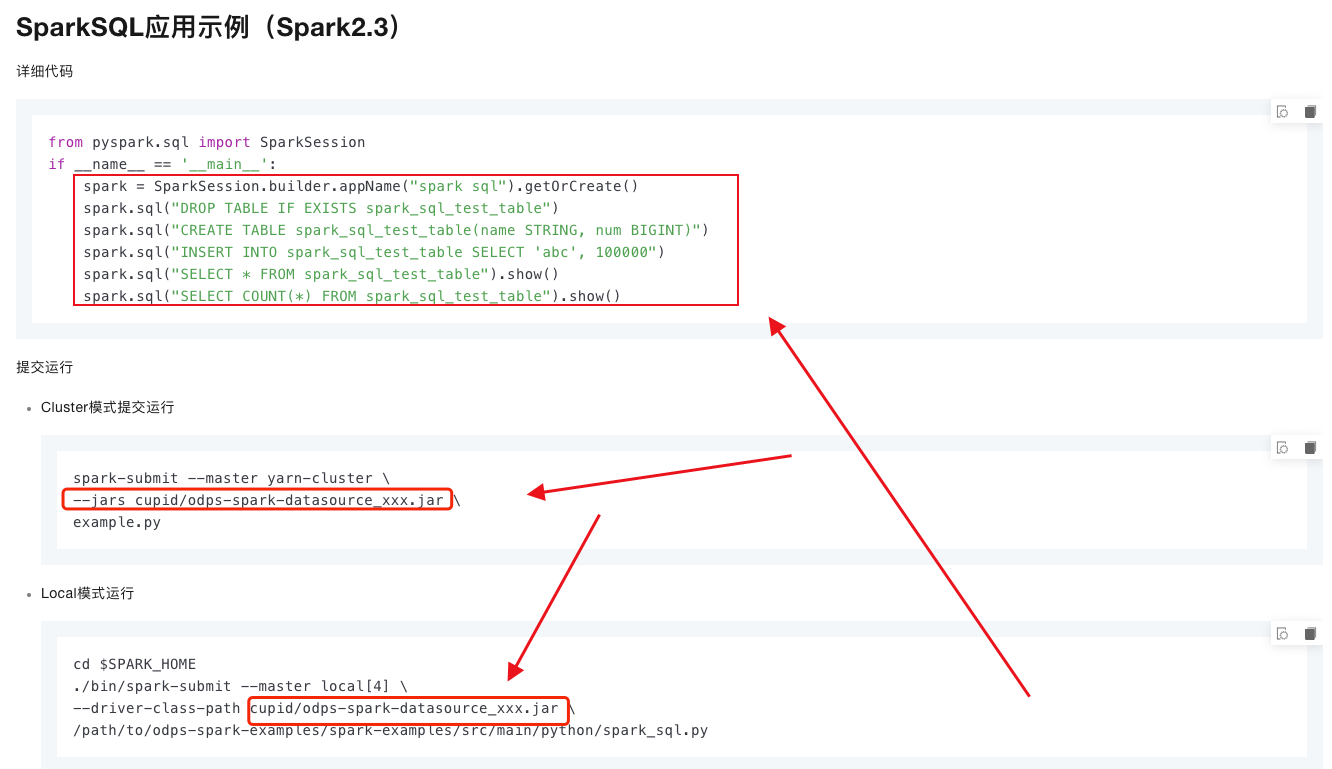
假设您已经创建了一个名为graphframes_wheel的Wheel文件,并将其上传到了DataWorks中。接下来,您可以按照以下步骤创建并执行Python Spark任务:
graphframes_wheel作为Python资源。以下是使用graphframes_wheel的一个示例脚本:
import sys
import subprocess
def install(package):
subprocess.check_call([sys.executable, "-m", "pip", "install", package])
# 安装wheel文件
install('graphframes_wheel')
from pyspark.sql import SparkSession
from graphframes import *
# 创建SparkSession
spark = SparkSession.builder.appName("GraphFramesExample").getOrCreate()
# 示例数据
vertices = spark.createDataFrame([
("a", "Alice", 34),
("b", "Bob", 36),
("c", "Charlie", 30),
], ["id", "name", "age"])
edges = spark.createDataFrame([
("a", "b", "friend"),
("b", "c", "follow"),
("c", "b", "follow"),
], ["src", "dst", "relationship"])
# 创建GraphFrame
g = GraphFrame(vertices, edges)
# 进行图计算
print(g.inDegrees.show())
# 停止SparkSession
spark.stop()
通过以上步骤,您应该能够在Python Spark任务中使用需要JAR包的库,如GraphFrames。如果在执行过程中遇到任何问题,请随时提供更详细的信息以便进一步帮助。
你可以试试上传Jar包至MaxCompute:
首先,你需要将所需的jar包上传至MaxCompute。这可以通过MaxCompute客户端完成,确保jar包对于你的任务是可访问的。
使用spark-submit命令的--archives参数:
虽然直接指定jar包像Java任务那样不直接支持,但你可以利用--archives参数间接包含jar包。将jar包打包成一个zip或tar.gz档案,并通过此参数上传。在Python脚本中,这些归档文件会被解压到一个特定目录下,你可以在代码中通过这个目录来引用jar包。
shell
spark-submit --archives your_archive_with_jars.zip#lib ...
上述命令中,your_archive_with_jars.zip是你包含所需jar包的归档文件,#lib表示解压后的目录名,之后在Python脚本里可以通过这个目录路径访问到jar包。
在Python脚本中动态添加jar包到Spark ClassPath:
在你的Python Spark应用程序开始执行前,可以通过Spark的API动态地将解压后的jar包路径添加到Spark的类路径中。这样,即使是在执行Python任务,Spark也能识别到这些jar包。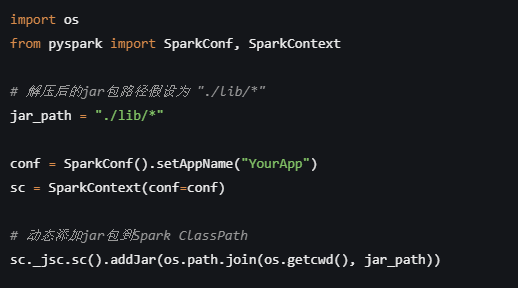
有没有GraphFrames的Python包和Java库(JAR包)。
可以通过pip安装GraphFrames Python包,使用命令pip install graphframes。同时,下载GraphFrames对应的Java库JAR包
将GraphFrames的JAR包上传至MaxCompute资源管理中。您可以在DataWorks中创建或上传JAR类型的资源,并确保JAR包在MaxCompute中可用
在提交Python ODPS Spark任务时,如果需要同时使用Python包和Java的JAR包(如GraphFrames),你需要在任务提交时明确指定这些依赖。虽然ODPS Spark的Python API可能默认只提供Python和Archives资源的配置,但你可以通过以下方式加入JAR包:
使用Spark Submit参数:在通过ODPS提交Spark任务时,通常会有一个底层的Spark Submit命令。你可以在这个命令中通过--jars参数来指定JAR包的位置。这可能需要你直接在ODPS的工作流定义中或者通过命令行接口(CLI)来手动设置这个参数。
配置工作流:在ODPS DataWorks中,你可以在配置Spark任务的工作流时,查看是否有高级设置或自定义参数可以允许你输入Spark Submit的参数。
上传JAR包到ODPS:确保你的JAR包已经上传到ODPS的某个位置,然后在Spark Submit命令中引用这个位置的JAR包。
考虑使用Python包装器:如果直接添加JAR包到Python任务中不可行,你可以考虑编写一个简单的Java或Scala包装器,该包装器加载GraphFrames的JAR包,并暴露必要的接口给Python调用。这可能需要额外的设置和代码工作。
总之,虽然ODPS Spark的Python API可能不直接支持JAR包依赖,但你可以通过修改Spark Submit命令或利用工作流的高级设置来添加这些依赖。
Java/Scala
在ODPS Spark节点执行Java或Scala语言类型代码前,您需先在本地开发好Spark on MaxCompute作业代码,再通过DataWorks上传为MaxCompute的资源。步骤如下:
准备开发环境。
根据所使用系统类型,准备运行Spark on MaxCompute任务的开发环境,详情请参见搭建Linux开发环境、搭建Windows开发环境。
开发Java/Scala代码。
在ODPS Spark节点执行Java或Scala语言类型代码前,需先在本地或已有环境开发好Spark on MaxCompute代码,建议使用Spark on MaxCompute提供的项目示例工程模板进行开发。
打包代码并上传至DataWorks。
代码开发完成后,需将其打包,并通过DataWorks上传为MaxCompute资源,详情请参见创建并使用MaxCompute资源。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。