
interval join完成两个表关联时,没打印出来数据,出现“javax.management.InstanceAlreadyExistsException: kafka.consumer:type=app-info,id=dwd_trade_order_pay_suc_detail-0”这个问题,Flink这是什么原因?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
遇到“javax.management.InstanceAlreadyExistsException: kafka.consumer:type=app-info,id=...”这类异常,通常意味着在同一个JVM中尝试创建了具有相同标识的多个JMX MBean实例。在Flink应用上下文中,这可能是因为您的Flink作业配置或者环境中存在以下问题:
并行度设置与消费者组冲突:如果您在Flink作业中配置了多个相同的Source(比如多个Kafka消费者),并且它们使用了相同的消费者组ID,同时这些Source运行在相同的TaskManager上(即并行度设置导致了多个实例运行在同一JVM中),就可能导致此异常。每个消费者实例尝试注册相同的JMX MBean,从而引发冲突。
JVM重用配置问题:在某些情况下,如果您的Flink集群配置启用了TaskManager的JVM重用功能,可能会导致之前任务的资源未完全释放,新任务尝试使用相同的资源时冲突。特别是当这些任务共享某些资源标识(如上述的JMX MBean标识)时,更容易出现问题。<
解决办法:
确保唯一消费者组ID:为每个独立的Kafka Source分配唯一的消费者组ID,即使它们逻辑上是读取相同的Kafka主题。这样可以确保即使并行实例运行在同一JVM中,也不会因JMX MBean冲突而失败。
检查并行度与部署配置:合理设置作业的并行度,确保不会无意中在单个TaskManager上运行多个具有相同资源需求的任务实例。同时,检查TaskManager的JVM重用设置,必要时可禁用此功能以排除问题。
重启TaskManager或整个集群:如果问题是由遗留的JVM状态引起,重启受影响的TaskManager或整个Flink集群可以清除这些状态,避免冲突。
日志与监控:深入分析Flink作业的日志,寻找有关消费者配置、并行度设置以及JVM重用的线索,这有助于定位问题的具体原因。
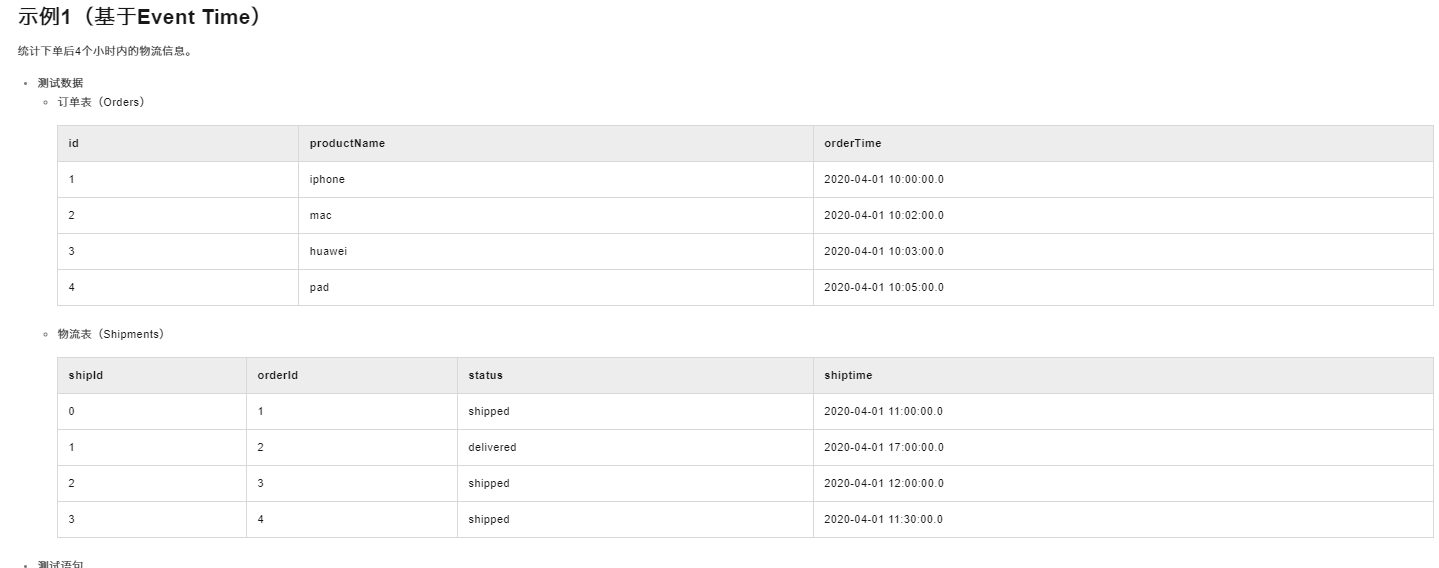
相关链接
IntervalJoin语句 示例2(基于Processing Time) https://help.aliyun.com/zh/flink/developer-reference/intervaljoin-statement
遇到“javax.management.InstanceAlreadyExistsException: kafka.consumer:type=app-info,id=...”这个异常,通常意味着在JVM中尝试创建具有相同标识的多个JMX管理对象实例时发生了冲突。
解决此问题的建议步骤包括:
针对您的Interval Join操作未打印数据的问题,虽然直接关联这个异常可能不太直观,但解决上述JMX冲突问题有助于确保Flink作业正常运行,从而间接解决数据处理流程中的潜在障碍。如果问题依旧存在,进一步检查Interval Join的条件设置、时间窗口配置以及输入流的数据是否符合预期,也是必要的步骤。
这个问题看起来是由于Kafka消费者管理实例已经存在导致的。InstanceAlreadyExistsException通常意味着您尝试注册的JMXbean(与Kafka消费者相关的监控指标)已经在JMX中注册过了。这可能是因为您的Flink任务尝试多次创建同一个消费者的监控实例。
解决方法通常包括检查您的代码或配置,确保每个消费者组只有一个实例在运行,或者正确关闭和重新初始化消费者。另外确保Flink的Kafka连接器配置正确,没有并发问题。
遇到“javax.management.InstanceAlreadyExistsException”错误,这通常意味着在Java管理扩展(JMX)中尝试注册一个已经存在的MBean(Managed Bean,受管Bean)
当多个Flink任务或者应用程序实例尝试使用相同的消费者组ID初始化Kafka消费者时,可能会导致此异常。确保每个消费任务或应用实例使用唯一的消费者组ID
参考文档:https://help.aliyun.com/zh/flink/developer-reference/kafka-connector/
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。



