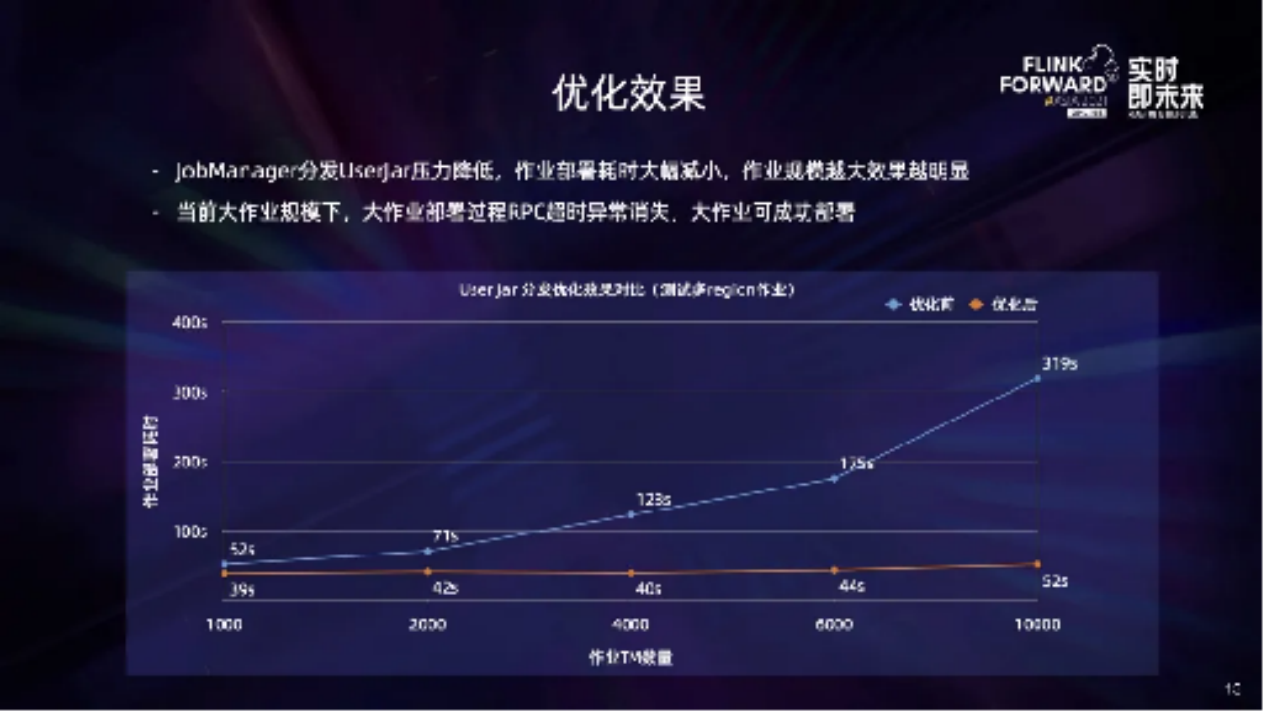
你们是如何解决下游 Task 频繁请求 JobMaster 导致 RPC 超时的问题的?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
为了解决这个问题,我们做了一个简单的优化:下游 Task 在请求 partition 失败时,先自己尝试重试几次,而不是立即请求 JobMaster。通过这个调整,大幅减少了 JobMaster 上 requestPartitionState 的 RPC 请求量,使得 JobMaster 可以有更多时间去处理其他的 RPC 请求,从而避免了 RPC 超时的问题。