
seata 开启全局事务rpc通讯超时怎么办?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
当您在使用Seata开启全局事务时遇到RPC通讯超时的问题,可以通过调整Seata的配置文件来解决。具体来说,需要设置seata-rpc-timeout参数,这个参数就是用来设定全局的RPC请求超时时间。
需要注意的是,seata-rpc-timeout和Feign等其他框架的超时机制是不同的,因此在实际使用时需要区别对待。此外,如果出现分支事务异步执行而全局事务无法感知其进度,导致全局事务长时间未能完成的情况,这属于Seata框架层面的正常处理,用户需要在自身业务层面寻求解决方案。
楼主你好,当阿里云Seata开启全局事务时,RPC通讯超时可能会发生,这种情况下,你可以增加RPC超时时间,直接在Seata的配置文件中找到相关的配置项,如seata.client.rm.async.commit.buffer.limit和seata.client.rm.lock.retry.internal等,适当增加其值来延长RPC超时时间。
还有就是如果Seata服务器负载过高,也可能导致RPC通讯超时,你可以增加Seata服务器的资源或者使用负载均衡策略来避免过度负载。
Seata 允许你配置 RPC 请求的超时时间。如果默认超时时间太短,网络稍微有点慢就可能导致超时。可以尝试在配置文件中增加超时时间设置。例如,在 file.conf 中的 client 配置部分调整 rm 和 tm 的超时时间:
client {
rm {
reportSuccessEnable = "true"
tableMetaCheckEnable = "false"
asyncCommitBufferLimit = "10000"
lock {
retryInterval = "10"
retryTimes = "30"
retryPolicyBranchRollbackOnConflict = "true"
}
reportRetryCount = "5"
tableMetaCheckerInterval = "60000"
}
tm {
commitRetryCount = "5"
rollbackRetryCount = "5"
}
undo {
logSerialization = "jackson"
logTable = "undo_log"
}
log {
exceptionRate = "100"
}
}
调整 client.rm.reportRetryCount、client.tm.commitRetryCount 和 client.tm.rollbackRetryCount 的值来增加重试次数,或者调整其他相关的超时设置。
当在Seata中开启全局事务并遇到RPC通讯超时问题时,可以尝试以下解决方法:
检查网络连接:确保Seata服务器和客户端之间的网络连接稳定,没有网络延迟或丢包等问题。
调整超时时间:在Seata的配置文件中,可以设置相关的超时时间参数。适当增加超时时间,以给RPC调用更多的响应时间。
检查服务端性能:如果服务端处理请求的速度较慢,可能导致RPC通讯超时。可以检查服务端的CPU、内存、磁盘等资源使用情况,并进行相应的优化。
增加重试机制:在客户端和服务器端增加重试机制,当RPC调用失败时,可以自动重试,提高系统的容错能力。
检查日志信息:查看Seata的日志信息,找出可能存在的错误或异常,并根据日志中的信息进行故障排查。
更新版本:如果你使用的Seata版本存在bug或不稳定,可以尝试更新到最新版本,以解决RPC通讯超时问题。
要具体看下Seata和RPC客户端的日志,才能更好定位问题,如果网络和代码逻辑没有问题,可以调整下超时时间(因为Seata的默认事务超时时间较短),具体配置: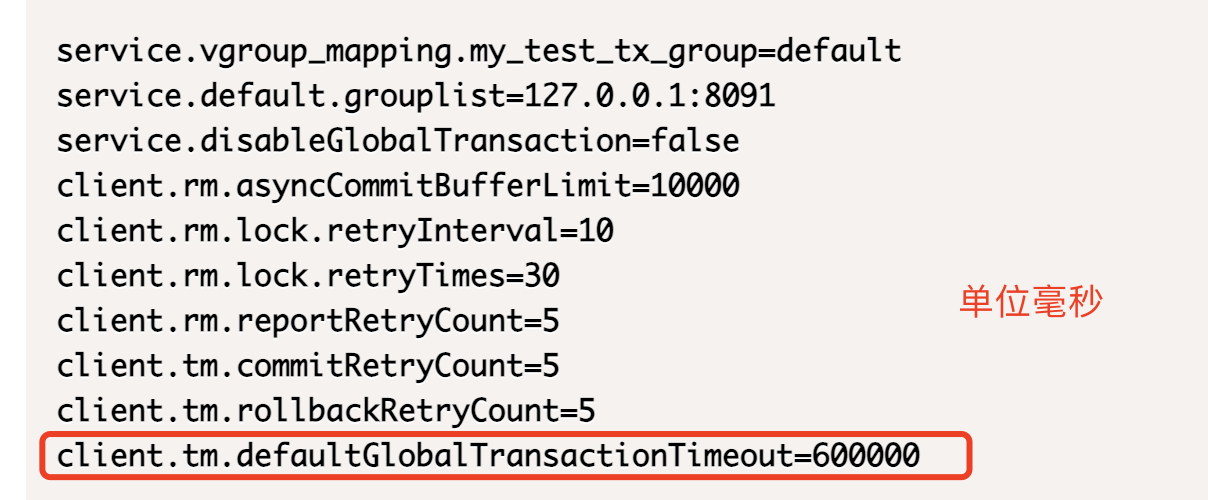
当遇到Seata开启全局事务RPC通讯超时的问题,首先需要理解seata-rpc-timeout和Feign的超时机制是不同的。seata-rpc-timeout是Seata中用于设置全局的RPC请求超时时间,可以通过配置文件进行设置,它负责控制分布式事务的超时时间。而Feign的超时机制是指在调用远程服务时,设置一个超时时间,如果在规定的时间内没有得到响应,则会抛出超时异常,这个超时时间是针对单个接口调用的。
seata-rpc-timeout的超时可能由多种原因引起,并发和网络抖动是其中的一种常见情况。当系统并发量较高或网络质量不稳定时,可能会导致RPC请求在Seata中的超时。这通常意味着某些分布式事务参与者无法及时响应请求,从而触发了超时。
关于如何处理这个问题,Seata的默认全局事务超时时间是1分钟,当Seata-server检测到有超时的全局事务时,会向所有已提交的分支发起回滚。同样地,如果超时提交的事务向Seata-server发起分支注册时,响应结果为事务已超时或者事务不存在,也会回滚本地事务。因此,如果你发现全局事务处于超时回滚中的状态,请排查为何业务无法在限定时间内完成事务。若确实无法完成,应调大全局事务超时时间。如果一切正常,还需要检查tc集群时区与数据库是否一致,若不一致请改为一致。
(内容由讯飞星火AI生成)
当Seata的全局事务RPC通信超时时,你可以尝试检查网络连接确保Seata Server和客户端之间的网络连接正常,如果存在网络故障或延迟,可能导致通信超时。你可以通过检查网络连接、ping测试等方法来确认网络是否正常。调整超时时间配置,可以在Seata的配置文件中调整全局事务RPC的超时时间配置。在Seata Server的application.properties文件中,可以修改以下相关配置:
seata.fescar.rm.config.connect-timeout: 调整与TC(事务协调器)建立连接的超时时间。seata.fescar.rm.config.async-commit-buffer-limit: 调整异步提交缓冲区的限制大小。增加Seata Server的资源,如果你的系统并发量较高或者负载较重,可以考虑增加Seata Server的资源,例如增加CPU、内存或者优化数据库连接池等操作,以提高Seata Server的性能和稳定性。检查Seata Server日志,你可以查看Seata Server的日志,尤其是对于错误和异常的相关日志,以便更好地定位和解决问题。日志中可能包含有关超时原因的更多信息。
1检查rpc通信的超时时间设置是否过短,比如dubbo的timeout设置等。可以适当延长些。
2优化业务流程,尽量减少一个分支事务的执行时间。如将复杂逻辑拆分成几个小事务。
3检查seata server和业务应用之间的网络环境,是否有延迟或隔离问题导致调用延时。
4设置全局事务的timeout时间比单次rpc调用长一些,留有缓冲期。
可能是由于网络延迟、服务端负载过高、客户端配置不当等原因导致的。以下是一些可能的解决方案:
检查网络连接:确保Seata服务端和客户端之间的网络连接稳定,没有网络故障或延迟。
优化服务端性能:如果服务端负载过高,可能导致RPC通讯超时。可以尝试优化服务端的性能,例如增加服务器资源、优化代码等。
调整客户端配置:检查客户端的Seata配置,特别是关于超时时间的配置。可以根据实际情况调整超时时间,以适应网络环境和服务器性能。
增加重试机制:在客户端和服务端之间增加重试机制,当RPC通讯超时时,可以自动重试,提高事务的可靠性。
检查防火墙和安全组规则:确保防火墙或安全组规则没有阻止Seata服务端和客户端之间的通信。
更新Seata版本:如果使用的是较旧的Seata版本,可以尝试升级到最新版本,因为新版本可能修复了一些已知的问题。
如果Seata开启全局事务的RPC通讯超时,可以尝试以下几种解决方法:
调整seata-server配置文件中的配置项:service.rollback.retry.timeout和service.rollback.retry.interval,增加超时时间和重试间隔时间,以适应网络环境和负载情况。
检查网络连接是否正常,确保Seata Server与其他相关组件之间的网络连接是稳定和可靠的。
检查Seata Server的资源占用情况,例如CPU和内存使用率,如果资源占用过高,可以考虑对Seata Server进行水平扩展,增加实例数量以提升性能。
检查Seata Server的日志,查看是否有具体的报错信息或异常堆栈信息,根据具体的错误进行相应的处理。
超时的原因有很多的原因;首先要进行分析出来具体的原因,然后才能制定解决方案才行。
比如说:如果是并发量导致的超时建议优化接口,减轻服务器的压力。如果是由于网络的不稳定导致的超时,建议增加超时的时间进行处理;如果是由于版本的原因导致的话,建议更新文档的较新的版本。
所有的问题都是有一个最重要的关键问题,如果找到了这个问题的话,就能很快的解决。前期的分析很重要。
当Seata全局事务出现RPC通讯超时问题时,可以尝试以下解决方法:
当Seata全局事务出现RPC通讯超时的问题时,可以尝试以下几种解决方法:
调整全局事务超时时间
可以通过调整 Seata 的配置文件,将全局事务通讯超时时间调整为合适的值。具体操作可以参考 Seata 的官方文档。
增加线程池大小
在 Seata 的应用程序中,可以增加线程池的大小,以增加并发处理能力,从而提高全局事务的通讯效率。
检查网络连接
在 Seata 的应用程序中,需要检查网络连接是否正常,并确保服务器可以正常访问网络。
SEATA 是一种分布式事务解决方案,它支持全局事务和本地事务。当你在使用 SEATA 开启全局事务时,如果遇到 RPC 通讯超时的问题,可能是由以下原因引起的:
网络问题:检查你的网络连接是否正常,确保 SEATA 服务端和客户端之间的网络通信没有问题。
服务端负载过高:如果服务端负载过高,可能导致响应时间过长,引发 RPC 通讯超时。你可以检查服务端的 CPU、内存和磁盘使用情况,并根据需要进行优化。
客户端配置问题:检查客户端的配置是否正确,包括服务器地址、端口号等。确保客户端能够正确连接到服务端。
超时时间设置过短:如果超时时间设置过短,可能导致客户端在等待服务端响应时超时。你可以尝试增加超时时间来解决这个问题。
针对以上问题,你可以尝试以下解决方案:
检查网络连接:确保你的网络连接正常,并且没有任何网络故障或延迟。
优化服务端性能:如果服务端负载过高,你可以考虑优化服务端的性能,包括增加服务器资源、优化代码等。
检查客户端配置:确保客户端的配置正确,包括服务器地址、端口号等。你可以尝试在客户端日志中查看是否有任何错误信息。
增加超时时间:如果超时时间设置过短,你可以尝试增加超时时间来解决这个问题。你可以在客户端的配置文件中设置超时时间。
如果以上解决方案无法解决问题,你可能需要进一步排查问题原因,或者寻求 SEATA 社区或官方技术支持的帮助。
当Seata开启全局事务时,如果RPC通讯超时发生,可以考虑以下几种处理方式:
检查网络连接:首先,需要检查网络连接是否正常。确保所有相关的网络设置和配置正确,并且网络连接稳定。如果网络不稳定或存在问题,可能导致RPC通讯超时。
调整超时设置:可以尝试调整Seata的超时设置,例如增加超时时间或调整超时重试次数。在Seata的配置文件中,可以找到与RPC通讯超时相关的配置项,根据具体情况进行调整。
优化性能和并发:RPC通讯超时可能是由于性能问题或并发量过大导致的。可以通过优化代码、增加服务器资源、调整线程池配置等方式来提高性能和并发处理能力,以防止超时发生。
检查服务提供者:如果RPC通讯超时发生在调用远程服务的过程中,可能是服务提供者的问题。可以检查服务提供者是否正常运行,并且网络连接正常。如果服务提供者有延迟或性能问题,可能导致RPC通讯超时。
日志和监控:可以使用Seata提供的日志和监控功能来获取更多关于超时发生的信息。通过分析日志和监控指标,可以了解具体的超时情况和原因,进一步定位和解决问题。
当出现全局事务RPC通讯超时,可能是由于网络延迟或者服务端处理时间过长导致的。此时,你可以调整Seata的配置来解决这个问题。具体来说,你可以调整seata-rpc-timeout参数,这个参数是Seata中用于设置全局的RPC请求超时时间的。
另一方面,如果发现全局事务一直未能在限定时间内完成,可能会转变为"全局事务超时回滚中"的状态。这是TC中的一个定时任务发现的,它会寻找已超时的全局事务并开始回滚,直到回滚完成为止。在这种情况下,你可能需要检查为何业务无法在限定时间内完成事务,以及是否存在网络问题导致RPC调用超时。如果确实无法在限定时间内完成事务,可以考虑调大全局事务超时时间以避免频繁回滚。同时,也应确保TC集群时区与数据库一致,避免因为时间不同步导致的问题。
SEATA全局事务是一种分布式事务解决方案,用于确保微服务之间的数据一致性。当SEATA全局事务RPC通讯超时时,可能有多种原因导致。以下是一些可能的解决方法:
1、检查网络连接:首先检查SEATA服务之间的网络连接是否正常。如果网络连接不稳定,可能导致RPC通讯超时。
2、调整超时时间:在SEATA中,可以通过配置文件或代码设置超时时间。如果默认的超时时间过短,可能导致RPC通讯超时。可以尝试增加超时时间来解决这个问题。
3、检查服务端负载:如果服务端负载过高,可能导致响应速度变慢,从而导致RPC通讯超时。可以尝试优化服务端的性能或增加服务端的资源来解决问题。
4、检查客户端配置:客户端的配置也可能影响RPC通讯的性能。可以检查客户端的配置,确保它们与服务器端的配置相匹配。
5、更新SEATA版本:如果使用的是较旧的SEATA版本,可能会存在一些已知的问题或bug。可以尝试更新到最新的SEATA版本,以解决可能存在的问题。
如果在使用 Seata 开启全局事务时,RPC 通讯超时,可以尝试以下几种解决方案:
阿里云拥有国内全面的云原生产品技术以及大规模的云原生应用实践,通过全面容器化、核心技术互联网化、应用 Serverless 化三大范式,助力制造业企业高效上云,实现系统稳定、应用敏捷智能。拥抱云原生,让创新无处不在。

