有没有大佬用flink计算过历史累计数据?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
有的。Flink是一个实时计算引擎,常用于处理数据流并进行实时分析。然而,它也可以用来处理历史累计数据。
例如,在一些业务场景中,可能需要计算用户从注册以来的累计跑步里程,或者其他类型的累计数据。这类数据可以实时更新,每次有新的记录产生时,都可以通过Flink进行计算并更新累计值。
在具体实现上,可以利用Flink的状态管理机制来保存每个用户的累计数据。当新的数据流入时,Flink可以读取之前保存的状态,加上新的数据,然后更新状态。这样,就可以实时地计算出每个用户的累计数据。
需要注意的是,处理历史累计数据可能会涉及到数据的一致性和准确性问题。因此,在设计和实现时,需要仔细考虑这些问题,并采取相应的措施来保证数据的正确性。
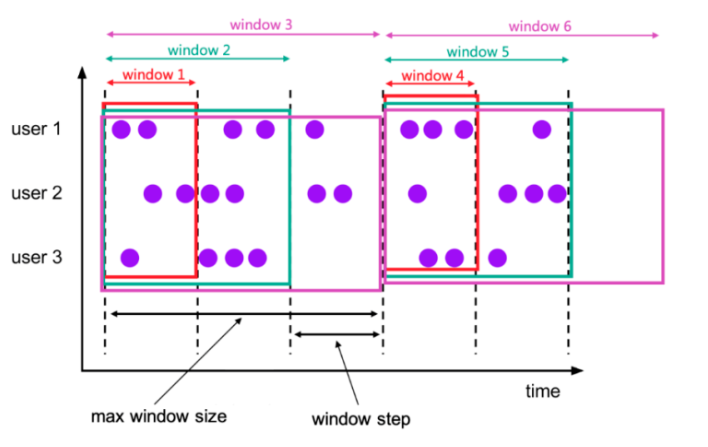
是的,Apache Flink可以用来计算历史累计数据。在处理流式数据时,Flink提供了窗口(Window)机制,可以通过时间窗口、滑动窗口、会话窗口等方式对历史数据进行累积计算。
例如,如果你想要计算每个小时内的用户点击量累计值,可以定义一个基于时间窗口的流处理作业,每个小时作为一个窗口,然后在窗口上应用sum操作来得到累计点击量。
以下是一个简单的示例代码:
DataStream<UserClick> clicks = ... // 获取原始点击事件流
// 定义时间窗口为1小时
WindowedStream<UserClick, String, TimeWindow> windowedStream = clicks
.keyBy(UserClick::getUserID) // 按照用户ID分组
.timeWindow(Time.hours(1)); // 定义1小时窗口
// 计算每个窗口内用户的点击量累计值
DataStream<Tuple2<String, Long>> counts = windowedStream
.sum(1); // 对第二个字段(假设是点击数字段)求和
counts.print().setParallelism(1); // 打印结果
这段代码会对每个小时内每个用户的点击数进行累加,并输出结果。
是的,Apache Flink 是一个流处理框架,可以用于处理历史累计数据。在 Flink 中,可以使用窗口函数(Window Functions)来对历史累计数据进行计算。
窗口函数允许您将数据分成时间窗口或计数窗口,并在每个窗口上执行聚合操作。例如,您可以使用时间窗口函数来计算过去一小时内的累计销售额,或者使用计数窗口函数来计算每个用户的累计订单数。
以下是一个使用 Flink 计算历史累计数据的示例代码:
java
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
public class AccumulateData {
public static void main(String[] args) throws Exception {
// 设置执行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 读取数据流
DataStream<Tuple2<String, Integer>> dataStream = env.readTextFile("input/data")
.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
String[] fields = value.split(",");
return new Tuple2<>(fields[0], Integer.parseInt(fields[1]));
}
});
// 计算历史累计数据
DataStream<Tuple2<String, Integer>> accumulateData = dataStream
.keyBy(0) // 按键分组
.timeWindow(Time.minutes(5)) // 定义时间窗口为5分钟
.reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {
return new Tuple2<>(value1.f0, value1.f1 + value2.f1);
}
});
// 输出结果到文件
accumulateData.writeAsText("output/result");
// 执行任务
env.execute("Accumulate Data Example");
}
}
在上面的示例中,我们使用 readTextFile 方法从文件中读取数据流,然后通过 map 函数将每行数据解析为 Tuple2 对象。接下来,我们使用 keyBy 方法按键进行分组,并使用 timeWindow 方法定义时间窗口为5分钟。最后,我们使用 reduce 函数计算每个窗口内的累计数据,并将结果输出到文件中。
Flink 可以用于计算历史累计数据。历史累计数据指的是在数据流中对过去所有的输入数据进行聚合计算,而不仅仅是当前时间窗口内的数据。
在 Flink 中,可以使用状态来维护历史累计数据。Flink 提供了不同类型的状态,例如键控状态(Keyed State)和操作符状态(Operator State),可以根据具体需求选择适合的状态类型。
以下是一个示例,展示如何在 Flink 中计算历史累计数据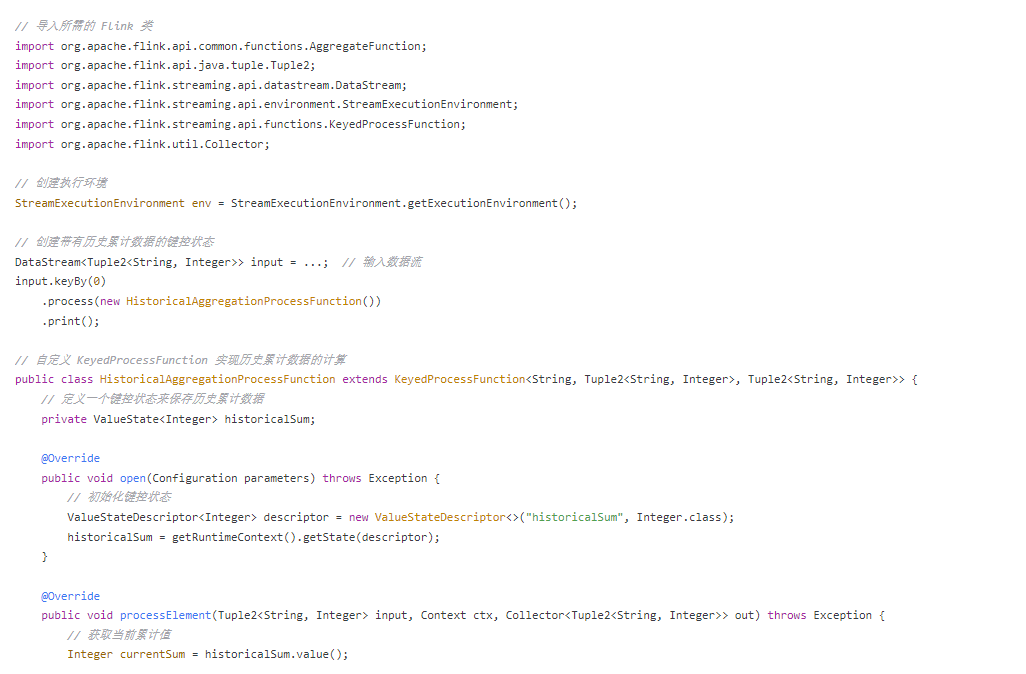

在上述示例中,我们使用 KeyedProcessFunction 来实现历史累计数据的计算。在 open() 方法中初始化键控状态,然后在 processElement() 方法中更新历史累计值,并发送包含历史累计值的输出。
上述示例仅演示了一种基本的方式来计算历史累计数据
是的,可以使用Apache Flink来计算历史累计数据。Flink是一个流处理和批处理的开源框架,它可以处理大规模数据并支持实时计算。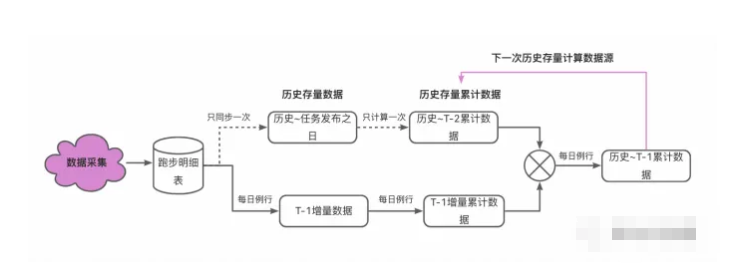
在处理历史累计数据时,你可以使用Flink的窗口函数来对数据进行分组和聚合。例如,你可以根据时间戳将数据分成不同的窗口,并在每个窗口内计算累计值。
以下是一个简单的示例代码,展示如何使用Flink来计算历史累计数据:
java
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
public class HistoryAggregation {
public static void main(String[] args) throws Exception {
// 创建流处理环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 读取数据源
DataStream<Tuple2<Long, Integer>> dataStream = env.addSource(new DataSource());
// 使用时间窗口计算历史累计数据
DataStream<Tuple2<TimeWindow, Integer>> windowedStream = dataStream
.timeWindow(Time.minutes(5))
.reduce(new ReduceFunction<Tuple2<Long, Integer>>() {
@Override
public Tuple2<Long, Integer> reduce(Tuple2<Long, Integer> value1, Tuple2<Long, Integer> value2) throws Exception {
return new Tuple2<>(value1.f0, value1.f1 + value2.f1);
}
});
// 输出结果
windowedStream.print();
// 执行任务
env.execute("History Aggregation");
}
}
在上面的示例中,我们使用了Flink的流处理环境来创建一个数据流,并使用时间窗口对数据进行分组和聚合。在每个时间窗口内,我们使用reduce函数来计算累计值。最后,我们将结果打印出来。
请注意,这只是一个简单的示例,实际应用中可能需要更复杂的逻辑和数据处理流程。但是,这个示例可以为你提供一些关于如何使用Flink来计算历史累计数据的启示。
是的,确实有很多开发者使用Apache Flink来计算历史累计数据。Flink作为一个流处理和批处理统一的计算引擎,能够很好地处理实时和历史数据的累积统计问题。在处理历史累计数据时,你可以利用以下几个关键特性:
事件时间和处理时间窗口:
SELECT
TUMBLE_START(event_time, INTERVAL '1' HOUR) as window_start,
COUNT(*) OVER (PARTITION BY key ORDER BY event_time ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) as cumulative_count
FROM
input_stream
GROUP BY
key,
TUMBLE(event_time, INTERVAL '1' HOUR);
上述SQL示例展示了如何在事件时间窗口上做累计计数。
全局窗口(Global Window):
SELECT
key,
SUM(amount) OVER (PARTITION BY key ORDER BY event_time ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) as cumulative_sum
FROM
input_stream
GROUP BY
TUMBLE(event_time, INTERVAL '1' DAY),
key;
虽然上面的SQL没有直接使用全局窗口,但它实现了累计求和的效果,全局窗口可以用在不需要划分窗口的场景。
状态管理:
Table API和SQL:
Checkpoint与Savepoint:
使用Flink计算历史累计数据是非常可行且高效的,具体实现取决于业务需求和技术选型。通过合理设计窗口策略、状态管理和SQL查询,可以实现复杂的累计统计场景。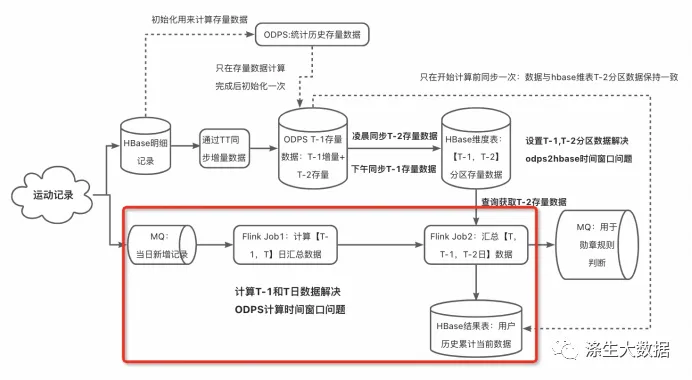

当然,Apache Flink 是一个强大的流处理框架,可以用来处理历史和实时数据。以下是一个简单的示例,展示如何使用 Flink 来计算历史累计数据。
假设我们有一个数据流,每个元素是一个包含时间戳和数值的元组,我们想要计算每个时间窗口内的历史累计值。
首先,确保你已经设置了 Flink 的环境。然后,你可以使用以下代码:

这个示例展示了如何使用 Flink 的 timeWindow 和 reduce 操作来计算历史累计数据。注意,keyBy 操作用于将数据按时间进行分组,而 reduce 操作用于在每个时间窗口内计算累积值。最后,我们使用 print 操作将结果输出到控制台。
Apache Flink 提供了一种叫做累加器(Accumulator)的功能,它可以让你轻松地计算历史累计数据。累加器是一种特殊的聚合器,它的作用类似于滑动窗口里的累积器,只是它是全局性的,不会受到窗口大小的限制。
下面是如何使用累加器的例子:
import org.apache.flink.api.common.functions.AggregateFunction
class SumAccumulator extends AggregateFunction[Int] {
private var sum: Int = 0
override def create(): Int = {
return 0
}
override def append(value: Int): Unit = {
this.sum += value
}
override def merge(otherValue: Int): Int = {
if (otherValue < 0)
throw new IllegalArgumentException("Negative values not allowed")
else
return this.sum + otherValue
}
override def getResult(): Int = {
return this.sum
}
}
val stream = ... // your data source here
stream.map(new SumAccumulator())
在这段代码中,我们定义了一个SumAccumulator类作为累加器,继承于AggregateFunction接口。在累加器内部,我们维护了一个sum变量,每当接收到一条新的元素时,我们就将其加上这条元素的值。merge方法则实现了累加的过程,即将当前的sum加上新的元素值。最后,getResult方法返回的就是累加的结果。
请注意,累加器只适用于数值类型的数据,不能用于字符串和其他非数值类型的对象。
是的,Flink可以用于计算历史累计数据。Flink提供了流处理和批处理两种模式,可以根据实际需求选择适合的模式进行数据处理。
在流处理模式下,Flink可以实时地处理数据流,并支持窗口操作、滑动窗口等聚合操作,可以方便地计算历史累计数据。例如,可以使用Flink的Windowed Stream API对数据流进行窗口化处理,然后使用聚合函数(如SUM、AVG等)计算每个窗口内的累计数据。
在批处理模式下,Flink可以将数据流转换为批处理数据,然后使用批处理算法进行数据处理。这种方式适用于需要对大量历史数据进行处理的场景,但计算效率可能不如流处理模式高。
总之,Flink可以用于计算历史累计数据,具体选择哪种模式取决于实际需求和场景。
是的,Flink 支持计算历史累计数据。在 Flink 中,您可以使用 Window 函数来处理时间序列数据,并计算历史累计数据。Window 函数可以对数据进行分组、排序、聚合等操作,非常适合计算累计数据。以下是一个使用 Flink Window 函数计算历史累计数据的示例:
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.java.tuple.Tuple2;
public class historicalCumulativeData {
public static void main(String[] args) throws Exception {
// 创建一个 DataStream 对象,用于接收数据
DataStream dataStream = ...;
// 定义一个窗口,每隔一段时间计算累计数据
windows.TimeWindow> window = windows.time(Time.seconds(5));
// 使用 Window 函数计算历史累计数据
DataStream> cumulativeData = dataStream
.keyBy(x -> x)
.window(window)
.apply(new AggregateFunction, Integer>() {
@Override
public Integer createAccumulator() {
return 0;
}
@Override
public Integer add(Integer value, Integer accumulator) {
return accumulator + value;
}
@Override
public Tuple2 getResult(Integer accumulator) {
return new Tuple2<>(accumulator, accumulator);
}
@Override
public void merge(Tuple2 a, Tuple2 b) {
a.f0 += b.f0;
a.f1 += b.f1;
}
});
// 输出历史累计数据
cumulativeData.print();
// 启动 Flink 作业
dataStream.start();
}
}
在这个示例中,我们首先创建了一个 DataStream 对象,用于接收数据。然后,我们定义了一个 TimeWindow 对象,用于指定窗口大小。接下来,我们使用 keyBy 方法对数据进行分组,并使用 window 方法将数据划分为窗口。最后,我们使用 apply 方法在窗口上计算历史累计数据。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。