
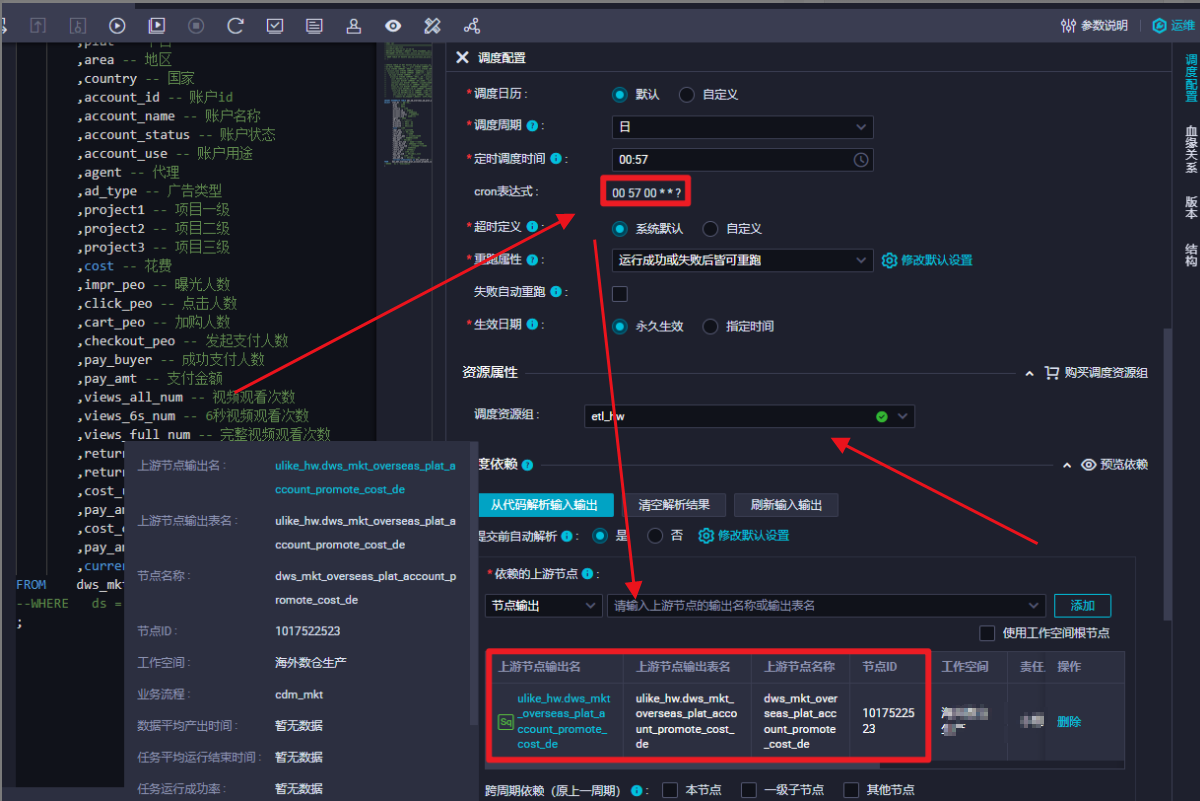
DataWorks节点依赖的上游节点,为啥没有显示上游的调度周期和调度时间呢,有展示其他的信息,但就是没有调度时间这个显示难道不是很重要的吗?为啥没有呢?我都不能直观的看到上游啥时候开始跑?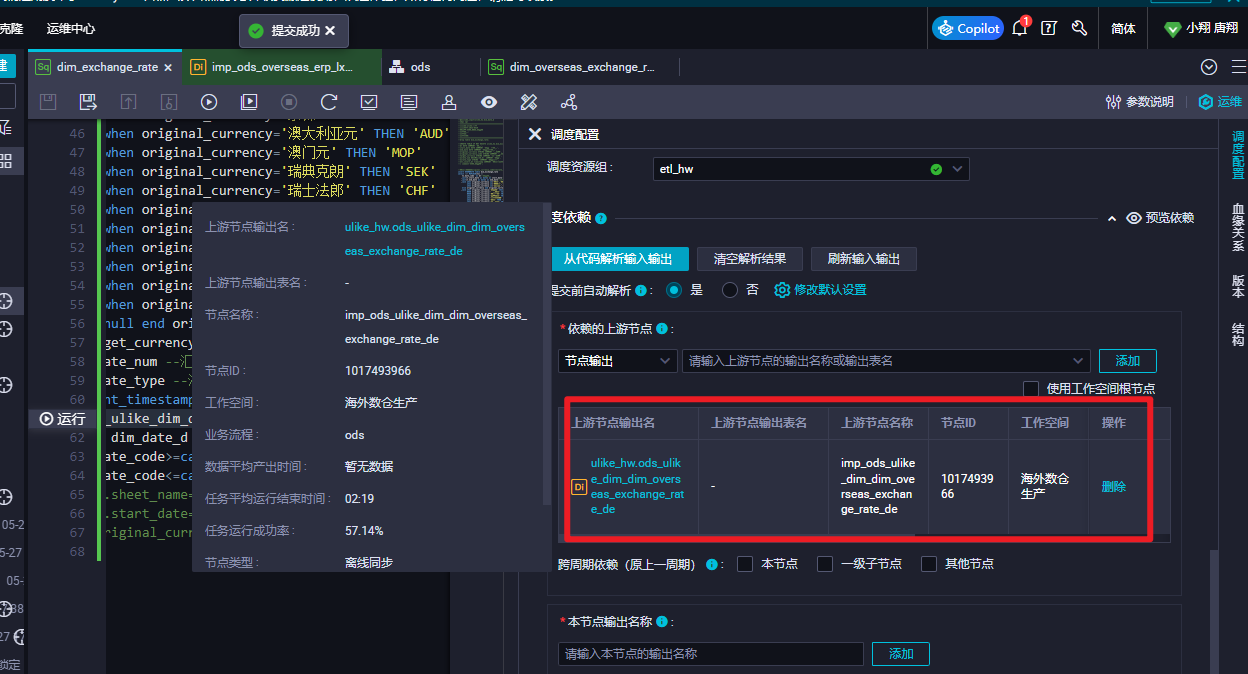
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
配置示例
配置路径
您需要进入数据开发节点的编辑页面,单击右侧导航栏的调度配置,在调度配置 > 时间属性区域配置节点的调度周期。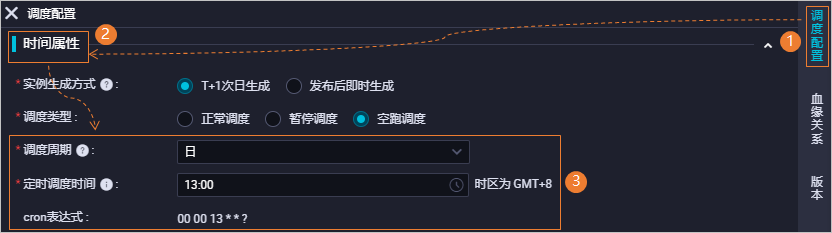
场景示例
配置详情
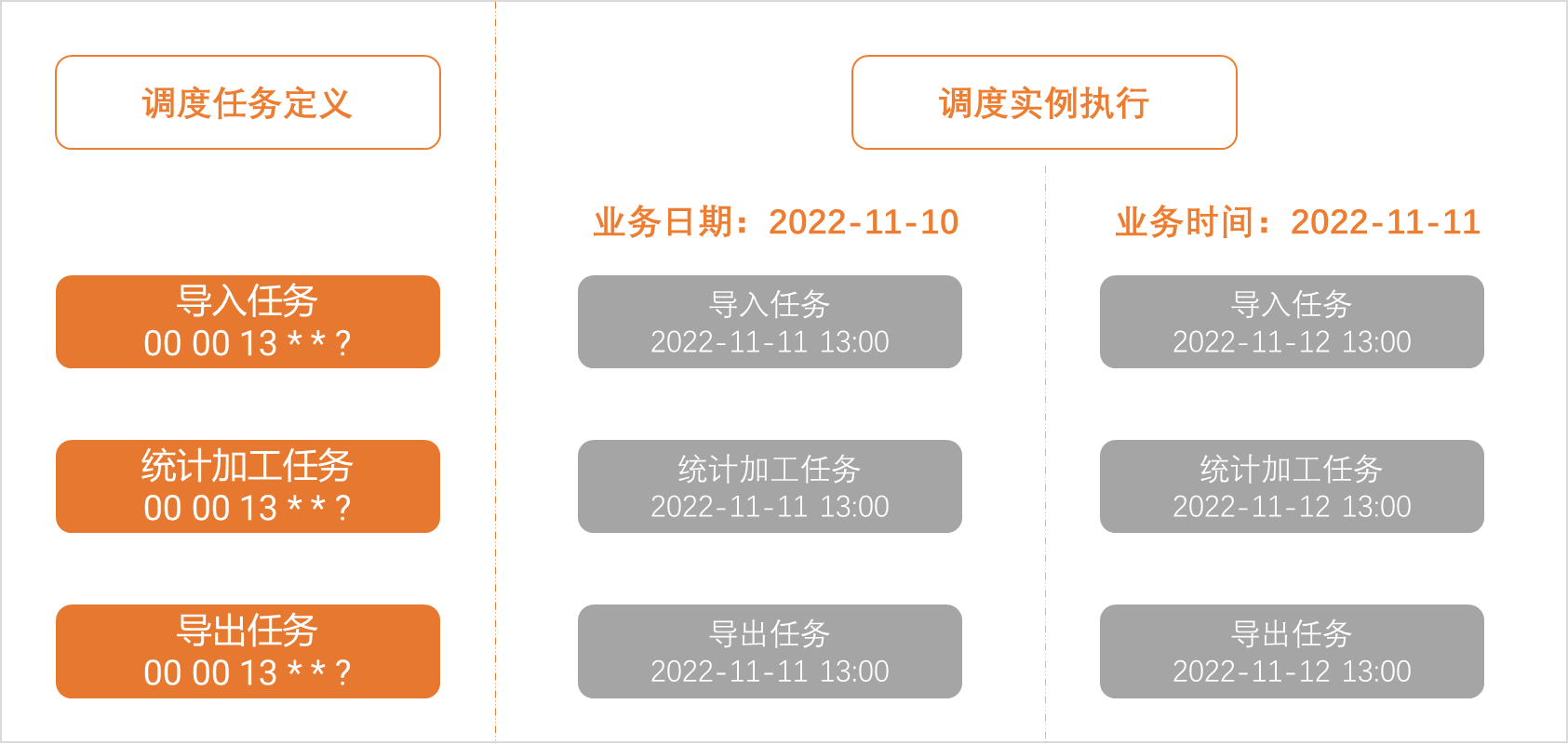
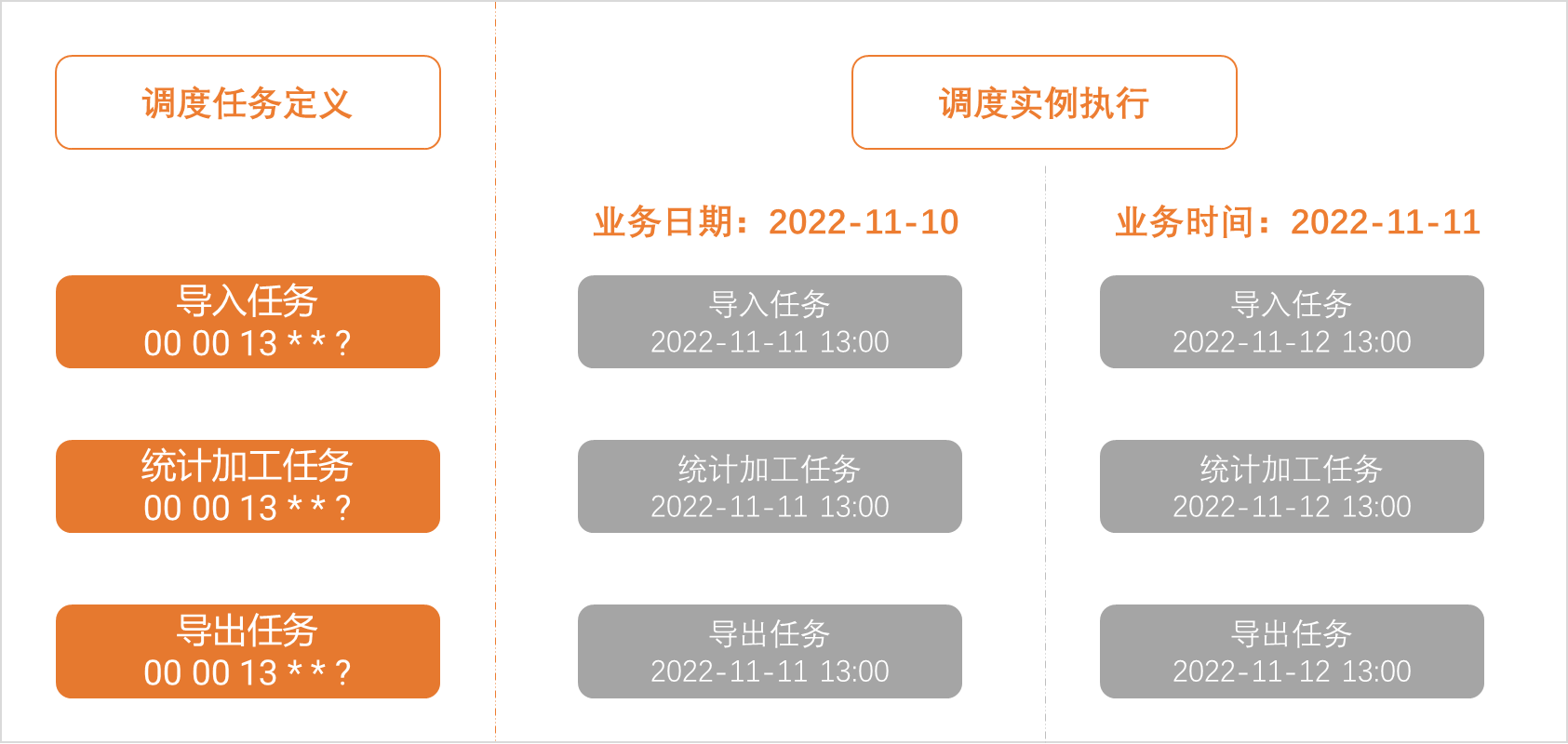
假设导入、统计加工和导出任务,均为日调度任务。
上述任务的运行时间为每天13:00点。
统计加工任务依赖导入任务,导出任务依赖统计加工任务(即统计加工任务的调度依赖,配置依赖的上游任务为导入任务)。
阿里云DataWorks中,查询MaxCompute(旧称ODPS)的表总数和字段总数可以通过几种不同的方法实现。以下是具体的操作步骤和方法:
使用数据地图查看表信息
访问数据地图:在DataWorks的数据地图中,可以查看每个表的详细信息,包括字段列表。
操作步骤:进入DataWorks管理控制台,打开对应的项目空间,然后进入数据地图。在这里,你可以看到项目中所有的表以及它们的详细信息,包括字段名称、数据类型等。
编写SQL语句查询
查询所有表名:
sql
复制代码
SELECT DISTINCT TABLE_NAME
FROM META.TABLES
WHERE DATABASE_NAME = '';
其中 需要替换为你要查询的具体数据库名称。
查询某张表的所有字段信息:
sql
复制代码
SELECT COLUMN_NAME, DATA_TYPE, COMMENT
FROM META.COLUMNS
WHERE TABLE_NAME = ''
AND DATABASE_NAME = '';
同样需要替换 和 为你的表名和数据库名。
查询所有表的名称、字段名称和数据类型:
sql
复制代码
SELECT table_name, column_name, data_type
FROM information_schema.columns
WHERE table_schema = 'your_project_name';
请将 your_project_name 替换为您的项目名称。
使用PyODPS执行查询:利用DataWorks中的PyODPS节点,可以运行Python代码来自动化查询过程。例如,可以使用PyODPS的get_table方法获取表对象,遍历表对象的字段来统计字段总数。
创建PyODPS节点并编写代码:在DataWorks的数据开发页面创建PyODPS节点,然后编写相应的Python代码来调用MaxCompute的SDK进行查询。这种方式适合自动化处理和周期性任务调度。
注意事项:在使用PyODPS时,注意设置合适的读取数据记录数限制,并确保正确配置了运行环境参数。
此外,为了更有效地管理DataWorks中的MaxCompute项目,以下是一些建议:
权限管理:确保拥有足够的权限来访问和查询MaxCompute中的元数据。
网络配置:优化网络连接,确保DataWorks与MaxCompute之间的数据传输畅通无阻。
错误处理:在编写SQL或Python脚本进行查询时,添加适当的错误处理机制以应对可能的查询异常。
定期更新:定时检查项目的表结构和字段定义,以确保与实际业务需求保持一致。
综上所述,你可以有效地查询DataWorks中MaxCompute的表总数和字段总数,从而更好地管理和监控数据仓库项目。
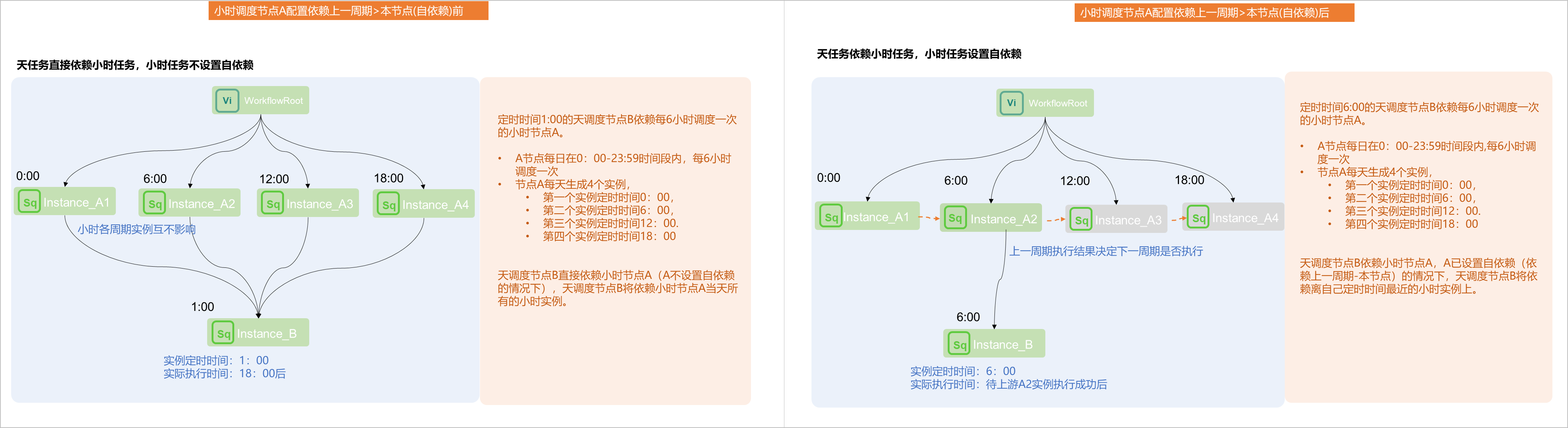
在DataWorks中配置和使用节点依赖是保障数据正确性和实现有效调度的重要手段。然而,用户在实际使用过程中可能会遇到上游节点的调度周期和调度时间没有直接显示出来的情况,这可能会给任务管理和调度带来一些不便。以下是对此问题的详细分析:
设计理念与信息展示优先级
界面设计的简化:DataWorks的设计可能更倾向于简化用户界面,避免展示过多的细节信息,以减少用户的认知负担。
关键信息优先:平台更注重于显示任务状态和基本的依赖关系,而非每个任务的具体调度时间,因为这些信息对于日常操作来说已经足够。
技术与性能考虑
性能优化:在涉及大量任务和依赖关系的复杂情况下,减少计算负载是必要的,过多的详细信息可能会影响系统的整体性能。
动态调度参数:DataWorks支持动态替换调度参数,因此实际的调度时间可能在任务执行前才被确定,而不是一个固定的值。
在平台里面呢,
调度周期和调度时间确实是任务调度配置的关键信息,它们直接影响任务实例的生成与执行顺序。然而,在任务依赖关系的直观展示界面(如DAG图),可能更多地侧重于展示任务之间的逻辑依赖关系,即哪些任务需要等待其他任务执行成功后才能开始,而不是直接展示每个任务的具体调度周期和时间
所以页面里面是没有的呀
如果想要查询的话,建议直接访问相应任务的配置页面查看详细调度设置。
对于复杂的依赖关系和调度策略,可以参考DataWorks提供的复杂依赖场景调度配置原则与示例
,以便更好地理解和调整任务依赖。
在DataWorks中查看任务依赖时,确实有时候会发现上游任务的详细调度信息(如调度周期和调度时间)没有直接展示出来。这通常是由于DataWorks UI设计的限制以及信息展示的优先级问题。
界面设计:
信息展示优先级:
性能考虑:
尽管默认界面可能没有显示这些信息,但你可以通过以下几种方式来查看上游任务的调度时间和周期:
查看任务详情:
查看任务实例:
使用DataWorks的API或SDK:
自定义仪表板:
使用日志和监控工具:
对于您不能直观看到上游节点调度时间的问题,这可能是因为产品设计者在设计时做出了取舍,优先考虑了其它功能或性能因素。在实际使用中,如果需要关注上游节点的调度时间,可以通过以下方法进行操作:
使用系统日志或调度报告来查看每个任务节点的运行时间。
设置邮件或短信提醒,当上游任务开始运行时自动通知。
定期检查DataWorks的监控页面,了解任务的运行状态和时间。
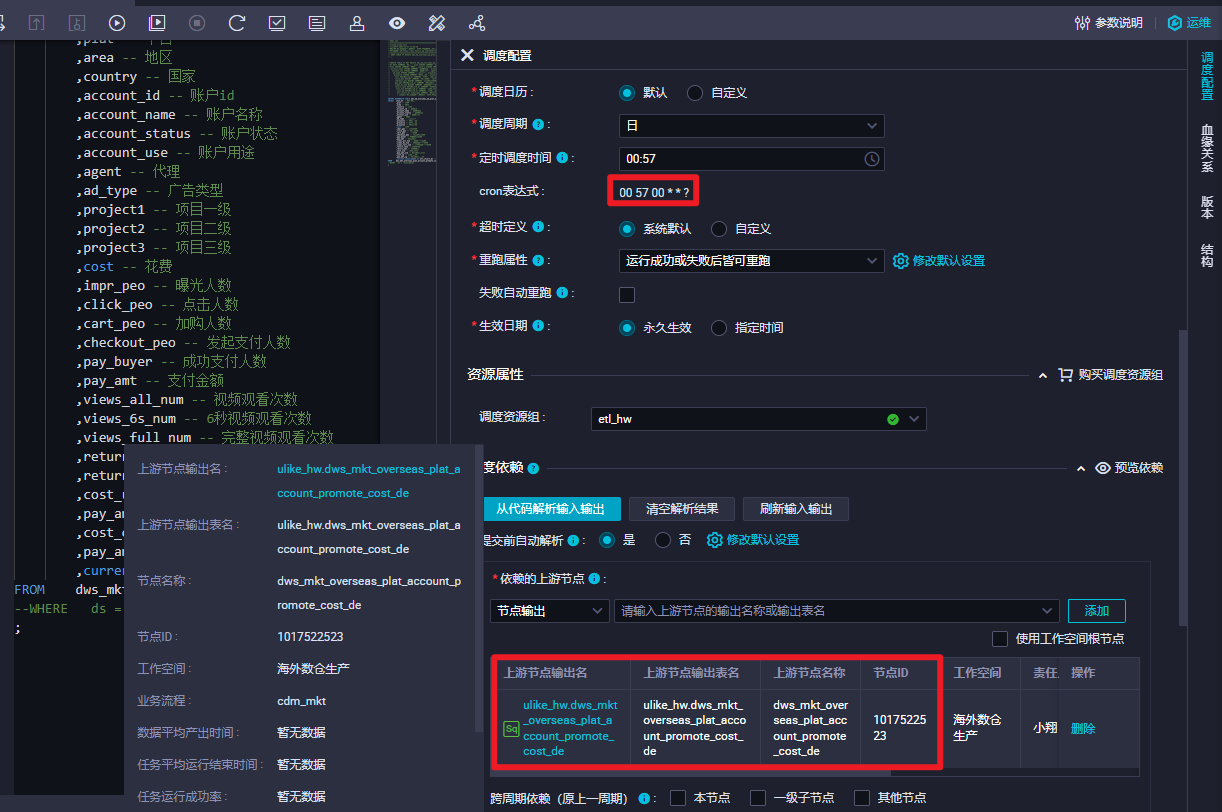
上游全部执行成功+下游定时时间到+下游有调度资源=下游开始执行 ,所以会等上游全部执行完成才开始运行。配置不会有问题,调度会按照这个逻辑执行。
此回答整理自钉群“DataWorks交流群(答疑@机器人)”
在DataWorks中,节点依赖的上游节点没有直接显示调度周期和调度时间,这可能是由于DataWorks界面设计的侧重点不同所致。DataWorks主要关注于数据处理的流程、依赖关系以及任务执行的结果,而调度周期和调度时间等详细信息可能更多地被视为任务配置的一部分,而非直接展示在节点依赖视图中。
不过,你仍然可以通过以下方式获取上游节点的调度周期和调度时间:
查看任务配置:在DataWorks中,每个任务(节点)都可以配置其调度周期和调度时间。你可以直接查看上游节点的任务配置,以获取这些信息。
使用运维中心:DataWorks的运维中心提供了任务调度的详细信息,包括每个任务的调度周期、调度时间、执行状态等。你可以通过运维中心来查看上游节点的调度信息。
依赖关系图:虽然依赖关系图可能不直接显示调度时间,但它可以帮助你理解节点之间的依赖关系,从而推断出上游节点的执行时间。
日志和监控:通过查看任务的执行日志和监控信息,你也可以间接地获取上游节点的调度和执行情况。
总之,虽然DataWorks节点依赖的上游节点没有直接显示调度周期和调度时间,但你仍然可以通过其他方式来获取这些信息。如果你需要更直观地看到上游节点的调度时间,建议结合使用任务配置、运维中心、依赖关系图以及日志和监控等功能。
DataWorks根据节点的依赖配置,为您生成上下游节点的依赖关系图,您可基于该图检查调度依赖配置是否符合预期。
说明
单击任意节点,即可查看该节点的详细信息。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。



