
这个flink 报错有解决方案吗?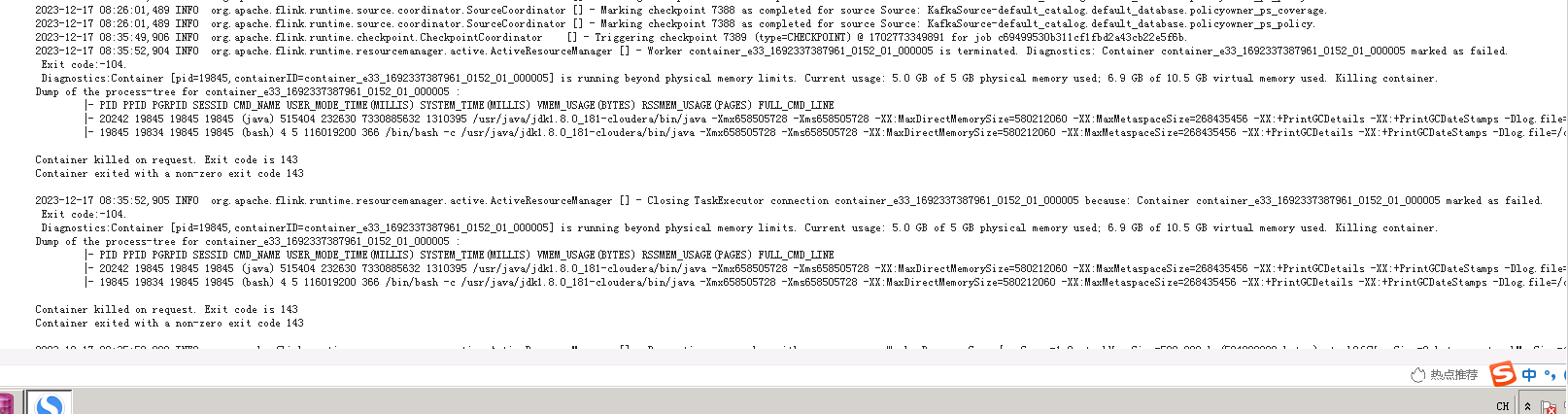
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
这个错误提示表示你的 Flink 任务使用的内存超过了物理内存的限制。具体来说,你的容器使用了 5.0GB 的物理内存,但是只分配了 5GB 的物理内存。此外,你还使用了 6.9GB 的虚拟内存,总共使用了 10.5GB 的内存。
解决这个问题的方法有两个:
增加你的 Flink 任务的内存限制。你可以通过修改 Flink 的配置文件来增加每个 taskmanager 的 heap memory 和 network memory 的限制。但是请注意,这可能会增加你的 Flink 任务的资源消耗,可能会导致其他问题。
优化你的 Flink 任务。你可以检查你的 Flink 任务的代码,看看是否有任何不必要的内存使用,或者是否可以优化你的数据处理逻辑来减少内存的使用。
另外,你的 Flink 任务还出现了 "Container exited with a non-zero exit code 143" 的错误。这个错误通常表示你的 Flink 任务因为某种原因被 kill 掉了。这可能是因为你的 Flink 任务使用了过多的资源,或者是因为你的 Flink 任务遇到了无法处理的异常。你可以查看你的 Flink 任务的日志,看看是否有任何异常的输出,以确定具体的原因。
根据您提供的错误消息,看起来Flink作业由于容器超出了物理内存限制而失败。这可能是由于以下几个原因之一导致的:
此外,还可以采取以下步骤来进一步定位问题所在:
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


