
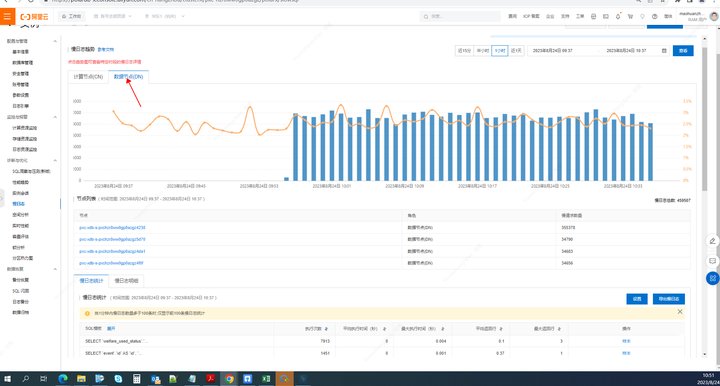
PolarDB-X存储层很多慢SQL计算层应该怎么设置,存储层看都是分表?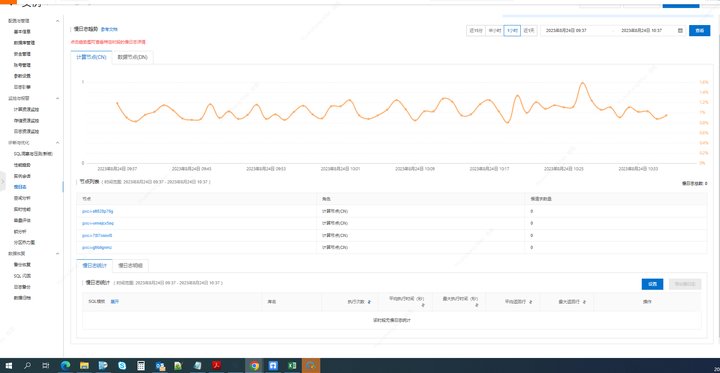
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
PolarDB-X存储层和计算层的设置取决于您的业务需求和数据量。一般来说,如果您的业务对查询性能要求较高,可以考虑在计算层进行分区,以提高查询性能。如果您的业务对写入性能要求较高,可以考虑在存储层进行分区,以提高写入性能。
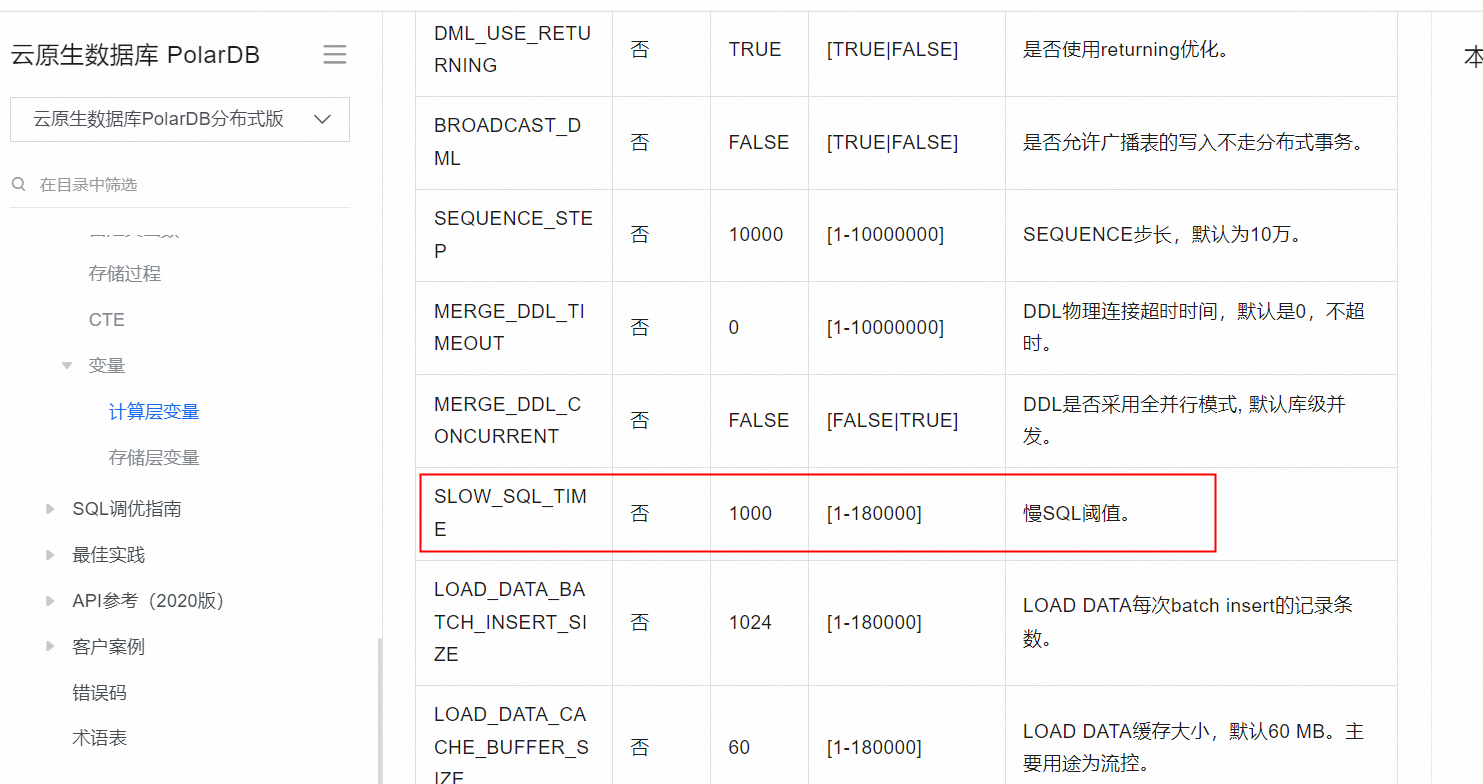
此外,您还可以通过调整PolarDB-X的参数来优化查询性能。例如,您可以调整参数max_result_size来控制查询结果的大小,以减少查询时间。您还可以调整参数max_connections来控制并发连接的数量,以提高查询性能。
PolarDB-X是一个分布式数据库系统,由计算层和存储层组成。针对慢SQL和计算层设置,可以采取以下措施: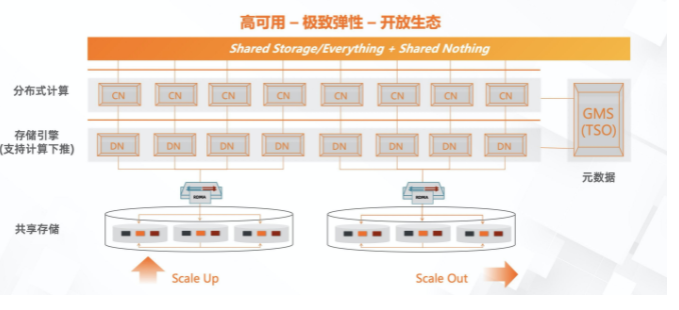
优化SQL查询语句:首先,确保SQL查询语句是正确的,并且具有高效的执行计划。这可以通过使用合适的索引、调整查询条件和排序方式等方式实现。
调整计算节点配置:PolarDB-X的计算节点负责处理SQL查询请求。你可以根据实际需求调整计算节点的CPU、内存和磁盘资源,以提高查询处理性能。
分表设计:在存储层,分表是一种常见的优化方法,可以提高查询性能和并发处理能力。你可以根据业务需求和数据特点进行分表设计,包括垂直分表和水平分表。
垂直分表:将表中的列拆分为多个较小的表,每个表只包含一部分列。这可以减少单个查询涉及的数据量,提高查询速度。
水平分表:将表中的行拆分为多个较小的表,每个表只包含一部分行。这可以减少单个查询涉及的数据量,提高查询速度。
分布式缓存:PolarDB-X支持分布式缓存,可以将经常访问的数据缓存到内存中,减少磁盘I/O操作,提高查询速度。你可以根据实际需求配置缓存策略和缓存大小。
数据压缩:使用数据压缩技术可以减少存储空间的使用,并提高数据读取速度。PolarDB-X支持多种数据压缩算法,可以根据实际需求选择合适的压缩算法。
监控与调优:定期监控数据库的性能指标,如CPU使用率、内存使用率、磁盘I/O等。根据监控数据,可以进一步调整计算节点配置、分表设计和其他相关参数,以获得更好的性能表现。
请注意,以上措施只是一些常见的优化方法,具体的设置取决于你的业务需求、数据量和硬件资源。建议在进行优化前先进行备份和测试,以避免对生产环境造成影响。
楼主你好,针对阿里云PolarDB-X存储层的慢SQL和计算层,可以考虑以下设置:
慢SQL:可以通过阿里云PolarDB-X提供的慢日志功能来分析和优化慢SQL的执行效率,或者通过SQL优化工具进行优化。
计算层:可以通过使用PolarDB-X的分布式计算引擎,如PolarDB-X Analytics(对常用函数进行了优化)、Presto(支持大量非结构化数据)、MaxCompute(用于数据仓库和大数据分析)、Spark(支持批处理和流计算)等,来加速查询和计算。
存储层:可以考虑进行分表分库来缓解存储层的读写负载。此外,可以根据业务需求进行数据拆分和数据冗余等操作,提高查询效率和系统的可用性。
需要注意的是,以上设置需要考虑到业务需求、系统性能和数据完整性等多个因素,建议在实际应用中进行测试和优化。
查询优化:在编写 SQL 查询语句时,尽量减少 SELECT *,只查询需要的字段;避免使用子查询、临时表等可能导致性能下降的操作
针对 PolarDB-X 存储层中的慢 SQL,计算层可以采取以下几种方法进行优化:
PolarDB-X是阿里云提供的一种新一代云原生数据库产品,它采用了分布式存储和计算的架构。在PolarDB-X中,存储层和计算层是分离的,存储层负责数据的持久化存储,而计算层负责数据的查询和计算。
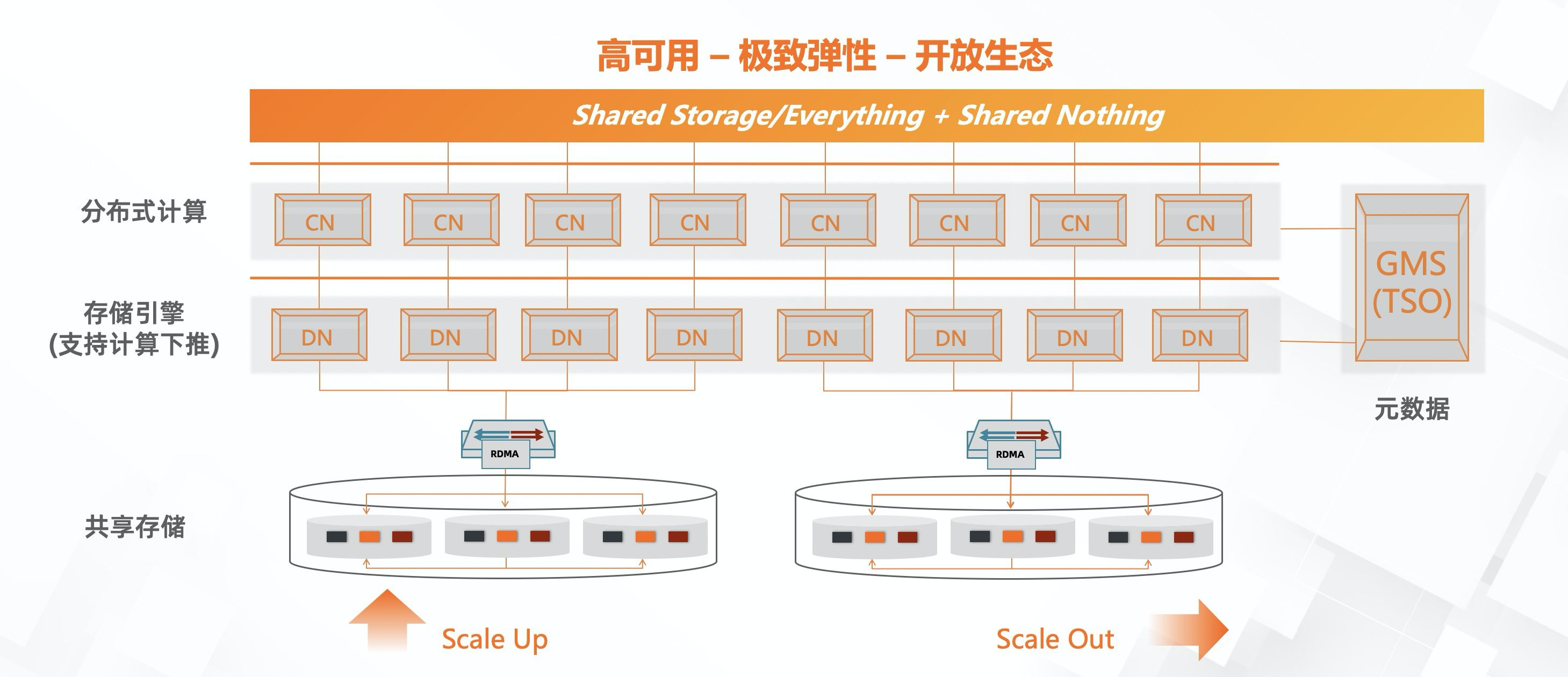
对于慢SQL的优化,可以从两个方面进行设置:
存储层设置:存储层可以通过合理的分表策略和索引设计来优化慢SQL的性能。根据业务需求和数据量的大小,可以将数据按照一定的规则进行分表,将数据均匀地分布在不同的存储节点上,从而提高查询的并发性能。同时,合理的索引设计可以加速查询过程。
计算层设置:计算层可以通过调整查询计划、优化查询语句等方式来提高慢SQL的执行效率。可以使用查询优化器来选择最优的执行计划,避免全表扫描和不必要的数据传输。此外,还可以考虑使用缓存、预热等技术来提高查询的响应速度。
总结起来,针对慢SQL的优化,需要综合考虑存储层和计算层的设置。存储层要合理设计分表和索引,计算层要优化查询计划和查询语句。此外,可以根据具体情况选择合适的硬件配置和调整系统参数来提高整体性能。
在分析慢SQL之前,需要先了解SQL的执行过程。一条SQL的执行共涉及到三层,包含两次网络数据交换:客户端到计算节点(CN)、计算节点到数据节点(DN)。

执行过程示意图说明:
橘色部分为不可下推的SQL语句的执行流程,包括解析优化到调度执行两大步骤。
浅绿色部分为可以下推的SQL语句的执行流程,主要过程是将数据节点(DN)的数据进行扫描和计算,并将数据通过私有远程过程调用协议RPC(Remote Procedure Call Protocol)返回给上层计算节点继续做计算。
结合PolarDB-X数据库的原理和SQL语句的执行过程,发现影响SQL语句执行效率的主要因素包括:
数据量
SQL执行后返回给客户端的数据量的大小;
DN层数据量越大需要扫描的I/O次数越多,DN节点的IO更容易成为瓶颈。
取数据的方式
数据在缓存中还是在磁盘上;
是否能够通过DN上的全局索引快速寻址;
是否结合谓词条件命中全局索引加速扫描。
数据加工的方式
排序、子查询、聚合、关联等,一般需要先把数据取到临时表中,再对数据进行加工;
对于数据量比较多的计算,会消耗大量计算节点的CPU资源,让数据加工变得更加缓慢;
是否选择了合适的关联算法。
优化思路
将数据存放在更快的地方
某条查询涉及到大表,无法进一步优化,如果返回的数据量不大且变化频率不高但访问频率很高,此时应该考虑将返回的数据放在应用端的缓存当中或者Redis这样的缓存当中,以提高存取速度。
关联操作尽量将计算下推
如果业务大部分都是大表关联操作,那么尽可能设计合理的分片策略。将分片的Key与关联条件的Join Key对齐,PolarDB-X就会把这部分关联操作转化成可下推的物理SQL下推,避免单表扫描带来的压力;
如果涉及到的慢SQL是典型的大小表关联,并且小表的数据为量不大且变化频率不高的,那么可以把小表做成广播表,这样任何表和广播表做关联,都会被优化成可下推的物理SQL;
如果关联涉及到的表分片策略无法变更,可以以Join Key为表创建全局二级索引,这样关联操作可以下推,在DN的索引表上做关联。
减少数据扫描
尽量在查询中加入一些可以提前过滤数据的谓词条件,比如按照时间过滤数据等,可以减少数据的扫描量,对查询更友好;
在扫描大表数据时是否可以命中索引,减少回表代价,避免全表扫描。
执行计划中选择更合理的数据加工算法
例如关联算法有HashJoin、SortMergeJoin、BkaJoin等,每种关联算法都有特定的场景,执行计划选择不合理,会影响到查询代价。
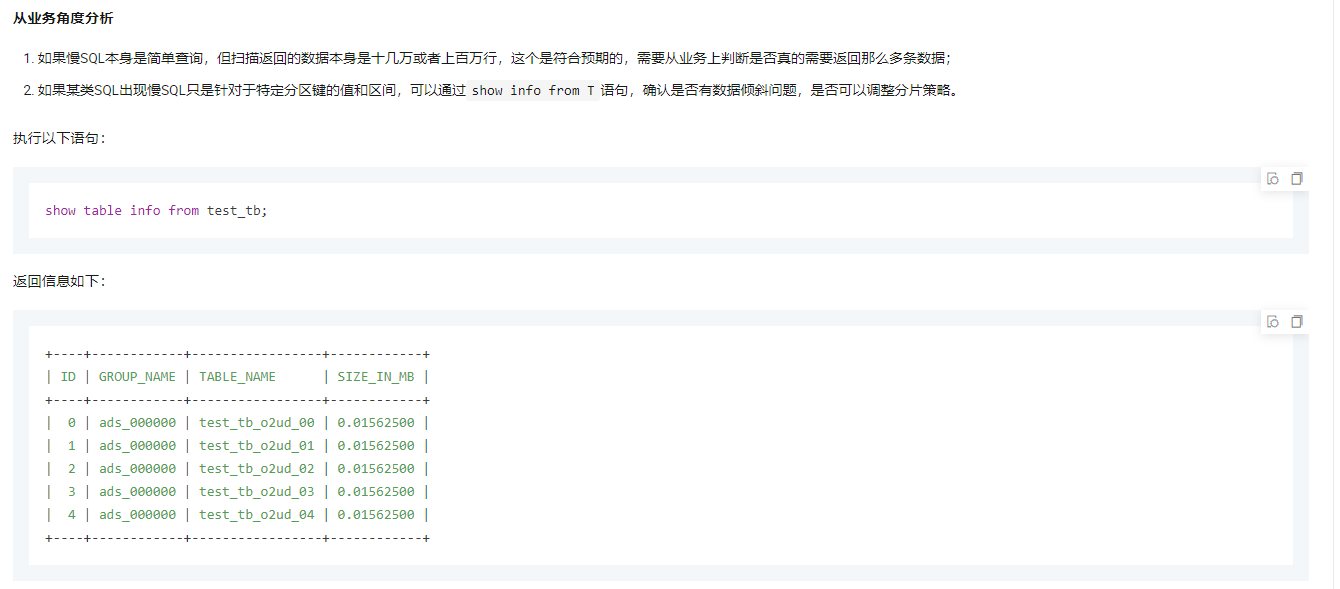
如果您在 PolarDB-X 存储层遇到了慢 SQL 计算问题,可以尝试以下方法:
分析慢 SQL:使用 PolarDB-X 的慢 SQL 分析器,分析慢 SQL 的执行计划和执行情况,找出问题所在。
调整存储层参数:根据具体情况调整存储层的参数设置,例如调整索引策略、调整分区策略等。
调整计算层参数:根据具体情况调整计算层的参数设置,例如调整并行度、调整查询缓存等。
优化索引:对表中的索引进行优化,例如添加合适的索引、删除不必要的索引等。
优化查询语句:对查询语句进行优化,例如使用精确的过滤条件、避免不必要的连接和子查询等。
需要注意的是,在优化 PolarDB-X 存储层时,需要根据具体情况进行分析和排查,并逐一排除可能的原因。同时,您还需要定期备份数据和更新软件,以确保数据的安全性和隐私性。
PolarDB 分布式版 (PolarDB for Xscale,简称“PolarDB-X”) 采用 Shared-nothing 与存储计算分离架构,支持水平扩展、分布式事务、混合负载等能力,100%兼容MySQL。 2021年开源,开源历程及更多信息访问:OpenPolarDB.com/about


