
在机器学习PAI用的逻辑回归这一步会报错是因为什么?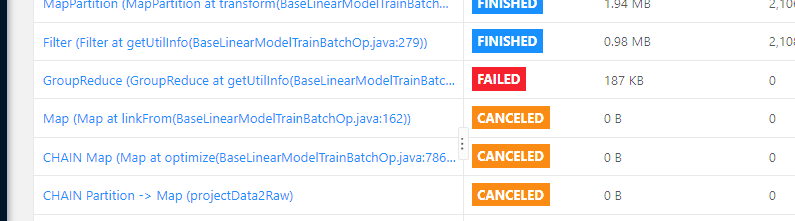
org.apache.flink.runtime.JobException: Recovery is suppressed by NoRestartBackoffTimeStrategy
at org.apache.flink.runtime.executiongraph.failover.flip1.ExecutionFailureHandler.handleFailure(ExecutionFailureHandler.java:138) ~[flink-dist_2.11-1.13.1.jar:1.13.1]
at org.apache.flink.runtime.executiongraph.failover.flip1.ExecutionFailureHandler.getFailureHandlingResult(ExecutionFailureHandler.java:82) ~[flink-dist_2.11-1.13.1.jar:1.13.1]
at org.apache.flink.runtime.scheduler.DefaultScheduler.handleTaskFailure(DefaultScheduler.java:207) ~[flink-dist_2.11-1.13.1.jar:1.13.1]
at org.apache.flink.runtime.scheduler.DefaultScheduler.maybeHandleTaskFailure(DefaultScheduler.java:197) ~[flink-dist_2.11-1.13.1.jar:1.13.1]
at org.apache.flink.runtime.scheduler.DefaultScheduler.updateTaskExecutionStateInternal(DefaultScheduler.java:188) ~[flink-dist_2.11-1.13.1.jar:1.13.1]
at org.apache.flink.runtime.scheduler.SchedulerBase.updateTaskExecutionState(SchedulerBase.java:677) ~[flink-dist_2.11-1.13.1.jar:1.13.1]
at org.apache.flink.runtime.scheduler.SchedulerNG.updateTaskExecutionState(SchedulerNG.java:79) ~[flink-dist_2.11-1.13.1.jar:1.13.1]
at org.apache.flink.runtime.jobmaster.JobMaster.updateTaskExecutionState(JobMaster.java:435) ~[flink-dist_2.11-1.13.1.jar:1.13.1]
at sun.reflect.GeneratedMethodAccessor20.invoke(Unknown Source) ~[?:?]
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[?:1.8.0_381]
at java.lang.reflect.Method.invoke(Method.java:498) ~[?:1.8.0_381]
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcInvocation(AkkaRpcActor.java:305) ~[flink-dist_2.11-1.13.1.jar:1.13.1]
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:212) ~[flink-dist_2.11-1.13.1.jar:1.13.1]
at org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:77) ~[flink-dist_2.11-1.13.1.jar:1.13.1]
at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleMessage(AkkaRpcActor.java:158) ~[flink-dist_2.11-1.13.1.jar:1.13.1]
at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:26) [flink-dist_2.11-1.13.1.jar:1.13.1]
at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:21) [flink-dist_2.11-1.13.1.jar:1.13.1]
at scala.PartialFunction$class.applyOrElse(PartialFunction.scala:123) [flink-dist_2.11-1.13.1.jar:1.13.1]
at akka.japi.pf.UnitCaseStatement.applyOrElse(CaseStatements.scala:21) [flink-dist_2.11-1.13.1.jar:1.13.1]
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:170) [flink-dist_2.11-1.13.1.jar:1.13.1]
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171) [flink-dist_2.11-1.13.1.jar:1.13.1]
at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171) [flink-dist_2.11-1.13.1.jar:1.13.1]
at akka.actor.Actor$class.aroundReceive(Actor.scala:517) [flink-dist_2.11-1.13.1.jar:1.13.1]
at akka.actor.AbstractActor.aroundReceive(AbstractActor.scala:225)
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您提供的报错信息,org.apache.flink.runtime.JobException: Recovery is suppressed by NoRestartBackoffTimeStrategy,结合知识库中的相关资料,可以判断该问题与Flink作业的故障恢复策略有关。具体来说,Flink在任务失败时尝试恢复,但由于配置了NoRestartBackoffTimeStrategy(即不重启策略),导致任务无法自动恢复并最终失败。
以下是可能导致该问题的原因及解决方案:
原因:
Flink默认支持多种故障恢复策略,例如固定间隔重启、指数退避重启等。如果配置了NoRestartBackoffTimeStrategy,则表示任务失败后不会尝试重启,直接终止任务。
解决方案:
修改Flink作业的重启策略,确保在任务失败时能够自动恢复。可以通过以下方式调整:
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 3
restart-strategy.fixed-delay.delay: 10s
restart-strategy: exponential-delay
restart-strategy.exponential-delay.initial-backoff: 10s
restart-strategy.exponential-delay.max-backoff: 60s
restart-strategy.exponential-delay.backoff-multiplier: 2.0
restart-strategy.exponential-delay.reset-backoff-threshold: 5m
flink-conf.yaml文件中添加上述配置,或者通过代码动态设置:StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, Time.seconds(10)));
原因:
如果Flink作业的Checkpoint频繁失败,且未正确配置Checkpoint容忍失败次数(execution.checkpointing.tolerable-failed-checkpoints),可能会导致任务触发Failover并最终失败。
解决方案:
调整Checkpoint相关参数以提高容错能力:
execution.checkpointing.timeout: 10min
execution.checkpointing.tolerable-failed-checkpoints: 3
execution.checkpointing.concurrent-checkpoints: 1
原因:
如果逻辑回归模型的State数据过大(例如单个Key对应的State超过2GB),可能会导致内存溢出(OOM)或临时数组申请失败,从而引发任务失败。
解决方案:
原因:
如果逻辑回归任务依赖自定义连接器,但连接器未正确上传到OSS,可能会导致任务启动失败。
解决方案:
确保自定义连接器已正确上传到OSS,并在作业配置中指定连接器路径。具体操作请参考[管理自定义连接器]。
原因:
根据知识库中的其他案例,可能存在以下问题:
INPUT_FORMAT_ERROR)。Parse exception - invalid token)。解决方案:
json.dumps将数据序列化为字符串。Boolean、Bigint、Double、String、Datetime五种数据类型,建议提前进行类型转换或过滤。优先检查故障恢复策略:
确保Flink作业配置了合理的重启策略,避免因NoRestartBackoffTimeStrategy导致任务直接终止。
优化Checkpoint配置:
增加Checkpoint超时时长和容忍失败次数,确保任务在Checkpoint失败时能够继续运行。
排查State数据问题:
如果State数据过大,建议优化窗口大小或调整作业逻辑。
验证输入数据格式:
确保输入数据符合逻辑回归模型的要求,避免因数据格式或类型问题导致任务失败。
通过以上步骤,您可以有效解决Recovery is suppressed by NoRestartBackoffTimeStrategy报错问题。如果问题仍未解决,请提供更多上下文信息以便进一步分析。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
人工智能平台 PAI(Platform for AI,原机器学习平台PAI)是面向开发者和企业的机器学习/深度学习工程平台,提供包含数据标注、模型构建、模型训练、模型部署、推理优化在内的AI开发全链路服务,内置140+种优化算法,具备丰富的行业场景插件,为用户提供低门槛、高性能的云原生AI工程化能力。

