
Flink的这个job 一直CP失败,什么原因?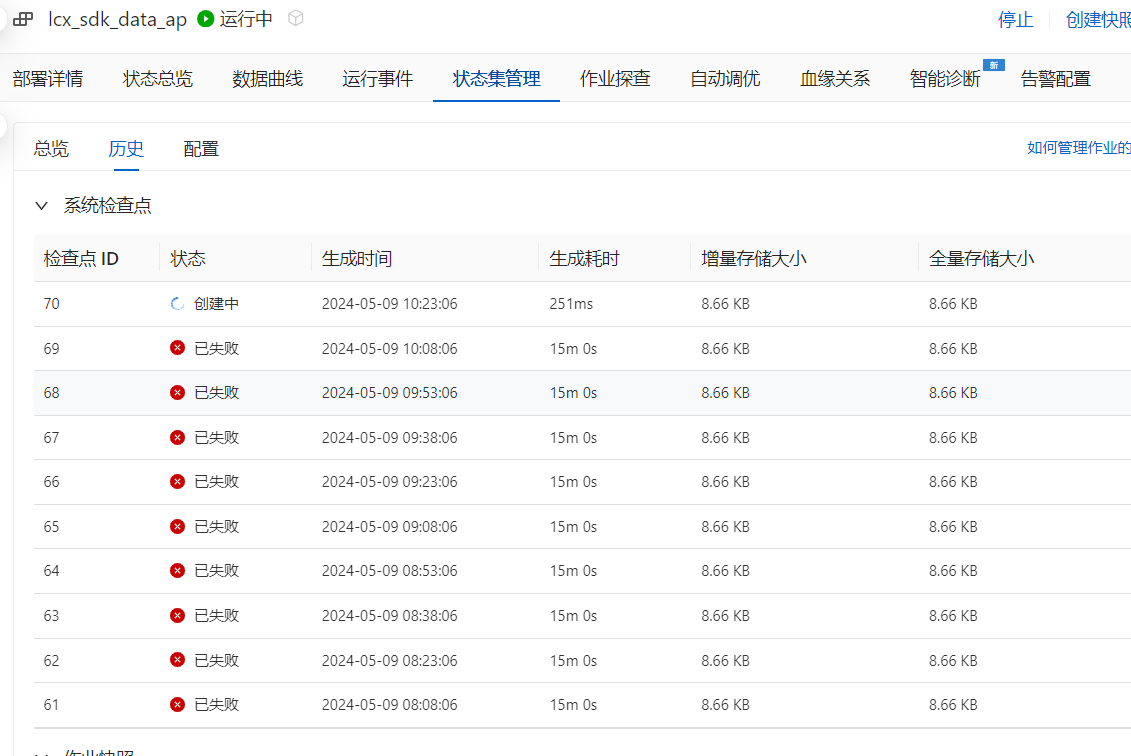
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
有可能是当Flink Job处理的数据量很大时,可能会导致内存溢出。解决方式是增加TaskManager的内存配置,或者使用RocksDB状态后端来减少内存占用,还有 CPU资源不足可能导致Checkpoint过程中的计算密集型操作变慢。解决方式是增加CPU资源或优化计算逻辑以减少CPU使用,另外 如果Checkpoint超时设置得不合理,可能会导致Checkpoint失败。解决方式是根据实际数据处理速度调整Checkpoint超时时间
Flink作业Checkpoint失败可能由 大规模作业的资源限制:对于大规模作业,若JobManager资源(特别是CPU和内存)不足,可能会导致RPC请求积压,影响心跳和RPC通信,从而Checkpoint失败。这种情况下,建议增加JobManager的资源,并适当调高akka.ask.timeout和heartbeat.timeout参数值,但需注意仅在必要时调整这些参数,避免因调整过度导致作业恢复时间延长。[2]
。
相关链接
作业发生切换或者TaskManager失败 报错:akka.pattern.AskTimeoutException https://help.aliyun.com/zh/flink/support/faq-about-deployment-failovers-and-taskmanager-failures
Flink 作业的检查点失败可能由多种原因引起:
网络问题:如果网络连接不稳定或出现延迟,可能会导致数据传输中断,从而影响检查点的完成。
存储问题:检查点数据通常会存储在持久化存储系统中,如 HDFS 或其他分布式文件系统。如果这些系统的可用性出现问题,可能导致检查点失败。
资源限制:如果集群资源不足,例如内存、CPU 或磁盘空间不足,也可能导致检查点失败。
应用程序错误:代码中的 bug 可能会导致检查点失败。例如,自定义的 source、sink 或 transformation 函数可能存在逻辑错误。
配置问题:不正确的配置设置也可能是导致检查点失败的原因。例如,检查点间隔时间过短,或者检查点模式设置不当等。
磁盘 I/O 限制:
原因: 磁盘 I/O 性能不足可能导致 Checkpoint 数据写入缓慢。
解决: 使用高性能磁盘,或者增加磁盘缓存大小。
内存不足:
原因: 当 Flink Job 处理的数据量很大时,可能会导致内存溢出。
解决: 增加 TaskManager 的内存配置,或者使用 RocksDB 状态后端来减少内存占用。
CPU 资源限制:
原因: CPU 资源不足可能导致 Checkpoint 过程中的计算密集型操作变慢。
解决: 增加 CPU 资源,或者优化计算逻辑以减少 CPU 使用。
Checkpoint 时间间隔太短:
原因: 如果 Checkpoint 时间间隔设置得太短,可能会导致频繁的 Checkpoint 导致性能下降。
解决: 增加 Checkpoint 的时间间隔,例如从默认的 5 分钟增加到 10 分钟。
Checkpoint 超时:
原因: 如果 Checkpoint 超时设置得不合理,可能会导致 Checkpoint 失败。
解决: 根据实际数据处理速度调整 Checkpoint 超时时间。
数据倾斜:
原因: 如果数据分布不均,可能会导致某些 TaskManager 的 Checkpoint 操作比其他 TaskManager 更慢。
解决: 重新分区数据,或者使用 REPARTITION 或 REDISTRIBUTE 关键字重分布数据。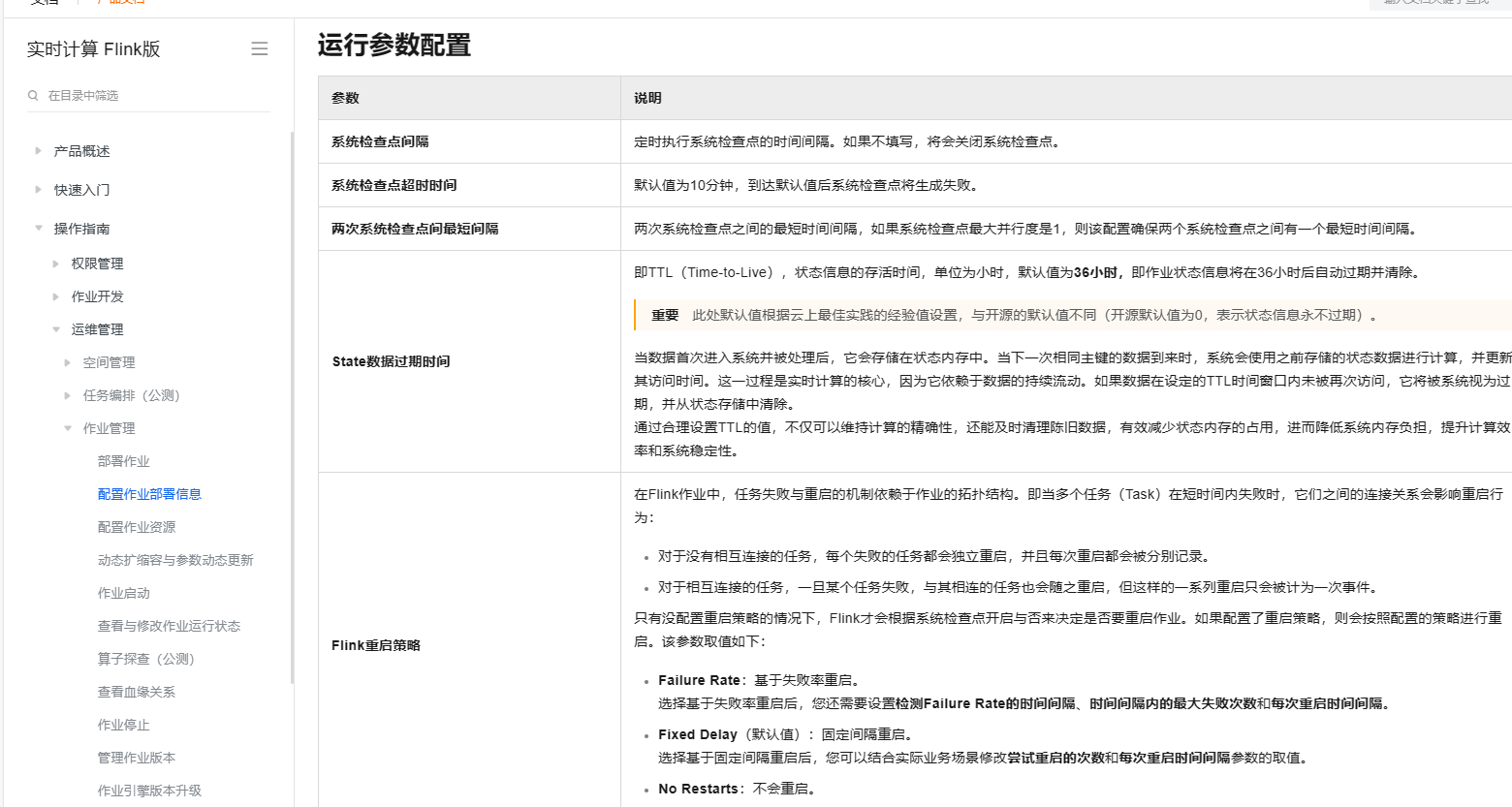
原因有很多种,光看你这个图也看不出
有可能资源不足引发的持续GC:JobManager或TaskManager内存不足,频繁进行垃圾回收(GC),可能导致心跳和RPC请求超时,进而影响Checkpoint。解决方案是检查作业内存使用情况和GC日志,如有必要,增加JM和TM的内存资源配置
还有可能作业中存在数据处理瓶颈,导致数据积压
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。



